
Jeff Nirschl
773 posts
Jeff Nirschl
@jnirsch
M.D.–Ph.D. interested in computational image analysis, digital pathology, and neuropathology. Personal account: all opinions are my own.
Madison, WI Katılım Eylül 2013
1K Takip Edilen435 Takipçiler
The @ProteinAtlas was absolutely essential to this work. The HPA graciously made their data CC-BY-SA-4.0, which enabled this work. I'm so fortunate to be a part of this outstanding team! And thanks to my postdoc mentor, @yeung_levy who encouraged me to pursue this direction.
English
Thanks, @ZhiHuangPhD! Shout-out to @Prof_Lundberg, a brilliant scientist and wonderful person who has been at the HPA for years! The Human @ProteinAtlas has been ongoing for >20 years. and is a testament to large-scale open science initiatives.
#hpa #digitalpathology #ihc
Zhi Huang@ZhiHuangPhD
🚀 Introducing iSight: toward expert–AI collaboration for #immunohistochemistry (IHC) assessment Preprint: arxiv.org/abs/2602.04063 🚀 What we built: 🖼️ HPA10M, the world’s largest open-access IHC dataset: huggingface.co/datasets/nirsc… • 10,495,672 IHC images (Over 10M!) • 17,000+ protein markers • 45 normal tissues + 20 cancer types • Fully curated, standardized, and publicly available on @huggingface. We trained iSight, a multi-task AI system for automated IHC assessment • Jointly predicts staining location, intensity, and quantity • Outperforms fine-tuned pathology foundation models • Produces well-calibrated, clinically interpretable outputs @PennPathLabMed #DigitalPathology #AIinHealthcare #Immunohistochemistry #HumanAI #Pathology
English
Jeff Nirschl retweetledi

Check out PaperSearchQA, which I'll present at EACL in Morocco this March! We built an RL training environment for teaching LLMs to search and reason over scientific papers. 60k question-answer pairs + 16M papers to search over + benchmarks. RL training improves the model.

English
Jeff Nirschl retweetledi

Excited to share that our lab’s latest work, Melan-Dx, a knowledge-enhanced vision-language framework for improving the differential diagnosis of melanocytic neoplasms in pathology, is now published in @npjDigitalMed! Read it at: nature.com/articles/s4174… @PennPathLabMed #DigitalPathology #Dermpath
npj Digital Medicine@npjDigitalMed
Skin cancer diagnosis isn’t just about seeing. It’s about knowing what you’re seeing. A new AI system improves melanoma diagnosis by combining pathology images with expert knowledge, not just pixels. READ HERE: nature.com/articles/s4174…
English
We're hiring! The Nirschl & Kolb (@hckolb ) labs @UWMadison are seeking a Scientist I/II to help develop novel PET tracers for neurodegenerative diseases.
- Tissue assays, autoradiography, SPR, protein biochem experience desired.
Apply here: jobs.wisc.edu/jobs/nirschl-s…
#PETimaging
English

Markov blankets and mech interp -- why an esoteric philosophy of statistical physics is the key to unlocking the virtual cell, drug discovery, and all of biology:
> "How can the events in space and time which take place within the spatial boundary of a living organism be accounted for by physics and chemistry?" -- 'What is Life', Erwin Schrödinger
1.
virtual cell is the buzzword du jour in the world of ML for bio. typically what's meant by the term is an ML model trained via self-supervised learning to predict which genes/RNA co-express across different cell types. thus, at its most basic level, a virtual cell is nothing more than a model of which biological states are likely vs. unlikely
it's not immediately obvious what such a virtual cell is useful for or what it represents, particularly if all it trains on are static snapshots of gene expression (how most of these models are currently trained)
there are two main ways those in the field currently think about applying these models:
virtual cell as simulator -- you finetune the model on experimental data of cells exposed to perturbations like small molecules or reprogramming factors. once your virtual cell becomes realistic enough, this perturbation-conditional model can be used to simulate these kinds of experiments in silico
virtual cell as specimen -- perhaps you believe that by learning to predict which genes co-express, your virtual cell has learned about the underlying gene regulatory network giving rise to this gene expression distribution, from which you can extract this ground-truth network and use it to reason about the drivers of cellular behavior (e.g. X -> Y -> Z). thus the utility of the virtual cell comes from mechanistically dissecting its inner workings
these two applications, perturbation prediction and gene regulatory network inference, are how most think about applying virtual cells to drug discovery. unfortunately, both applications are inherently limited:
- perturbation prediction is on some level just a glorified form of data-hungry interpolation, dependent on tiling the cell state manifold more densely with experimental data. it is bottlenecked by experimental data generation, and at least currently, our virtual cells aren't great simulators
- gene regulatory networks aren't all that useful for understanding or learning to control the behavior of cells, both because RNA usually isn't our action space or state space of concern, and because, even if it were, the complexity of cellular dynamics aren't fully captured by a simple GRN. thus, our virtual cells don't make a great specimens
were the virtual cell program limited to these two applications, that would be reason for pessimism, and the skeptics would be correct in assessing the field as currently over-hyped
but what if the skeptics are wrong, and virtual cells aren't merely poor simulators or poor specimens, but some secret third thing -- the kernel of a program far more ambitious in scope that has the potential to revolutionize drug discovery? building up to this secret third thing will require a brief detour into esoteric philosophy and statistical physics
2.
the cell is a biological computer, and amid the blooming, buzzing confusion of molecules there is order. we can then ask: what function is the cell computing to maintain this order? or, put another way, what objective function is this biological computer trying to minimize?
the free energy principle (FEP) is a grand unifying principle that answers this question -- not just for the cell, but for all agentic systems
it posits that the defining imperative of any agent is to accurately predict the world around it, i.e. to minimize an upper bound on sensory 'surprise' (or, equivalently, minimize free energy, which penalizes both prediction errors and the complexity of the model making these predictions)
the agent does this by both updating its model of the world to better predict it (Bayesian perceptual inference), and by acting upon the world to make it more predictable (active inference). through doing this, the agent maintains homeostasis and resists disorder
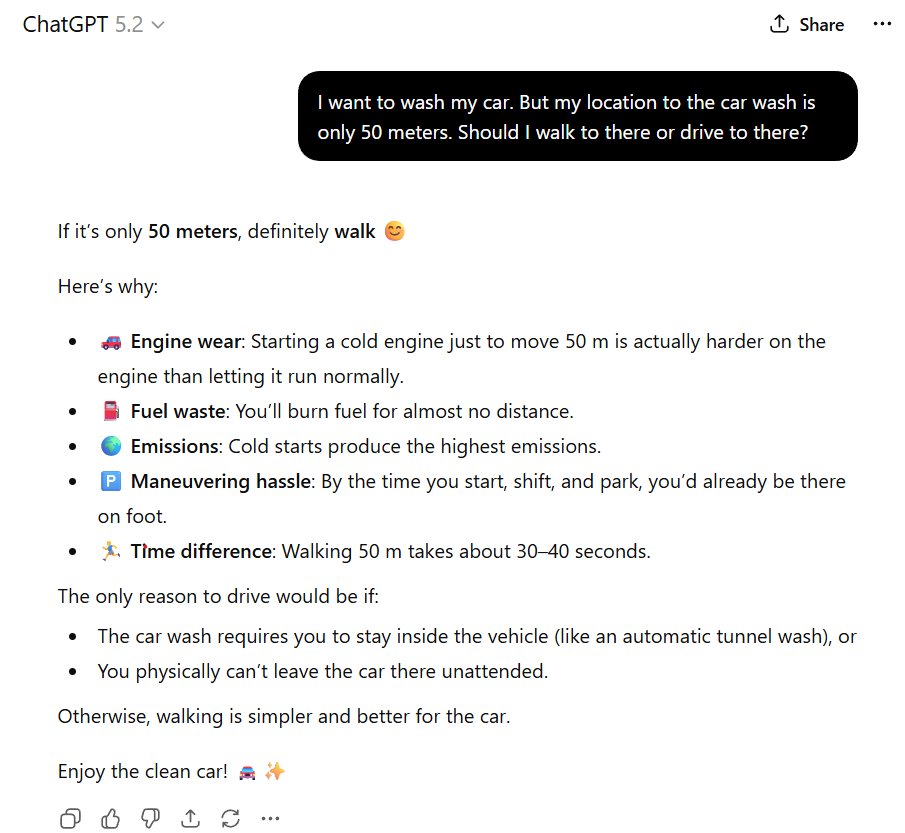
the formal setup for this involves an agent embedded within an external environment. the coupling between the agent's internal model and the external world is sparse and indirect: the internal model never directly witnesses the external world
rather, their dialogue is mediated by a statistical partition called a "Markov blanket", which maintains conditional independence between the internal agent states and the external world states
these blanket states are comprised of sensory states and active states: the external world evolves, generating signals which impinge upon the agent's sensorium (sensory states); and the agent's "effectorium" generates actions (active states) which project into the external world, altering it
thus, the agent updates its internal model to better explain the sensory impressions it receives, and generates actions which impact the external world, changing the sensory impressions this world generates
amazingly, it can be shown that in order to maintain homeostasis, the agent's internal states encode *beliefs* about the distribution of external world states, despite never directly witnessing them (due to the Markov boundary): for every internal agent state, there is a corresponding distribution of external states it predicts to be most likely (given some sensory and active states)
in essence, the agent's internal model is inferring the hidden external causes of the sensations it receives
or, in other words, the agent contains a generative model of its environment and how its actions influence it, i.e. a *world model*
but what does any of this have to do with virtual cells?
3.
the cellular membrane is the canonical physical example of a Markov boundary, buffering the internal world of the cell from the external milieu: through it the cell receives sensory impressions from the world (nutrient gradients, noxious stimuli, mechanical forces) and acts upon the world (releasing signaling molecules, probing with pseudopodia, moving with actin filaments)
when the cell receives a surprising sensory state, like an unexpected influx of some ion or an attacking neighboring immune cell, it must "explain away" this surprise by updating its internal model
if we continue running with this idea of cell as agentic system, it would seem that the cell's internal world model -- the generative model of the niche it finds itself in -- is computed in the language of molecules
when the cell receives a surprising sensory state, like an unexpected influx of some ion or an attacking neighboring immune cell, it must "explain away" this surprise by updating its internal model via changes in the distribution of these molecules (e.g. via changes in epigenomic state, gene expression, post-translational modification, etc.) and by acting upon the world
therefore, it's not too farfetched to say that when we sample molecules like RNA or proteins from the cell, we are in fact sampling states from the cell's internal world model -- and training a generative model on the distribution of these molecules is learning a compressed version of this world model
just as an LLM trained on human text corpora in some sense learns to "think like a human" (the latent data-generating process producing the text tokens we train on), so too does our virtual cell learn to "think like a cell" (the cell's internal generative model encoded in the distribution of molecules we train on)
but wouldn't this virtual cell just be learning to model the distribution of RNAs or proteins?
no, it wouldn't. per the free energy principle, our cell's world model must reliably infer the latent external causes of the sensory impressions it receives and generate the optimal actions to shape this external world. to do this, the model must be robust (the external world is stochastic and generates noisy sensory signals which you shouldn't overfit to) and cheap (biological computation has an energetic cost, in addition to the inferential benefits of parsimony)
for the cell's world model to be robust and cheap, it must be a sparsely coupled model over the *latent* variables in its environment, and hence should occupy a lower-dimensional manifold than the ambient gene or protein expression space it is computing in. additionally, the cell has evolved to model an external world composed of *other cells like itself* that model the world in a similar way, and such a theory of mind will be implicit in its world model
therefore, if we properly train our virtual cell model, it too should learn this latent, sparsely-coupled internal world model of the cell, providing us with the levers of belief and action to control the cell's behavior -- either by inducing sensory hallucinations (e.g. via a small molecule) that make the cell update its beliefs about the world, or by directly intervening on these internal states (e.g. by knocking out a protein)
4.
unfortunately, it's not obvious how to extract such a latent world model from a virtual cell trained in the language of RNAs or proteins
the secret lies in applying mechanistic interpretability to the virtual cell by training sparse autoencoders on its internal activations. doing so lets us extract the latent features which generate the distribution of activations inside the model, and thus the cell's internal world model
when we did this for a simple virtual cell trained on single-cell gene expression data, the features we discovered appear rather un-agentic -- those related to osmotic stress, processing environmental toxins, cellular machinery for vesicle trafficking and recyling -- and it made little sense to impute any sort of propositional attitudes (beliefs, expectations, etc.) to the virtual cells in which they activate
but as we scale our models toward multicellular systems and beyond, we may be surprised by the degree of agency we discover inside our virtual biological systems -- sense of spatial location, simple associative learning, and perhaps even long-horizon planning. if a bacterial quorum can sense nutrient gradients, just imagine what multicellular eukaryotic collectives can do (of course, a single eukaryotic cell is itself a hierarchy of nested sub-agents: mitochondria were co-opted by evolution, the retrotransposons which make up >40% of our nuclear genome are parasitic hitchhikers, the nucleus is itself a Markov-blanketed sub-agent, etc.)
the upshot of all of this is that by learning how the cell has evolved to see the world, we learn the dual of how the world has evolved to act upon the cell, giving us the correct language to communicate with and control it

English

Interesting repo with Claude skills for scientific applications. Includes modal skills!
github.com/K-Dense-AI/cla…

English
@Readwiseio save
Jeremy Howard@jeremyphoward
Recently we released a 3000+ word book chapter written by @KeremTurgutlu, based on @karpathy's marvelous "Let's built the GPT tokenizer" video. It's got pics, links, code, diagrams, … Kerem has now written a detailed walk-through of how he made it: answer.ai/posts/2025-10-…
English
Amazing work, Zhi!
Zhi Huang@ZhiHuangPhD
Wow! TissueLab.org has reached over 1700 users in the first 30 days and almost 500 downloads 🚀🔥! What an impressive achievement by my team. So proud of my students! We will keep shipping the code, fixing the bugs, and improve user experiences. Check out the first co-evolving agentic AI system for medical image analysis! 👉arxiv.org/abs/2509.20279 #TissueLab #AIAgent #AgenticAI #pathology #radiology
English

1/ If you're in bioinformatics, you're staring at matrices all day.
RNA-seq? Gene x sample.
scRNA-seq? Gene x cell.
Everything is a matrix.
But I never learned how to think in matrices. And I regret it.

English

Nice, short post illustrating how simple text (discrete) diffusion can be.
Diffusion (i.e. parallel, iterated denoising, top) is the pervasive generative paradigm in image/video, but autoregression (i.e. go left to right bottom) is the dominant paradigm in text. For audio I've seen a bit of both.
A lot of diffusion papers look a bit dense but if you strip the mathematical formalism, you end up with simple baseline algorithms, e.g. something a lot closer to flow matching in continuous, or something like this in discrete. It's your vanilla transformer but with bi-directional attention, where you iteratively re-sample and re-mask all tokens in your "tokens canvas" based on a noise schedule until you get the final sample at the last step. (Bi-directional attention is a lot more powerful, and you get a lot stronger autoregressive language models if you train with it, unfortunately it makes training a lot more expensive because now you can't parallelize across sequence dim).
So autoregression is doing an `.append(token)` to the tokens canvas while only attending backwards, while diffusion is refreshing the entire token canvas with a `.setitem(idx, token)` while attending bidirectionally. Human thought naively feels a bit more like autoregression but it's hard to say that there aren't more diffusion-like components in some latent space of thought. It feels quite possible that you can further interpolate between them, or generalize them further. And it's a component of the LLM stack that still feels a bit fungible.
Now I must resist the urge to side quest into training nanochat with diffusion.
GIF
Nathan Barry@nathanrs
BERT is just a Single Text Diffusion Step! (1/n) When I first read about language diffusion models, I was surprised to find that their training objective was just a generalization of masked language modeling (MLM), something we’ve been doing since BERT from 2018. The first thought I had was, “can we finetune a BERT-like model to do text generation?”
English


E-values are a modern alternative to p-values for hypothesis testing. Unlike p-values, they allow for anytime-valid inference, meaning you can continuously monitor a data stream and stop the test at any time without invalidating the results. In machine learning, this is crucial for real-time A/B testing and monitoring models for data drift. In real life, they make clinical trials more flexible and efficient, allowing researchers to stop a trial as soon as significant evidence is found.
arxiv.org/pdf/2410.23614

English

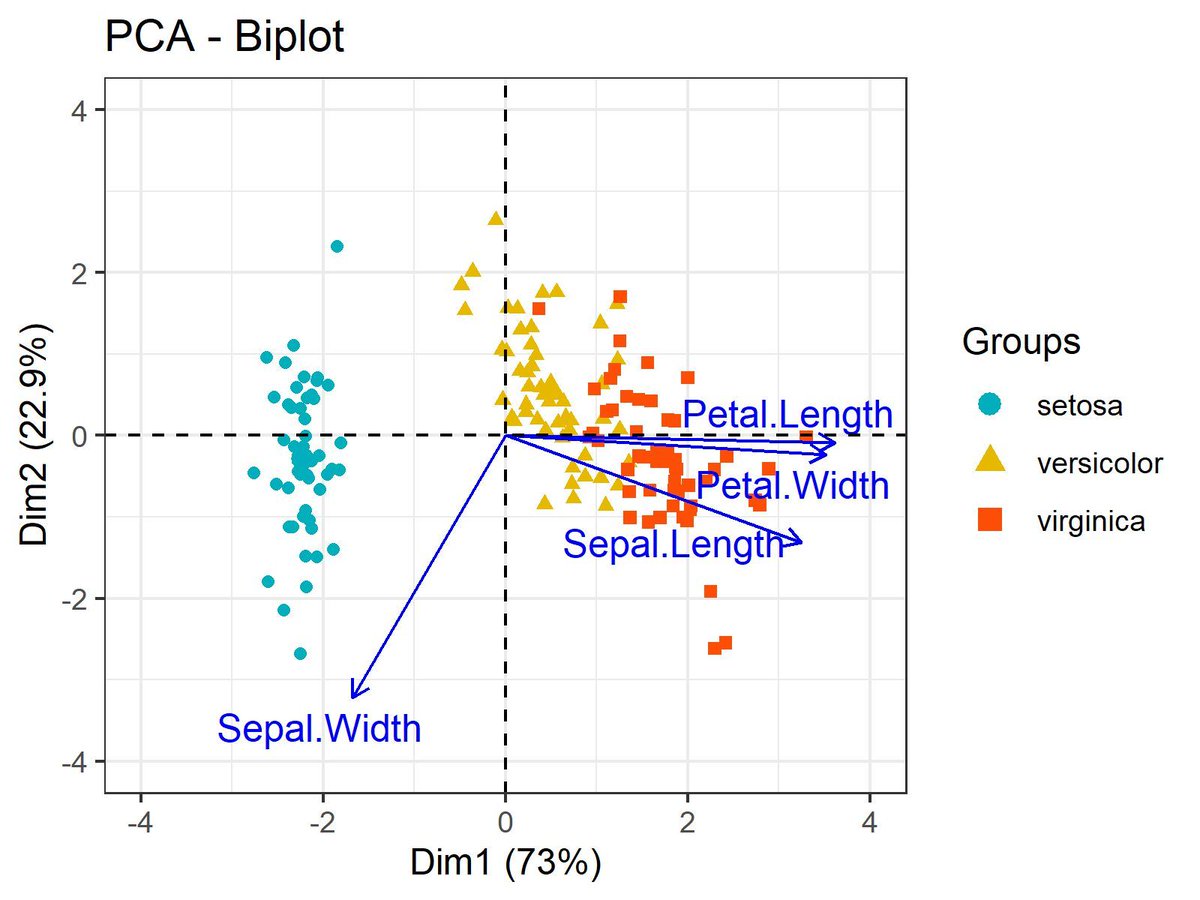
Ever wondered how Principal Component Analysis (PCA) works to simplify complex data? Enter biplots!
Biplots visually represent both the data points and the variables in a single plot.
Here's how it works:
1️⃣ Data points are represented as dots.
2️⃣ Variables are represented as arrows.
3️⃣ The direction of the arrows shows the relationship between variables.
4️⃣ The length of the arrows indicates the strength of each variable in explaining the data.
With biplots, you can:
✅ Visualize relationships between variables and data points.
✅ Identify patterns and clusters within your data.
✅ Understand which variables are most influential in explaining the variance.
Ready to dive into the world of PCA with biplots? Join the Statistics Globe online course. Click this link for detailed information: statisticsglobe.com/online-course-…
#datascienceeducation #Python3 #RStats #rstudioglobal #database #Data #Python
English

Evolution of Deep Learning by Hand ✍️ As my tribute to Geoff Hinton's Nobel Prize, I drew this animation to illustrate the key idea behind Hinton's major contributions to deep learning over the years, with artistic liberty.
----
100% original, made by hand ✍️
Join 40k readers of my newsletter: byhand.ai
English
12 years ago, I typed my first "Hello world!".
It is not easy to learn bioinformatics from scratch.
But it is possible if you put in effort and have a clear pathway.
read my story here divingintogeneticsandgenomics.com/publication/20…

English

Proposals fail because of two misplaced paragraphs.
Most researchers bury their motivation on page 3.
They lead with background instead of urgency.
The Why-What sequence flips this completely.
Here's a 15-part structure I use that makes it simple.
Let's break it down into 7 broad steps:
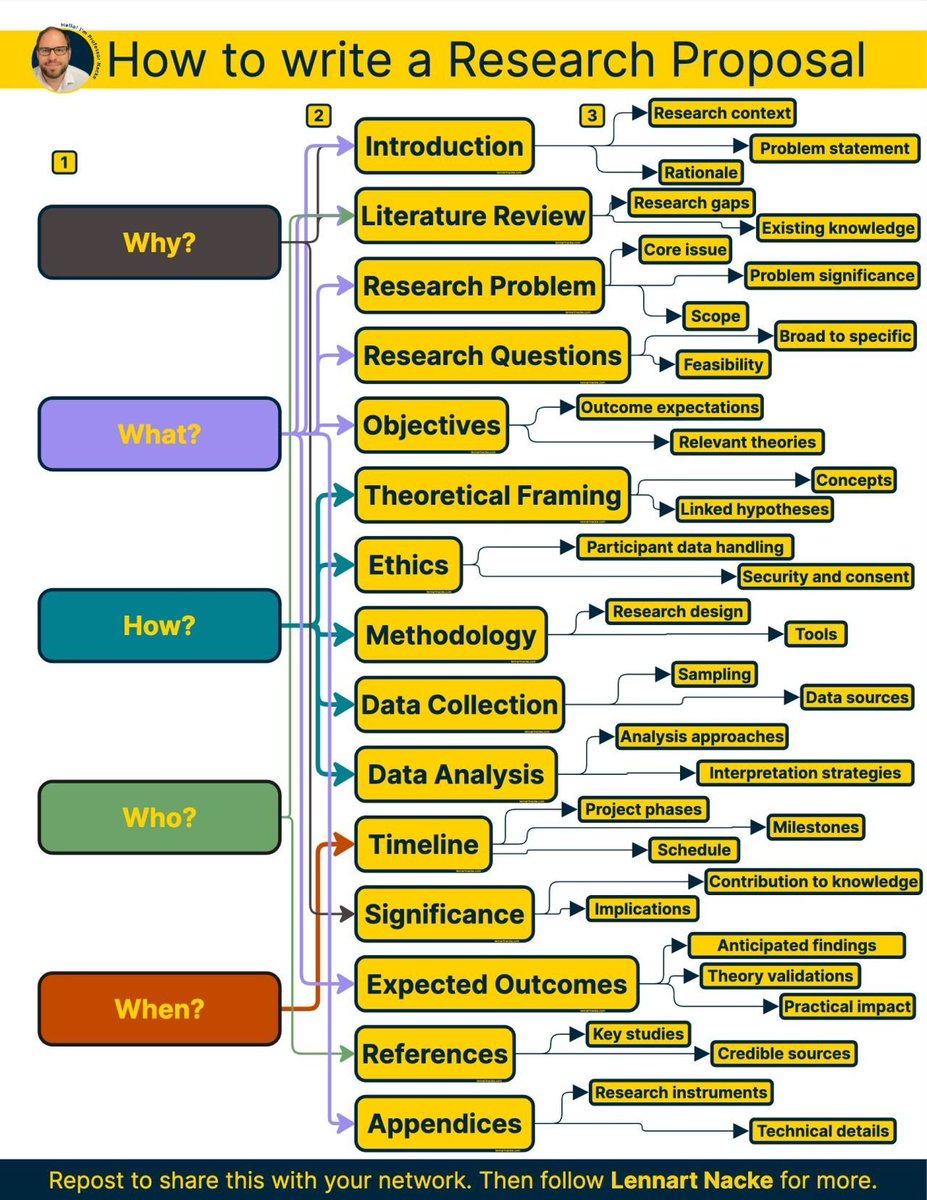
English
ggplot2 is the gold standard when it comes to data visualization. Here's why:
✔️ Consistent, intuitive syntax that makes it easy to learn and use across various plot types.
✔️ Seamless integration with other tidyverse packages, enabling smooth data workflows.
✔️ Efficient handling of large data sets, ensuring smooth and responsive plotting even with complex data.
✔️ Over 100 extensions that enhance its core capabilities, providing endless options for creative visualizations.
✔️ Trusted by more than 1,000 packages, ensuring reliability and broad support.
The image in this post showcases examples of ggplot2 visualizations, demonstrating its versatility to create a wide range of plots with nearly limitless customization options.
Want to learn more? Check out my online course, "Data Visualization in R Using ggplot2 & Friends," for a deeper dive into creating stunning plots with ggplot2.
More details are available at this link: statisticsglobe.com/online-course-…
#StatisticalAnalysis #datavis #tidyverse #ggplot2 #programmer #R4DS #RStats #DataVisualization #database #Data

English

I am often asked what the one skill is that young scientists should work on the most. My answer: your storytelling via presentations.
The better you present, the more your ideas travel, the more doors open, and the more people want to work with you.
A few tips:
Have one clear storyline that you want people to remember. Repeat it. Build your talk around it.
Your slides are there to support you, not to talk for you. Think about the best TED Talks...if a slide has more than 10–15 words, it’s a distraction.
Engage the room with confidence. Don’t hide behind the podium. Stand in front of your audience, make eye contact, and own the stage.
A strong talk is a multiplier for everything you do. It helps you get published, win grants, and get hired.
What is your single best tip for a memorable scientific presentation?
hashtag#ScienceCommunication hashtag#PhDLife hashtag#Postdoc hashtag#PublicSpeaking hashtag#AcademicChatter hashtag#Leadership

English