
Adrian Nutiu
697 posts


Can’t wait to join the team at @openai building codex. Would love to hear what you love about it or want changed. We’re moving fast. DMs open.
English
Adrian Nutiu retweetledi

Here are all the open weight models that can get close frontier level code, and tie for agentic purposes.
GLM-5.*
MiniMax-M2.*
Kimi-K2.5
Deepseek-V3.2
Qwen-3.5-Plus-397B
If you want AI at home for coding agents similar to Claude/Codex the VRAM needed 192GB for Q4 quant + REAP

English
Adrian Nutiu retweetledi

Announcing: EmDash, the WordPress spiritual successor built for the modern web.
TypeScript. Serverless. MIT licensed. x402 for agent-era monetization. MCP server built in. Deploy to Cloudflare or anywhere Node.js runs.
Imports your existing WordPress site in minutes.
npm create emdash@latest
blog.cloudflare.com/emdash-wordpre…

English

If we made /slow mode in Codex, would you use it? What for?
(Slower inference at a cheaper cost)
English
Adrian Nutiu retweetledi

Adrian Nutiu retweetledi

I wanted to share a bunch of my favorite hidden and under-utilized features in Claude Code. I'll focus on the ones I use the most.
Here goes.
English

introducing the Codex Copilot Cowork Collaborative Connector Collection
English
@patrickstox Isn't the 10 and 25 rows limit for the smaller plans a problem for keyword and link research using the API?
English

In case you missed it, Ahrefs API is now available on Lite and higher plans.
If you couldn't do something with the MCP, now you can just vibe code it and knock it out with the API.
English
@dmwlff Does it slow down a lot compared to dangerously skip permissions due to the fact that it has to check approvals and review for everything?
English

Auto mode has been a total game-changer and become core to how I work with Claude. I can't recommend this feature highly enough.
Claude@claudeai
New in Claude Code: auto mode. Instead of approving every file write and bash command, or skipping permissions entirely, auto mode lets Claude make permission decisions on your behalf. Safeguards check each action before it runs.
English

Adrian Nutiu retweetledi

Adrian Nutiu retweetledi
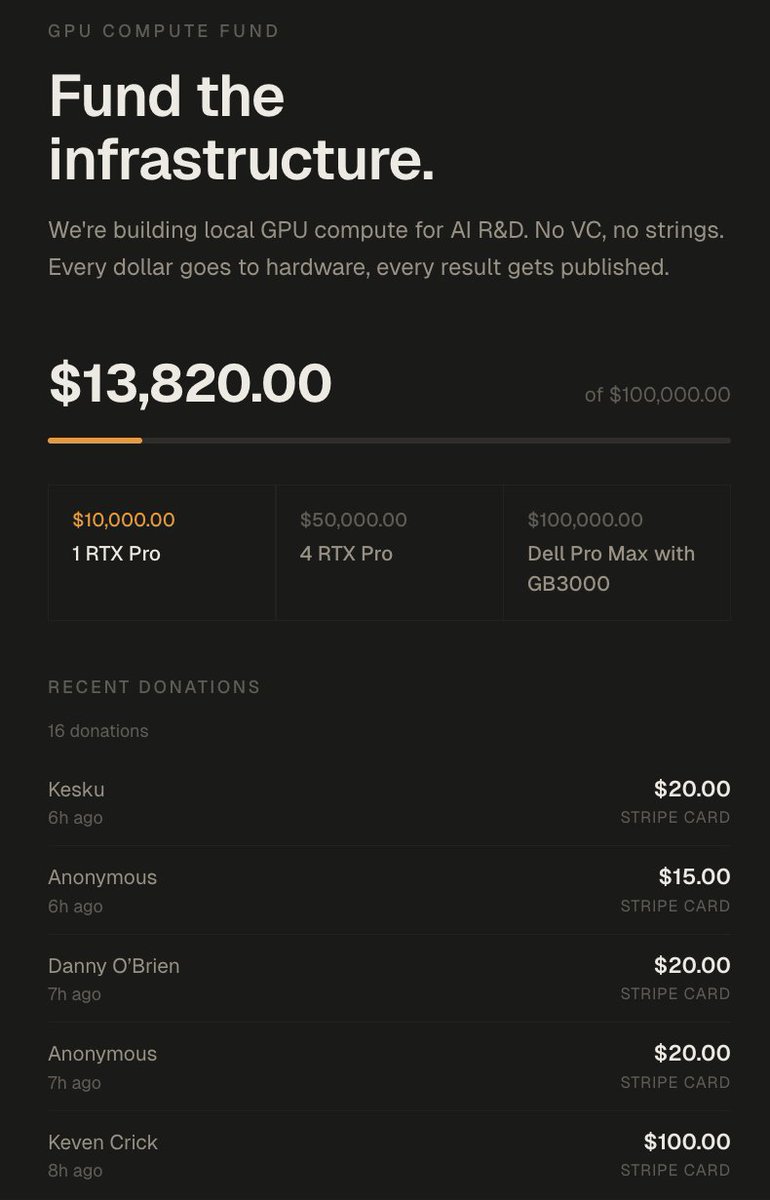
In 72 hours I got over 100k of value
1. Lambda gave me 5000$ credits in compute
2. Nvidia offered me 8x H100s on the cloud (20$/h) idk for how long but assuming 2 weeks that'd be 5000$~
3. TNG technology offered me 2 weeks of B200s which is something like 12000$ in compute
4. A kind person offered me 100k in GCP credits (enough to train a 27B if you do it right)
5. Framework offered to mail me a desktop computer
6. We got 14,000$ in donations which will go to buying 2x RTX Pro 6000s (bringing me up to 384GB VRAM)
7. I got over 6M impressions which based on my RPM would be 1500$ over my 500$~ usual per pay period
8. I have gained 17,000~ followers, over doubling my follower count
9. 17 subscribers on X + 700 on youtube.
The total value of all this approaches at minimum 50,000$~ and closer to 150,000$ if I leverage it all.
---------------------
What I'll be doing with all this:
Eric is an incredibly driven researcher I have been bouncing ideas off of over the last month.
Him and I have been tackling the idea of getting massive models to fit on relatively cheap memory.
The idea is taking advantage of different forms of memory, in combination with expert saliency scoring, to offload specific expert groupings to different memory tiers.
For the MoEs I've tested over my entire AI session history about 37.5% of the model is responsible for 95% of token routing.
So we can offload 62.5% of an LLM onto SSD/NVMe/CPU/Cheap VRAM this should theoretically result in minimal latency added if we can select the right experts.
We can combine this with paged swapping to further accelerate the prompt processing, if done right we are looking at very very decent performance for massive unquantisation & unpruned LLMs.
You can get DeepSeek-v3.2-speciale at full intelligence with decent tokens/s as long as you have enough vram to host the core 20-40% of the model and enough ram or SSD to host the rest.
Add quantisation to the mix and you can basically have decent speeds and intelligence with just 5-10% of the model's size in vram (+ you need some for context)
The funds will be used to push this to it's limits.
-----------------
There's also tons of research that you can quantise a model drastically, then distill from the original BF16 or make a LoRA to align it back to the original mostly.
This will be added to the pipeline too.
------------------
All this will be built out here: github.com/0xSero/moe-com… you will be able to take any MoE and shove it in here, and with only 24GB and enough RAM/NVMe to compress it down. it'll be slow as hell but it will work with little tinkering.
------------------
Lastly I will be looking into either a full training run from scratch -> or just post-training on an open AMERICAN base model
- a research model
- an openclaw/nanoclaw/hermes model
- a browser-use model
To prove that this can be done.
--------------------
I will be bad at all of it, and doubt I will get beyond the best small models from 6 months ago, but I want to prove it's no boogeyman impossible task to everyone who says otherwise.
--------------------
By the end of the year:
1. I will have 1 model I trained in some capacity be on the top 5 at either pinchbench, browseruse, or research.
2. My github will have a master repo which combines all my work into reusable generalised scripts to help you do that same.
3. The largest public comparative dataset for all MoE quantisations, prunes, benchmarks, costs, hardware requirements.
--------------------------
A lot of this will be lead by Eric, who I will tag in the next post.
I want to say thank you to everyone who has supported me, I have gotten a lot of comments stating:
1. I'm crazy, stupid, or both
2. I'm wasting my time, no one cares about this
3. This is not a real issue
I believe the amount of interest and support I've received says it all.
donate.sybilsolutions.ai
English
@t_blom Even better, tell it to ask both Codex and a fresh Opus.
English

Having Claude ask Codex for a second opinion when it gets stuck is mindblowing.
I watch along as they have a little a conversation and the bug is fixed.
I am firmly relegated to third place.
English
@felixrieseberg What are some good examples where Cowork is preferable to Code? I see the folders are still restricted to user root.
English

Today's ship: Projects in Cowork! Built in memory across tasks is super useful, as is having a shared folder & connections setup for a group of tasks.

English
Adrian Nutiu retweetledi

How to never lose your job to AI:
Just surf the models.
Frontier models outclass humans at any form of knowledge that can be written down.
But people who use frontier models in their field of expertise generate new, tacit, situational expertise that the models don't yet have—because the models can't be trained on how they will be used in the future.
Humans can learn to use new models faster than new models can be trained that absorb what they find out, so you can continually "surf" on top of the model's intelligence to generate new expertise.
This is a fundamental limitation of LLMs because they don't learn past their training data. Even few-shot learning doesn't account for this because whatever can be codified into a few shot prompt needs to be used in the correct situation—and this will always stay uncodified in the general case.
Just surf the models. Reap the benefits of a totally new world.
English
@OfficialLoganK It's ridiculous that Google Workspace users haven't yet been able to use the Gemini CLI. Google Workspace is the only way to buy subscriptions for a company; individual accounts go through the Google Play Store/checkout.
English

Our AI Studio vibe coding roadmap for the new few weeks:
- Design mode
- Figma integration
- Google Workspace integration
- Better GitHub support
- Planning mode
- Immersive UI
- Agents
- Multiple chats per app
- Simplified deploys
- G1 support
And more, should be fun : )
English
@robinebers What is laughable about the Claude limits? Claude Max and Codex Pro are the best business subs I ever had.
English

people think AI is going to keep getting cheaper
it's not
→ GPT 5.4 costs more than 5.3-Codex
→ fast mode is 2x on top of that
→ juicy ChatGPT 2x plan limits are over soon
and claude limits are laughable to begin with
the frontier gets more expensive from here
even budget models like MiniMax get more expensive
if you won't build it today...
... you might not be able to afford it in the future
English
Still not buletproof but the best way I found to make Codex stop mid-way is this prompt: don't send the final message until all tasks are completed
English
@amorriscode Still no option to choose the effort level? It doesn't even specify the default.
English

heard you like context?
Opus 4.6 1M context is out for Max/Teams/Enterprise on desktop

English
@ajambrosino Claude will do that first, so you will than get approval.
English
here's an early look at the codex app sidebar I wanted to ship. i was silenced
English