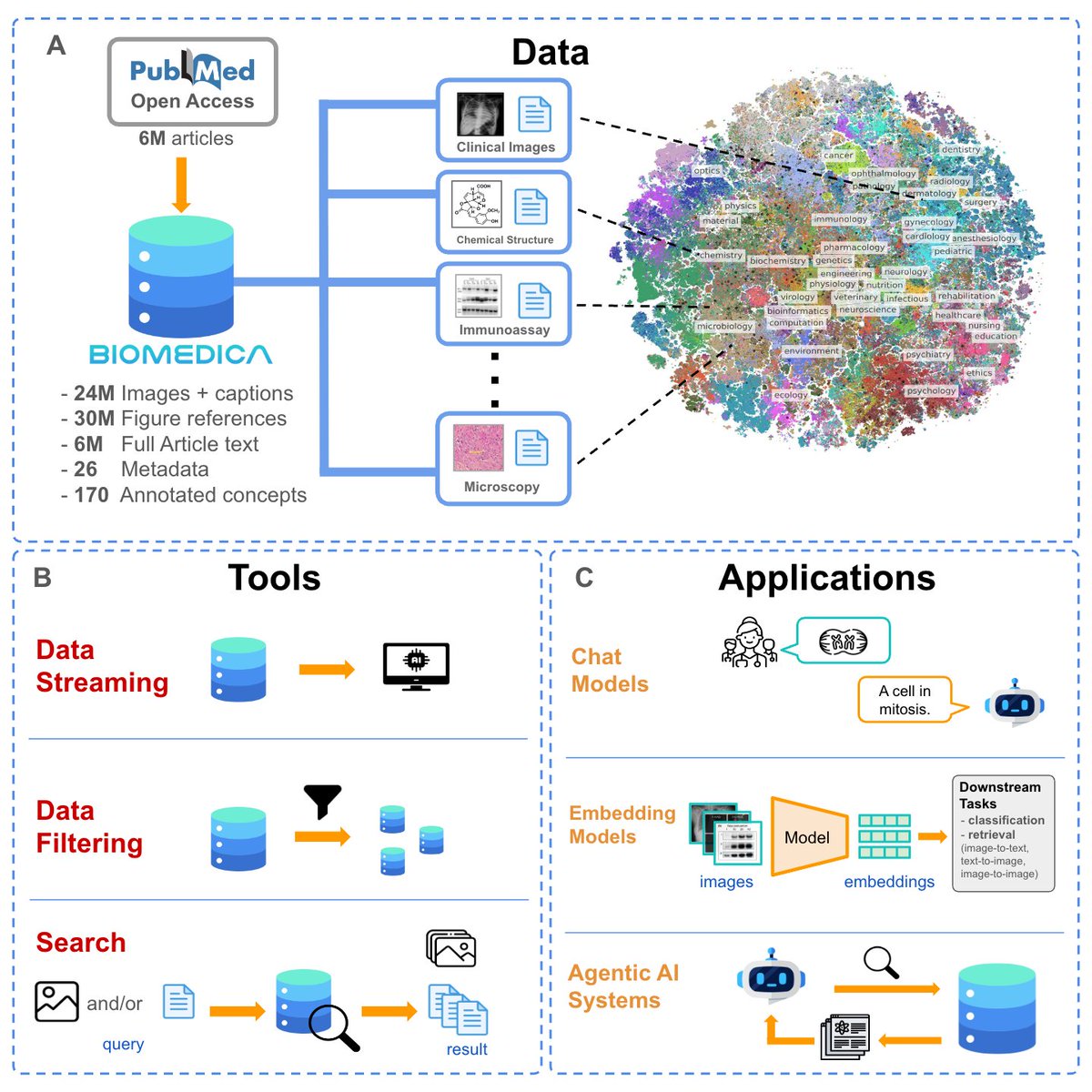
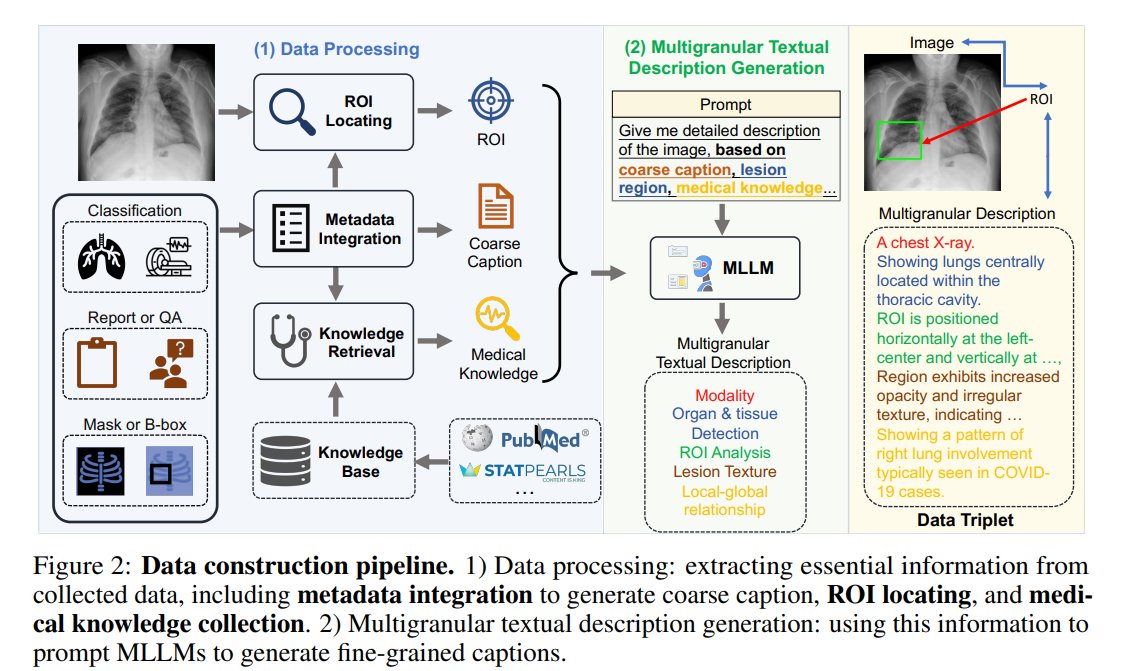
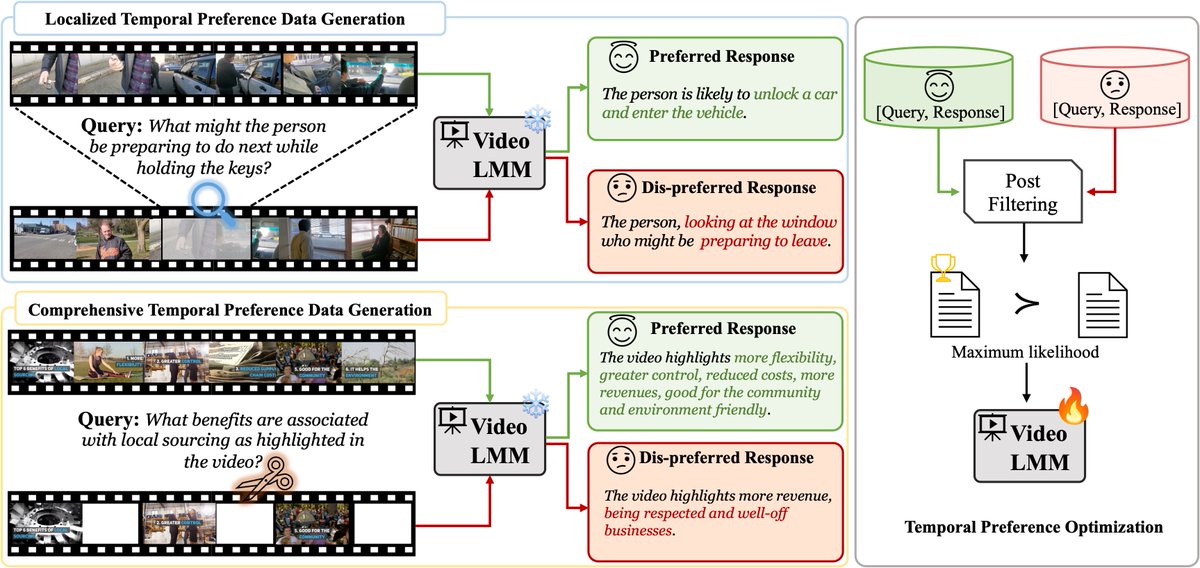
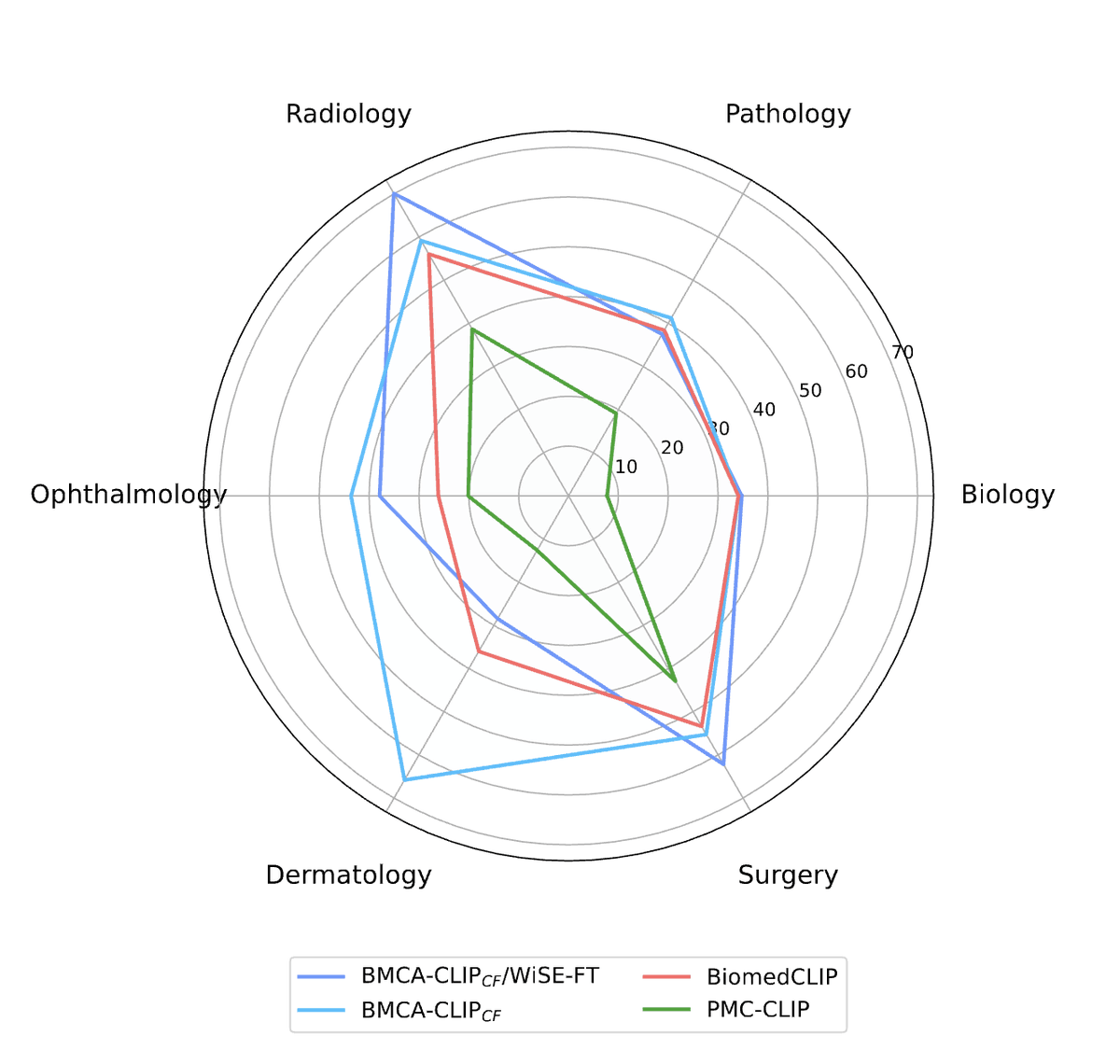
Alejandro Lozano retweetledi

🧬 What if we could build a virtual cell to predict how it responds to drugs or genetic perturbations?
Super excited to introduce CellFlux at #ICML2025 — an image generative model that simulates cellular morphological changes from microscopy images. yuhui-zh15.github.io/CellFlux/
💡 Key Innovation: We frame perturbation prediction as a distribution-to-distribution learning problem, mapping control cells to perturbed cells within the same batch to mitigate biological batch artifacts, and solve it using flow matching.
📊 Results:
✅ 35% higher image fidelity
✅ 12% greater biological accuracy
✅ New capabilities: batch effect correction & trajectory modeling
🎯 Impact: Paving the way for faster drug discovery and deeper biological insights.
📍 Poster: Tue 7/15, 11:00 AM – 1:30 PM, #301
🙏Huge thanks to all my brilliant collaborators:
@hhhhh2033528 (co-lead; now Harvard AIM PhD! 🎉) @ChenyuW64562111 @TianhongLi6 @zoewefers @jnirsch @jmhb0 @DaisyYDing @Ale9806_ @Prof_Lundberg @yeung_levy!
#MachineLearning #ComputerVision #ComputationalBiology #DrugDiscovery #AIforScience #CVforScience
English