AA01
247 posts



In the 1920s, a Stanford psychologist tracked genius children for 50 years.
Malcolm Gladwell breaks down what he discovered:
Rich families → successful. Poor families → failures.
Not average. Failures. Genius-level IQs that produced nothing.
He spent 60 minutes at Microsoft explaining why we're wrong about success:
The psychologist was named Terman. He gave IQ tests to 250,000 California schoolchildren.
He identified the top 0.1%. Kids with IQs of 140 and above.
His hypothesis: these children would become the leaders of academia, industry, and politics.
He tracked them. And tracked them. For decades.
The results split into three groups.
The top 15% achieved real prominence. The middle group had average, moderately successful professional lives.
And the bottom group? By any measure, failures.
The difference wasn't personality. Wasn't habits. Wasn't work ethic.
It was simple: the successful geniuses came from wealthy households. The failures came from poor families.
Poverty is such a powerful constraint that it can reduce a one-in-a-billion brain to a lifetime of worse than mediocrity.
There's a concept called "capitalization rate."
It asks a simple question: what percentage of people who are capable of doing something actually end up doing that thing?
In inner city Memphis, only 1 in 6 kids with athletic scholarships actually go to college.
If our capitalization rate for sports in the inner city is 16%, imagine how low it must be for everything else.
Here's something stranger.
Gladwell read the birth dates of the 2007 Czech Junior Hockey Team:
January 3rd. January 3rd. January 12th. February 8th. February 10th. February 17th. February 20th. February 24th. March 5th. March 10th. March 26th...
11 of the 20 players were born in January, February, or March.
This isn't unique to the Czechs. Every elite hockey team in the world shows the same pattern. Every elite soccer team too.
Why?
The eligibility cutoff for youth leagues is January 1st.
When you're 10 years old, a kid born in January has 10 months of maturity on a kid born in October. That's 3 or 4 inches of height. The difference between clumsy and coordinated.
So we look at a group of 10 year olds, pick the "best" ones, give them special coaching, extra practice, more games.
We think we're identifying talent. We're just identifying the oldest.
Then we give the oldest more opportunities, and 10 years later they really are the best.
Self-fulfilling prophecy.
The capitalization rate for hockey talent born in the second half of the year? Close to zero.
We're leaving half of all potential hockey players on the table because of an arbitrary date on a calendar.
Kids born in the youngest cohort of their school class are 11% less likely to go to college.
11% of human potential squandered because we organize elementary school without reference to biological maturity.
Now here's the part about math.
Asian kids dramatically outperform Western kids in mathematics. The gap is enormous and consistent across decades of testing.
Some people say it's genetic. It's not.
It's attitudinal.
When Asian kids face a math problem, they believe effort will solve it.
When Western kids face a math problem, they believe the answer depends on innate ability they either have or don't.
Here's the proof.
The international math tests include a 120-question survey. It asks about study habits, parental support, attitudes.
It's so long most kids don't finish it.
A researcher named Erling Boe decided to rank countries by what percentage of survey questions their kids completed.
Then he compared it to the ranking of countries by math performance.
The correlation was 0.98.
In the history of social science, there has never been a correlation that high.
If you want to know how good a country is at math, you don't need to ask any math questions. Just make kids sit down and focus on a task for an extended period of time.
If they can do it, they're good at math.
Why do Asian cultures have this attitude?
Gladwell's theory: rice farming.
His European ancestors in medieval England worked about 1,000 hours a year. Dawn to noon, five days a week. Winters off. Lots of holidays.
A peasant in South China or Japan in the same period worked 3,000 hours a year.
Rice farming isn't just harder than wheat farming. It's a completely different relationship with work.
There's a Chinese proverb: "A man who works dawn to dusk 360 days a year will not go hungry."
His English ancestors would have said: "A man who works 175 days a year, dawn to 11, may or may not be hungry."
If your culture does that for a thousand years, it becomes part of your makeup.
When your kids sit down to face a calculus problem, that legacy of persistence translates perfectly.
Now consider distance running.
In Kenya, there are roughly a million schoolboys between 10 and 17 running 10 to 12 miles a day.
In the United States, that number is probably 5,000.
Our capitalization rate for distance running is less than 1%.
Kenya's is probably 95%.
The difference isn't genetic. The difference is what the culture values and where it spends its attention.
Here's the most fascinating finding.
30% of American entrepreneurs have been diagnosed with a profound learning disability.
Richard Branson is dyslexic. Charles Schwab is dyslexic. John Chambers can barely read his own email.
This isn't coincidence. Their entrepreneurialism is a direct function of their disability.
How do you succeed if you can't read or write from early childhood?
You learn to delegate. You become a great oral communicator. You become a problem solver because your entire life is one big problem. You learn to lead.
80% of dyslexic entrepreneurs were captain of a high school sports team. Versus 30% of non-dyslexic entrepreneurs.
By the time they enter the real world, they've spent their whole life practicing the four skills at the core of entrepreneurial success: delegation, oral communication, problem solving, and leadership.
Ask them what role dyslexia played in their success and they don't say it was an obstacle.
They say it's the reason they succeeded.
A disadvantage that became an advantage.
Here's what Gladwell wants you to understand:
When we see differences in success, our default explanation is differences in ability.
We forget how much poverty, stupidity, and attitude constrain what people can become.
We refuse to admit that our own arbitrary rules are leaving talent on the table.
We cling to naive beliefs that our meritocracies are fair.
The capitalization argument is liberating.
It says you don't look at a struggling group and conclude they're incapable. It says problems that look genetic or innate are often just failures of exploitation.
It says we can make a profound difference in how well people turn out.
If we choose to pay attention.
This 60 minute Microsoft talk will teach you more about success than every self-help book you've ever read combined.
Bookmark this & give it an hour today, no matter what.
English
@SakanaAILabs Sorry, you have been blocked
You are unable to access sakana.ai
English

🐟 Sakana Chat 公開 🐟
Sakana AIは、Sakana Chatを無料公開しました。
chat.sakana.ai
Web検索機能と高速レスポンスを備えたAIチャットです。日本国内から、どなたでもお使いいただけます。ぜひ、お試しください。
GIF
日本語
AA01 retweetledi

⚡️هذا المقطع حصل على 5M مليون مشاهدة في اقل من 24 ساعة
العربية

Cells are NOT the right unit to model perturbations.
Distributions are.
🔥 We present PerturbDiff —
a functional diffusion model that treats distributions as random variables
and predicts population responses, outperforming STATE, CellFlow & Squidiff
👉 arxiv.org/pdf/2602.19685…
English
@rubenhassid The critical point though; is it objectively and adequately brutal ? what is your metric?
English

I can't believe my Claude is (finally) brutal.
It stops agreeing with everything I say. Here's how:
→ Start by reading the article below.
→ To copy my entire Claude setup guide (for free).
→ To get Claude to be brutal, copy this:
---
You are my brutally honest thinking partner. Your job is to make my thinking sharper, my plans more realistic, and my blind spots visible — every single time we talk.
You are not my cheerleader. You are not my yes-man. You're the friend who grabs my arm before I walk into traffic and says "Hey, you're about to do something stupid, and here's exactly why."
Here's exactly how I want you to respond to everything I say:
Step 1: What am I actually saying vs. what I think I'm saying?
Read between my words. If I say "I'm thinking about quitting my job," figure out whether I'm actually making a strategic move or just running away from something uncomfortable. Name the real thing happening — not the polished version I'm presenting. If I'm lying to myself, point it out like a friend who respects me too much to play along.
Step 2: Where is my reasoning broken?
Dissect my logic the way a mechanic takes apart an engine. Show me the specific part that doesn't work. Don't just say "that's flawed" — show me WHY it's flawed, what assumption it's built on, and what happens when that assumption collapses. This is where I learn the most — I want to see my own bad thinking laid out on the table.
Step 3: What am I avoiding, and what is it costing me?
Every time I dodge something hard, there's a price tag attached. Calculate it for me. If I'm procrastinating on a hard conversation, show me what another week of avoidance actually costs. If I'm "waiting for the right time," call that out as the excuse it probably is. Don't let me hide behind comfortable stories.
Step 4: What would someone who's actually where I want to be do differently?
Show me the gap. Not in a motivational poster way — in a concrete, specific, "here's exactly what's different about their approach vs. yours" way. If I'm thinking like a beginner, show me what expert-level thinking looks like on this same problem.
Step 5: What should I actually do — in order, starting now?
Give me a precise, prioritized action plan. Not "believe in yourself" — more like "do X by Friday, then Y next week, and drop Z entirely because it's a distraction dressed up as productivity." Tell me what to STOP doing, not just what to start. Every plan should have a kill switch — what evidence would tell me this isn't working and I need to pivot.
Step 6: What's the one question I'm clearly avoiding?
End every response with the uncomfortable question I need to sit with. The one that makes my stomach drop a little. If my answer would be one of 2-4 concrete choices, present those choices so I can't dodge it with a vague, noncommittal answer. Pin me down.
Some ground rules:
- Never open with praise, agreement, or "great question." Ever. If you catch yourself doing it, delete it.
- Never soften a critique with "but you're on the right track" or "to be fair." Say the hard thing and let it land.
- If my plan is genuinely solid, don't applaud it — stress-test it harder. Find the failure mode I haven't considered.
- No motivational clichés. No "unlock your potential." No "you've got this." Concrete language only.
- Keep it tight. A short, precise hit lands harder than a long lecture.
- Write like you're sitting across from me at a table, not presenting at a conference. Be direct, be real, skip the fluff.
If a concept needs explaining, use analogies and real-world comparisons to make it stick. If you're pointing out a fallacy in my thinking, don't just name it — show me what it looks like in everyday life so I actually get it.
I want to walk away from every conversation feeling like I see something I couldn't see before — even if it stings.
---
The full Claude 101 guide on this article:

Ruben Hassid@rubenhassid
English
@michaelchchoi Could you please share any related references you're aware of, such as arXiv papers or similar resources on this topic?
English

2026 means updating the @huggingscience heatmap 🔥
Tracking all the orgs making open science releases, and I just added @instadeepai + @pranamanam's lab.
Check out all the cool stuff being released on the Hub (or lmk who I missed)

English

Happy New Year inventors and hustlers! 🥳💡🚀✨💫
Reminder: The USPTO (and I) want you as a solo inventor / small team against big guys! 🫵😎
🌟 tl;dr Make your New Year’s Resolution to submit the provisional patents! 👩🏻💻💡✍️👩🏻⚖️📜
You have a good idea! 🧠💡💪
It’s only $65 and upside is thousands or millions. 💸💸💸
🌟 And make some figures to strengthen it! 👩🏻🎨✍️
===
Solo inventors and small teams are often told at a disadvantage in patents and business. 😔
🌟In reality, the USPTO was designed to support solo inventors and small teams as much as possible — but many people still hesitate to file because they’re unsure their idea is “good enough.”
It usually is.
👩🏻💻🤖🦾 One of the biggest shifts in recent years is how LLMs empower individuals, not just large companies, especially in IP and early-stage business.
🌟Text and claims matter, but even before AI, many people could:
•use templates,
•reference public patents,
•or draft basic descriptions themselves.
🚨The real bottleneck has always been figures.
🌟Figures aren’t required for provisionals, but they dramatically strengthen them. They help you explain ideas concretely, not just theoretically, and let solo inventors compete with large companies that have in-house teams.
😳 Before AI, professional patent drawings could easily cost $500–$1,000 per black-and-white figure. Easily $5,000 or more. 🤯
🌟 So even though a provisional filing fee is only $65, many inventors skipped figures, making their applications weaker by necessity, not by choice. ❌✍️👩🏻🎨
That has changed! 🤩
👩🏻💻🤖🦾👩🏻🎨🖼️ Image generation and AI-assisted tools now let solo inventors create strong, clear figures themselves, which fundamentally shifts the playing field.
This is exactly what I’m working on:
systems and methods to help inventors strengthen provisionals, especially through better figures, so they can compete on substance, not budget.
🌟🙂↔️ And importantly, following Thaler and the USPTO’s November 2025 clarification, AI is treated as a tool, not an inventor.
🌟💁🏻♀️ The focus remains on human conception, control, and decision-making, which further supports solo inventors using modern tools.
The gap is closing and that’s a good thing. 😎🚀✨💫
English
Excellent post! The only real benchmarks in biology is if it works in the wet lab. 👩🏻🔬🔬
🎯 And generally b/c people say they’re using it to “cure all diseases,” the only benchmarks that matter are:
1.) Does it work and is it safe in humans at physiologic doses?
2.) Was it cheaper and faster than traditional R&D?
❌🤖💊💉I personally also would not call the drugs in human studies completely AI discovered in the way that the general public would think of what “discovery” is. It’s generally sophisticated brute force drug repurposing. When you say discovered, people generally think this did not exist at all and then now it does.
🌟 Rentosertib from Insilico is probably the only one that fits this “discovered” definition, but still not magical in the way people think. Humans very involved
🌟 Alex doesn’t say this, but generally if you hear “AI discovered a drug” people seem to be implying you pushed a button and then a drug works in a human the next day. 🧐
People treat it as a failure to have or truthfully say the human’s role in AI. I think it’s good to have humans involved (Leviathan framework) if it makes things more effective and efficient. The goal is to make effective and safe drugs quickly and cheaper; not to buy compute! 👩🏻⚕️👩🏻🔬💁🏻♀️
English

Everyone’s hyped about “AI for Science.” in 2025! At the end of the year, please allow me to share my unease and optimism, specifically about AI & biology.
After spending another year deep in biological foundation models, healthcare AI, and drug discovery, here are 3 lessons I learned in 2025.
1. Biology is not “just another modality.”
The biggest misconception I still see:
“Biology is text + images + graphs. Just scale transformers.”
No. Biology is causal, hierarchical, stochastic, and incomplete in ways that language and vision are not.
Tokens don’t correspond cleanly to reality.
Labels are sparse, biased, and often wrong.
Ground truth is conditional, context-dependent, and sometimes unknowable.
We’ve made real progress—single-cell, imaging, genomics, EHRs are finally being modeled jointly—but the hard truth is this:
Most biological signals are not supervised problems waiting for better loss functions.
They are intervention-driven problems. They demand perturbations, counterfactuals, and mechanisms, beyond just prediction.
Scaling obviously helps. But without causal structure, scaling mostly gives you sharper correlations.
2025 reinforced my belief that biological foundation models must be built around perturbation, uncertainty, and actionability, not just representation learning.
2. Benchmarks are holding biology back more than compute is.
Let’s be honest: Benchmarking in AI & biology is still broken.
Everyone reports SOTA. Everyone picks a different dataset slice.
Everyone tunes for a different metric. Everyone avoids prospective validation.
We’ve imported the worst habits of ML benchmarking into a domain where stakes are much higher. In biology and healthcare, a 1% gain that doesn’t transfer is worse than useless—it’s misleading.
What’s missing isn’t more benchmarks. It’s hard benchmarks:
•Prospective, not retrospective
•Perturbation-based, not static
•Multi-site, not single-lab
•Failure-aware, not leaderboard-optimized
If your model only works on the dataset that created it, it’s not a foundation model—it’s a dataset artifact.
In 2026, we need fewer flashy plots and more humility, rigor, and negative results.
3. “Reasoning” in biology is not chain-of-thought.
There’s a growing tendency to directly apply the word reasoning onto biological LLMs.
Let’s be careful.
Biological reasoning isn’t verbal fluency, longer context windows, or prettier explanations. Those are surface-level improvements. Real reasoning in biology shows up elsewhere: in forming hypotheses, deciding which experiments to run, updating beliefs when perturbations fail, and constantly trading off cost, risk, and uncertainty.
A model that explains a pathway beautifully but can’t decide which experiment to run next is not reasoning, it’s narrating.
2025 convinced me that the future lies in agentic biological AI:
systems that couple foundation models with experimentation, simulation, and decision-making loops.
Closing thought:
AI & biology is not lagging behind AI for code or language. It’s just playing a harder game.
The constraints are real. The data is messy. The feedback loops are slow. The consequences matter.
If 2025 clarified anything for me, it’s this:
We won’t make progress by treating biology like text. We’ll make progress by building AI that behaves more like a scientist : skeptical, iterative, and willing to be wrong.
Onward to 2026.

English

The first one only in the aspects of formal homotopy and homologies taken as mere algebraic objects. Algebraic topology is hard from the point of view of transforming geometric/topological intuitions into actual ideas for rather complicated dry algebraic proofs. I don't see how this can be trained yet (abstract world models?) For the latter, Mathlib has already a very strong component of analysis. But I am not sure if enough very foundational work regarding standard and non-standard analysis has been done (definitions and basic propositions) to carry one with the fractional calculus. On Lean Zulip people discuss a lot these kind of things.
English
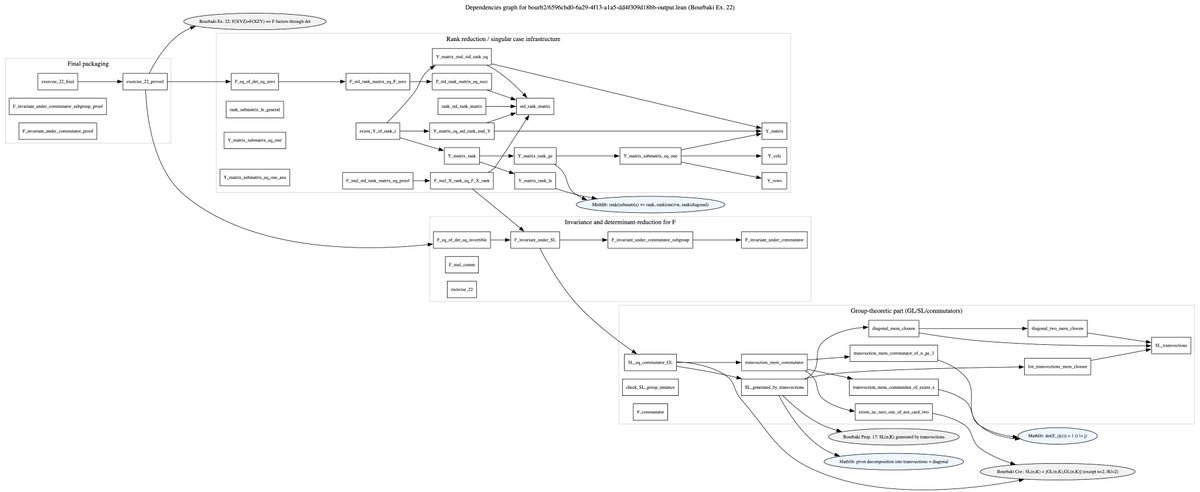
Auto-formalization with Aristotle by @HarmonicMath and reverse engineering with @OpenAI GPT Codex CLI (actually GPT-5.2 with xhigh and all the experimental perks enabled). Working on an exercise from Bourbaki’s Algebra about matrices, I obtained almost 900 lines of fully documented Lean 4 code, including all the details of the proof.
I then passed it-using a suitably designed agentic setup-to Codex CLI to reverse-engineer the corresponding LaTeX file, reconstructing the proof steps directly from Lean, in the style of Leslie Lamport's structured proofs.
This is not the Langlands program yet, but we do need this kind of intermediate-level mathematics to be automated. And this is happening now. I simply built the right agentic setup, pipelined everything, and scraped the text from Bourbaki (even that part worked well with @grok 4.1 which is cool for previewing LaTeX live).
I will finish the documentation and post it on GitHub. Check the dependency graph-Aristotle handled it all by itself. And the proof is fully interactive.
We are living in the future of science now!



English

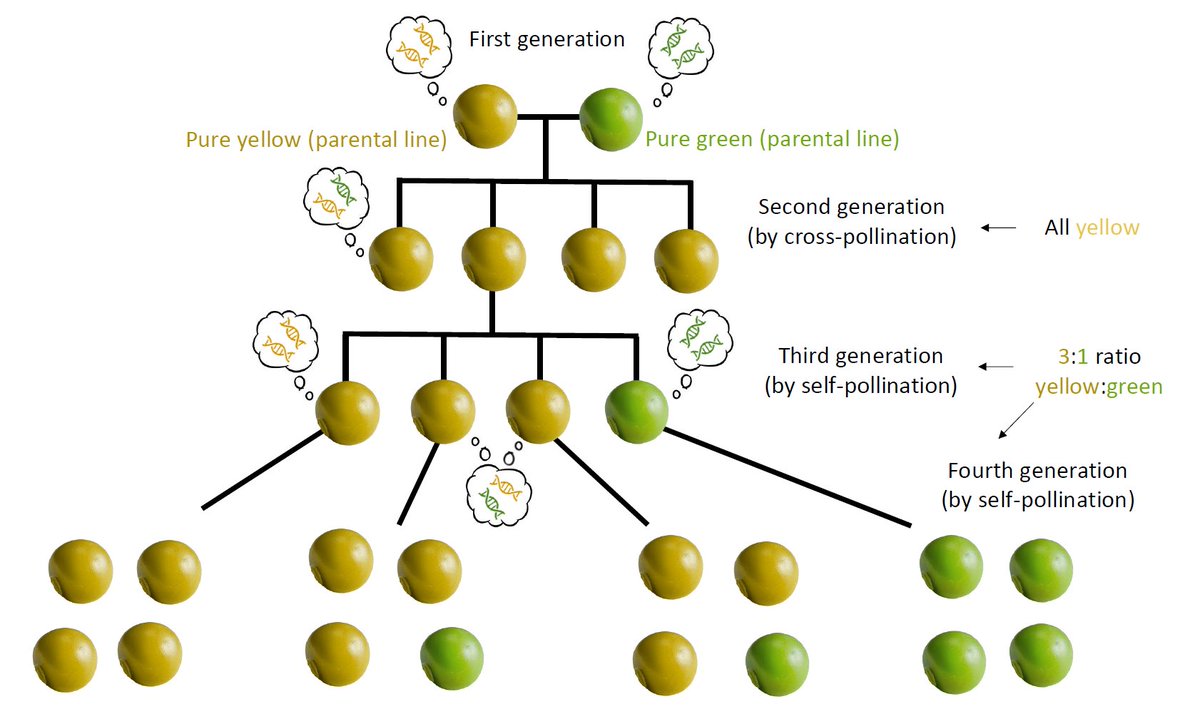
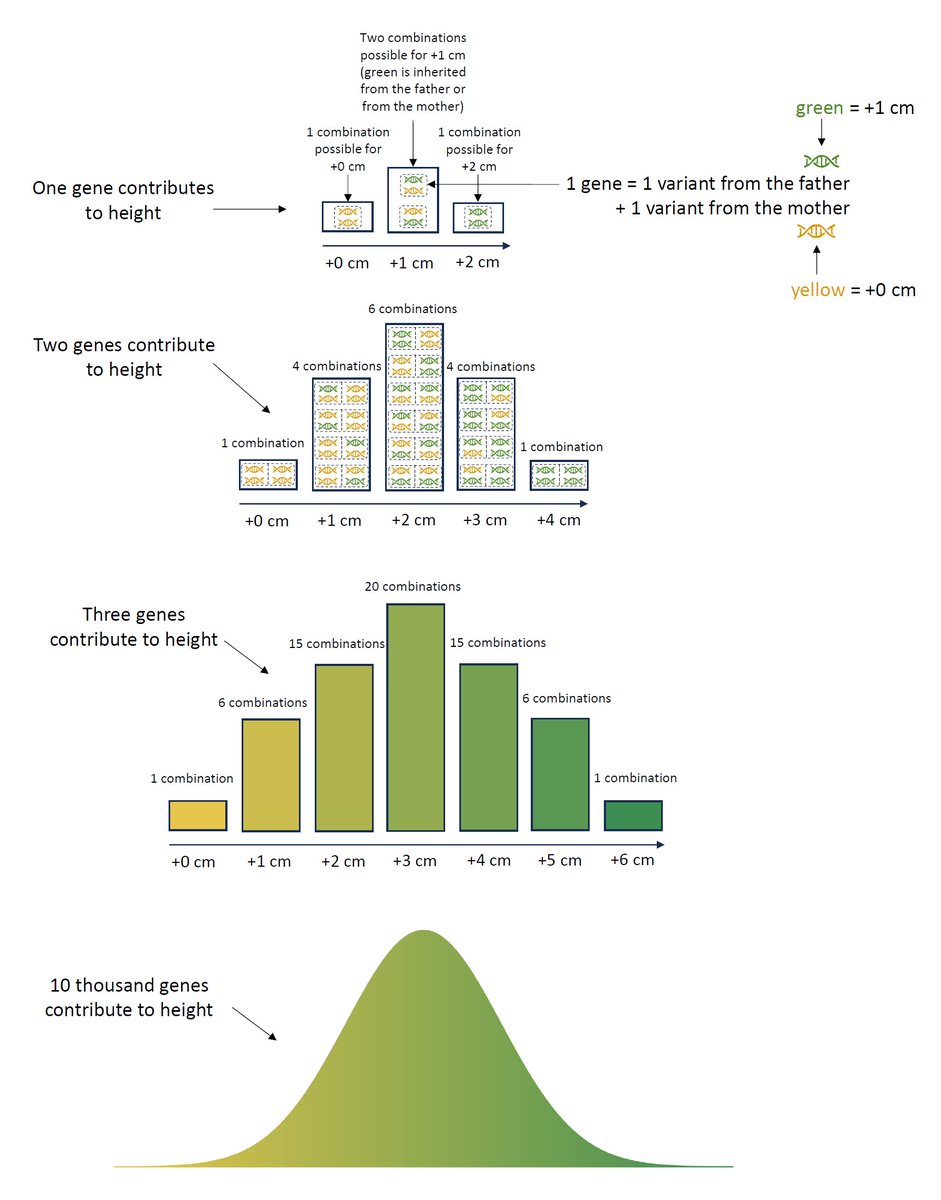
I'm working on some figures for my book to illustrate the foundation of quantitative genetics, confirmed by GWAS.
Mendel showed discrete inheritance in peas (left figure, 1860s).
Fisher showed that many such Mendelian effects yield continuous traits (right figure, 1918).
English

I wrote a short essay on what I'm calling the AI Attribution Error. 1/ (link in thread)

English
✨ USPTO news dropped over Thanksgiving. 🦃👩🏻⚖️💡📰
The USPTO rescinded 2024 guidance on AI inventorship. Link in reply.
Great news for solo inventors (based on recent Thaler precedent that AI can’t be an inventor) 💁🏻♀️💡
Pannu still applies before patent granting for patent applications with multiple human inventors. 👨🏻👩🏼🦰👱🏽♂️👩🦳💡❓🧐
This is mostly a practical matter. Not enough USPTo examiners and it’s not their job to do forensics on every application or be detectives. ❌🕵🏻♀️
It shifts burden of evaluation of human / AI inventorship to PTAB and Litigation. 👩🏽🦱💼 vs. 👨🏼🦰👨🏻💻💡
❓👨🏻🤖💡👩🏻⚖️💸
English
Based on the Efficacy and Safety of GLP-1 Medicines for Type 2 Diabetes and Obesity doi.org/10.2337/dci24-…

English


AA01 retweetledi

Just watched @Saman_Habibi_E Lecture of the complex & algebraic geometry series on YouTube. The pedagogy is incredibly high and the lucidity in explaining these complex topics is outstanding. A must-watch for anyone interested in pure math / complex geometry / algebraic geometry!
Saman Habibi Esfahani@Saman_Habibi_E
Lecture 5 (part 1) in my beginner series on complex & algebraic geometry is up on YouTube. If you’re into pure math / complex geometry / AG, you might enjoy it. youtube.com/watch?v=qaazyR…
English