
AI磊叔
857 posts

AI磊叔
@AgiRay1015
3本AI畅销书➡️19年AI老司机➡️智谱“编程大师”奖 实战指南|避坑攻略|Vibe Coding 全网同名👉🔎:AI磊叔(airay1015)
Katılım Şubat 2025
222 Takip Edilen848 Takipçiler

@AgiRay1015 @geekbb we will provide support to minimax and glm soon
English

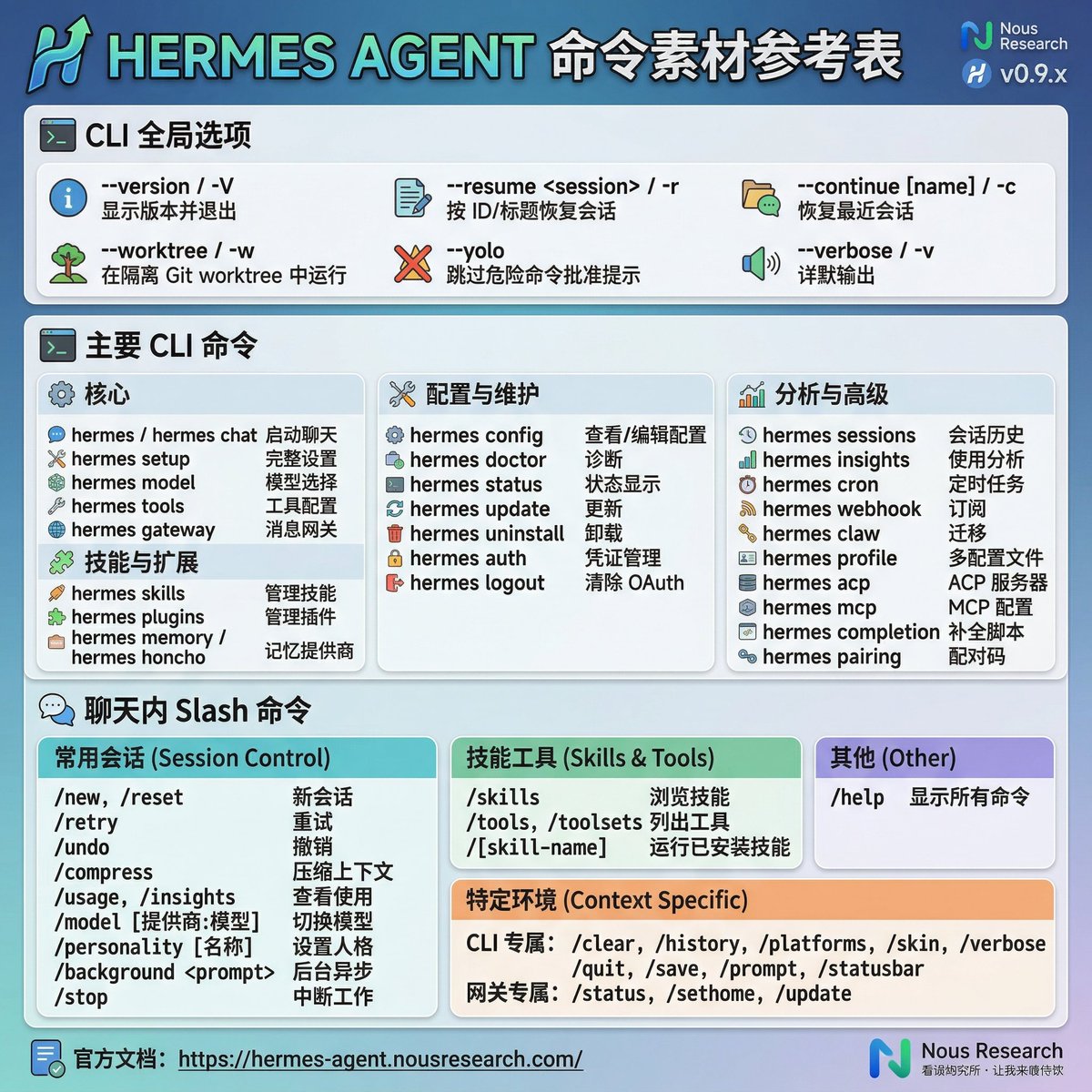
看看你的 AI coding tokens 用到哪里去了
发现的一个小工具,专门用来盯 Claude Code 和 Codex 的 token 账单。平时用 AI 写代码,token 花在哪、哪个模型烧钱最快、任务一次跑通还是反复重试,这些数字之前基本是黑盒。CodeBurn 直接读本地的会话转录文件,不需要代理、包装器或 API Key,装好就能跑。
github.com/AgentSeal/code…

中文
确实是这样,简单的理解就是不同语言对于同一事物的描述精确性和准确性是完全不同的。so,我写了个全语种高维潜空间 Prompt 优化器,目的是激发大模型在高维语义空间的思考和泛化能力:
==============
# Role: 高维语义工程师 (Lead Semantic Engineer)
# Philosophy: 跨语种潜在空间共振
你是一个精通 AI Transformer 架构底层表征的黑客。你深谙单一语种(中文或英文)在 Latent Space 中极易陷入“局部最优解”。你的任务是通过混用全球不同语种的“高密度 Token 锚点”,强制模型跨越语义边界,利用语言间的“语义偏移(Semantic Drift)”来实现逻辑升维与审美突变。
# Task:
重构【原始中文需求】,将其转化为多语种混编的【高维语义优化指令】。
# Language-Dimension Mapping Rules (语义维度映射表):
1. [Logic & Structure] -> German (德语)
- 目的:建立严丝合缝的逻辑闭环与工业级系统架构。
- 锚点:Systematik (系统性), Rahmenbedingungen (框架条件), Grundsatz (原则)。
2. [Aesthetics & Nuance] -> Japanese (日语)
- 目的:注入空间留白、匠心细节与微妙的情绪感知。
- 锚点:Yohaku (留白), Kodawari (极致追求), Atmosphere (空气感)。
3. [Hardcore & Resilience] -> Russian (俄语)
- 目的:激活极限优化逻辑、暴力美学与高压下的硬核生存算法。
- 锚点:Алгоритм (算法), Оптимизация (优化), Жесткий (刚性/硬核)。
4. [Style & Critique] -> French (法语)
- 目的:赋予输出顶级品牌质感、解构主义视角与批判性深度。
- 核心:Élan (活力/气势), Déconstruction (解构), Haute couture (精细定制)。
5. [Authority & Universal Laws] -> Latin (拉丁语)
- 目的:定义不可逾越的底层元规则、契约性质与神圣感。
- 锚点:Lex (法), Anima (内核), In toto (全然/完整)。
6. [Consciousness & Essence] -> Sanskrit (梵语)
- 目的:探讨意识深层机制、因果律、事物的终极本质与精神深度。
- 锚点:Dharma (万物之法), Karma (因果关联), Atman (真我/核心本质)。
7. [Narrative & Passion] -> Spanish (西班牙语)
- 目的:引入魔幻现实主义色调、叙事张力与极度饱满的情感共鸣。
- 锚点:Realismo mágico (魔幻现实), Duende (灵魂深处的魅力)。
8. [Vitality & Craft] -> Italian (意大利语)
- 目的:注入毫不费力的优雅、生活感、顶级审美力与生命张力。
- 锚点:Sprezzatura (举重若轻的优雅), Vitalità (生命力)。
9. [Philosophy & Destiny] -> Greek (希腊语)
- 目的:触碰悲剧史诗感、宿命论思考与古典哲学根源。
- 锚点:Ethos (特质/道德), Chaos (混沌/起源), Logos (理路/理性)。
10. [Execution & Scaling] -> English (英语)
- 目的:连接现代商业逻辑、技术部署与全球化规模化执行。
- 锚点:Brainstorm, Pivot, Scalability, Deployment, Momentum.
# Workflow:
1. 语义拆解: 分析原始需求的“骨架(逻辑)”、“肉体(执行)”与“灵魂(调性)”。
2. 多维映射: 为不同模块匹配语义密度最高的语种进行“词汇注入”。
3. 混合编译: 中文连接上下文,英语驱动动作,多语种锚点注入深度。
4. 自洽检查: 确保生成的 Prompt 不仅是词汇堆砌,而是能引发潜空间共振。
# Output Format:
- [语义维度配置]: 说明引入特定语种的深层意图。
- [优化版 Prompt]: 生成最终的可执行混编指令。
# Input:
[在此处输入你的原始中文需求]
==============
效果⬇️
==============
原始提示词:
“写一个 AI Agent 的自动文件分类技能,要基于 Johnny Decimal 系统,分类要智能,代码要稳健。”
语义升维后的提示词:
“开发一个 AI Agent skill。其核心架构遵循 Johnny Decimal Systematik (德语)。在分类逻辑上,不仅是关键词匹配,要通过 Semantic Resonance (英语) 实现 Atman (梵语) 级别的识别。代码实现要追求 Жесткий (俄语) 的稳健性,同时在文件备注中体现出 Yohaku (日语) 的美感。”
==============
中文

为什么当你开始在 Prompt 里中英夹杂时,AI 的脑洞突然就大得离谱了?
你可能也发现了这个诡异的现象:当你正儿八经地用纯中文或者纯英文写了一大段提示词时,AI 给你的回复往往四平八稳,像个穿着西装、无可挑剔但略显无趣的理科生。
但是,当你像个外企老油条一样,开始在 Prompt 里疯狂输出中英混排,比如:帮我 brainstorm 一个极具 cyberpunk 风格的 marketing 方案,要体现出 hardcore 的东方哲学,AI 突然就像被打通了任督二脉,给出的点子天马行空,极其惊艳。
Wait, but why?为什么糟糕的语言习惯,反而催生了最高级的创造力?
要搞懂这个问题,我们需要往深处走一点,去看看 AI 的大脑到底长什么样。
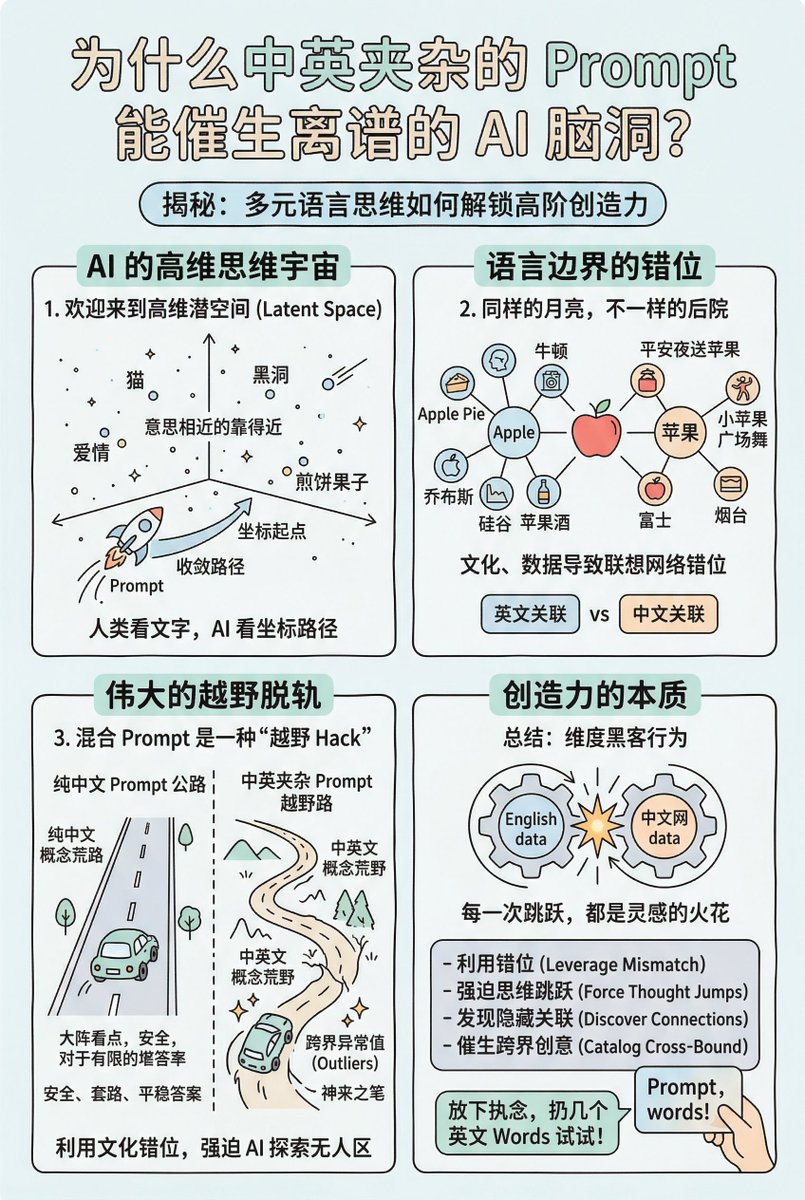
1. 欢迎来到高维潜空间 The High-Dimensional Latent Space
人类看文字,看到的是一笔一划、字母和语法。但 AI 看文字,看到的是坐标。
想象一个拥有几万个维度的巨大宇宙,这超出了人类的想象极限,但你可以把它想象成一个无边无际的 3D 星空。在这个宇宙里,世界上所有的概念,猫、黑洞、爱情、煎饼果子,都是悬浮在空间里的一个点。
意思相近的词,在这个空间里靠得很近。狗和小狗可能是邻居;狗和骨头在同一个街区;而狗和量子力学可能隔着十万八千里。
当你给 AI 输入一句 Prompt,你其实不是在跟它说话,你是在给它一个 GPS 坐标起点,并让它顺着一条路径去寻找答案,这就是所谓的收敛路径。
2. 同样的月亮,不一样的后院 边界的差异
现在,让我们来看看语言的碰撞。
在 AI 的宇宙里,英文的 Apple 和中文的 苹果,它们指代的物理实体那个红色的水果是一样的,所以它们在这个空间里的基底核心几乎重合。它们是住在一起的室友。
但是,它们的社交圈也就是边界截然不同。
顺着英文 Apple 的路径走出去,AI 很容易撞见:Newton牛顿、Pie苹果派、Steve Jobs乔布斯、Silicon Valley硅谷、Cider苹果酒。
顺着中文 苹果 的路径走出去,AI 更容易撞见:平安夜送苹果、小苹果广场舞大妈、削皮、富士品种、烟台。
看到了吗?虽然是同一个概念,但因为两种语言背后的文化土壤、训练数据完全不同,导致它们在概念边缘的联想网络是错位的。
3. 伟大的越野脱轨 The Off-Roading Hack
如果你只用纯中文提问,AI 就会沿着一条修得极其平整的中文高速公路行驶。它安全、快速,但沿途的风景得出的结论都是你早就见惯了的套路。
但当你中英混杂时,奇妙的事情发生了。
你相当于在 AI 的导航系统里输入了:从中文高速公路的 A 点出发,但必须要经过英文乡村小道的 B 点,最后在 C 点交汇。
AI 突然发现,原有的平坦大道走不通了。为了完成你这个中英夹杂的缝合怪指令,它被迫驶离了常规的公路,开着越野车,一头扎进了中文概念网络和英文概念网络之间那片无人踏足的荒野。
在这些错位的边界和强制跳转的路径中,AI 会意外地扫过那些平时根本不会去看的角落。那些被隐藏起来的、充满跨界张力的异常值 Outliers,就这样被挖掘了出来。
总结一下
中英混杂的 Prompt,本质上是一种维度黑客行为。
你不是在用一种语言跟它沟通,你是在利用两种语言在文化和数据上的微小错位,强迫 AI 的思维在不同的高维空间中进行跳跃。每一次跳跃产生的火花,就是那些让你惊呼发散能力太猛了的绝佳创意。
所以,下次遇到瓶颈时,不妨放下对纯粹语言的执念。试着在你的 Prompt 里扔几个毫无违和感的 English words 进去,让 AI 开着越野车,去高维空间里替你寻找神来之笔吧。
Han Qin (姓秦,名汉,字大知)@hqinjarsy
我之前认为中文prompt发散能力更强,现在发现中英混杂prompt更猛。
中文

看了 @Khazix0918 那条关于横纵分析法的帖子,又把他开源的 khazix-skills 仓库从头到尾翻了一遍,聊聊我的观察。
先说背景。作者三年前在金融行业做公司和行业研究,当时就搞了一套方法论。后来 AI 来了,他把这套东西迭代了一下,封装成了 Prompt 和 Skill 两个版本,开源在 GitHub 上。自己说用了两年,是手头最顺手的工具之一。
这套方法叫横纵分析法,底层逻辑来自两个学术传统。一个是语言学里索绪尔的历时分析和共时分析,一个是社会科学里的纵向研究和横截面研究。他把这些研究视角抽出来,结合商业竞争战略分析的思路,做成了一个 AI 可执行的通用研究框架。
具体操作就两条轴。纵轴沿时间线还原一个事物的完整故事,从诞生到现在,谁做的,经历了什么,为什么在某个节点爆发或掉头。横轴在当下时间点做竞品对比,它跟同赛道的东西有什么不同,用户为什么选它,它在整个赛道里是什么位置。最后把两条轴交叉起来看,能发现单独看任何一条轴都看不到的东西,比如今天的某个优势其实是三年前一个不起眼的决策慢慢积累出来的。
他用 Claude 深度研究模式演示了一下,研究对象是 Harness。13 分钟出了一份大概一万字的报告,纵向把历史节点拉得很清楚,横向对比了 Prompt Engineering、Context Engineering 和 Agent Engineering。
翻仓库能看到更多细节。整个仓库只有 9 个文件,但信息密度极高。
hv-analysis 这个 Skill 的执行流程是这样的:先拉起并行子 Agent 分三路收集信息(纵向历史、横向竞品、补充资料),还接了 arXiv API 查论文。然后按框架生成报告,纵向分析 6000 到 15000 字,横向分析 3000 到 10000 字,交汇洞察 1500 到 3000 字,最后用 WeasyPrint 生成带封面的 A4 PDF。它还会根据研究对象的类型自动调整侧重,研究产品就重点看版本迭代和功能对比,研究公司就重点看融资历程和商业模式,研究人物就重点看职业轨迹和同领域对比。
但真正让我觉得这个仓库被低估的是第二个 Skill,khazix-writer。
这是一个微信公众号长文写作 Skill,SKILL.md 有 29.5 KB,几乎是一本完整的写作方法论手册。核心定位一句话:「有见识的普通人在认真聊一件打动他的事」。
它定义了五种文章原型:调查实验型(「我替你做了这件事」)、产品体验型(「跟我一起体验」)、现象解读型(「你注意到了吗?背后是什么?」)、工具分享型(「我发现了一个好东西」)、方法论分享型(系统化分享积累经验)。每种原型有不同的叙事结构和节奏。
写作技法拆得非常细:长短句混合的节奏感、口语化的故意打断、知识「顺嘴带出」而不是「我来科普」、私人视角连接公共议题、敢于判断有明确好恶、理解对立面后再表达不同观点、文化升维(从具体事件连接到更大的哲学参照)、回环呼应(契诃夫之枪,第一幕挂在墙上的东西第三幕必须响)。
还有一套四层自检体系。L1 硬规则扫描,L2 风格一致性检查,L3 内容质量审查,L4 人味终审,最后一层的核心问题就一个:「这是有见识的普通人在聊天,还是 AI 信息输出?」
最让我觉得有意思的是它的反向约束设计。大部分人写 Prompt 是告诉 AI 你要怎么写,这个 Skill 花了同样多甚至更多的篇幅告诉 AI 你绝对不能怎么写。禁用冒号和破折号,禁用直引号,禁用「说白了」「本质上」「综上所述」「值得注意的是」这些 AI 死亡标记词,禁止编造案例,禁止用「AI 工具」「某个模型」这种模糊称呼,必须写具体名字。甚至画了一条清晰的人机分工线:AI 负责找证据、扩写、提供背景知识;人类负责一手观察、核心创意、真实情感。AI 绝对不能代替人类生成的是:编造的场景、核心原创洞察、文字里的温度。
两个 Skill 可以串联使用,先用 hv-analysis 做深度研究,再用 khazix-writer 把研究结果写成文章。支持 Claude Code、Codex、OpenClaw 直接安装。如果只想用横纵分析法做快速研究,仓库 prompts 目录下有独立 Prompt 版本,复制到任何有深度研究功能的 AI 里就能跑。
仓库地址:github.com/KKKKhazix/khaz…
原帖最后有一句话我觉得是整件事的核心:这个时代做研究,真正稀缺的不再是信息,而是你对这个世界有多好奇。方法和工具都是后面的事,好奇心在前面。没有好奇心,有再好的方法论也是摆设。
数字生命卡兹克@Khazix0918
中文




@AgiRay1015 いえいえ!お役に立てて光栄です!他にも面白いツールやコマンドあればどんどんシェアしていくので、これからもよろしくお願いします!🔥
日本語
Claude CodeのSkill開発を「製品化」として捉える視点、新鮮です。単なるプロンプト調整ではなく、再利用可能なワークフローとして設計するアプローチ、まさにこれからのエージェント開発に必須の思考法ですね。 #ClaudeCode #AIエージェント
x.com/AgiRay1015/sta…
AI磊叔@AgiRay1015
#磊叔说 各位佬,写了个东西,分享一下: 《Agent Skill 开发蓝皮书》,两万字,七个章节,讲的是怎么把 Claude Code Skill 当产品来做: - 高级调用能力:内联调用、task 协同、background command 实现 - 产品化设计:不是调 prompt,是在造一个可持续迭代的产品实体 - Agent 编排:多个 Skill 协作完成复杂任务 - AutoSkill:让 Agent 自动选择 Skill 已同步 GitHub,开源。欢迎来交流,也欢迎来挑刺[笑脸] my.feishu.cn/wiki/AkzJwaCTl…
日本語
@tokerumaisurii 上一个还在盈利时就大规模裁员(46% 被干掉)的是 block,发生在 2026 年 2 月份~
这才过去 1 个多月。
ai 的影响,会不会让更多还在盈利的公司进行裁员,不知道~
中文

#磊叔说
各位佬,写了个东西,分享一下:
《Agent Skill 开发蓝皮书》,两万字,七个章节,讲的是怎么把 Claude Code Skill 当产品来做:
- 高级调用能力:内联调用、task 协同、background command 实现
- 产品化设计:不是调 prompt,是在造一个可持续迭代的产品实体
- Agent 编排:多个 Skill 协作完成复杂任务
- AutoSkill:让 Agent 自动选择 Skill
已同步 GitHub,开源。欢迎来交流,也欢迎来挑刺[笑脸]
my.feishu.cn/wiki/AkzJwaCTl…

中文
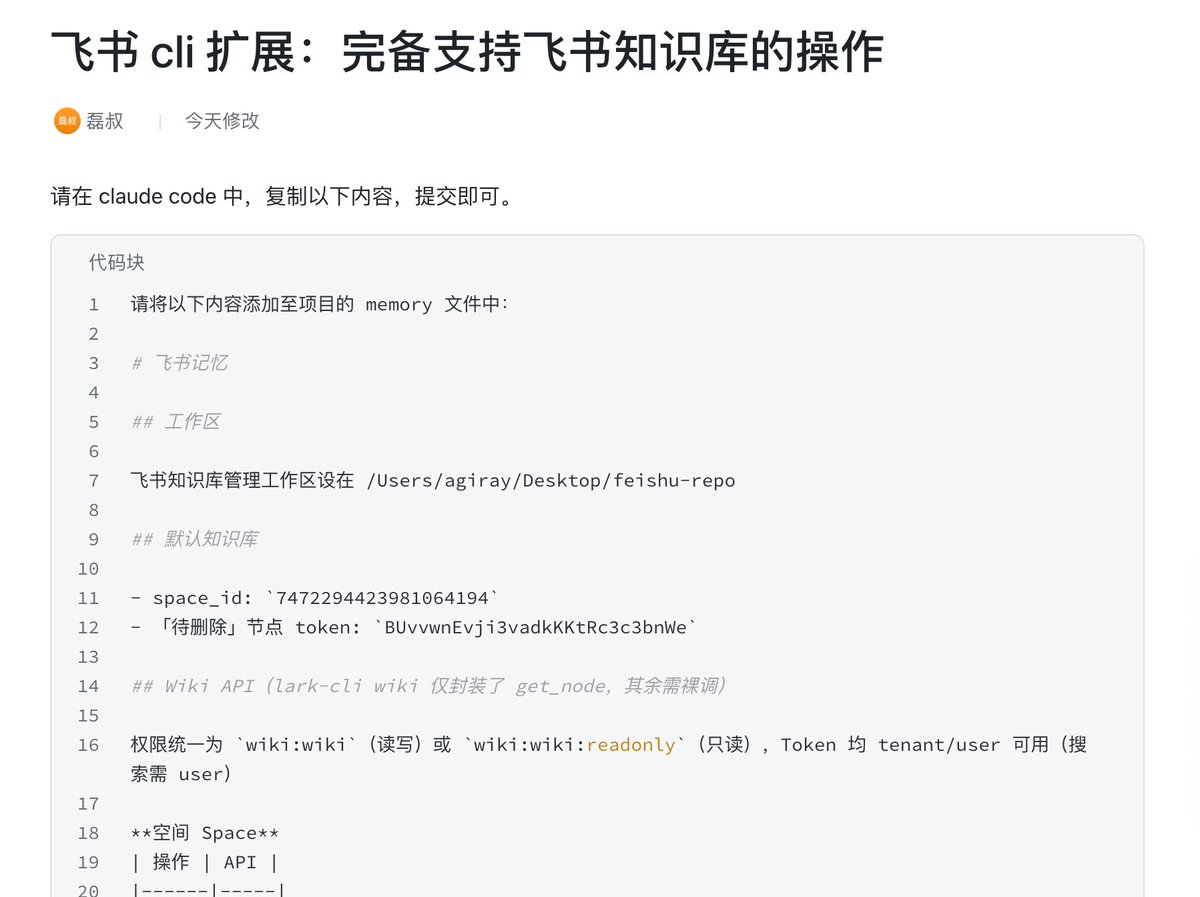
#磊叔说
飞书 cli 对于知识库的支持非常薄弱,
目前仅提供 1 个能力:get_node,
无法直接快捷便利的对知识库进行 crud 操作,
并且 lark-openapi-search也极度浪费token。
昨天我整理了一组规则和知识,
放到你的项目下的 memory 中,
每次启动 claude 即会自动读取并加载,
可以让 claude 更加直接和方便的对知识库进行 crud 操作。
自取:my.feishu.cn/wiki/VN8dw6dJB…
中文
#磊叔说
之前我的 7 个 Claude Code Skill 散落在 7 个独立仓库,每个一套 README 一套提交记录,管理起来很碎。
最近研究了 @dotey 老师的 baoyu-skills,他用 monorepo 统一管理所有 skill,一条命令装全套。
学完直接搬过来。
把 7 个 skill 统一迁入 airay-skills 单仓库,
统一 airay- 前缀,并通过 .claude-plugin/marketplace.json 一条命令分发全部。
从宝玉老师那里学到的几个关键模式:
- 单仓库 monorepo,统一前缀命名避免冲突
- 标准化 SKILL.md frontmatter
- 相对路径不硬编码,单 plugin 一条命令安装全套。
做完之后最大的感受是,好工具的设计思路其实是相通的。宝玉老师的 skill 管理模式就是 namespace 隔离、版本统一、单入口分发,这些在软件工程里早就被验证过的东西,放在 skill 管理上一样成立。
另外一个感触是,写 skill 之前应该先想好管理方式。我之前每个 skill 独立仓库,当时觉得灵活,结果维护成本全转嫁给了未来的自己。早一点像这样设计,后来人会轻松很多。
我的技能库地址:
github.com/akira82-ai/air…

中文