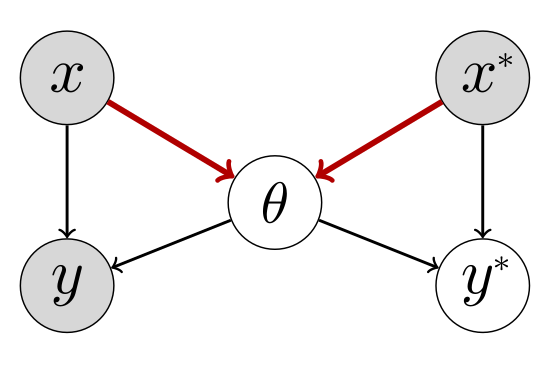
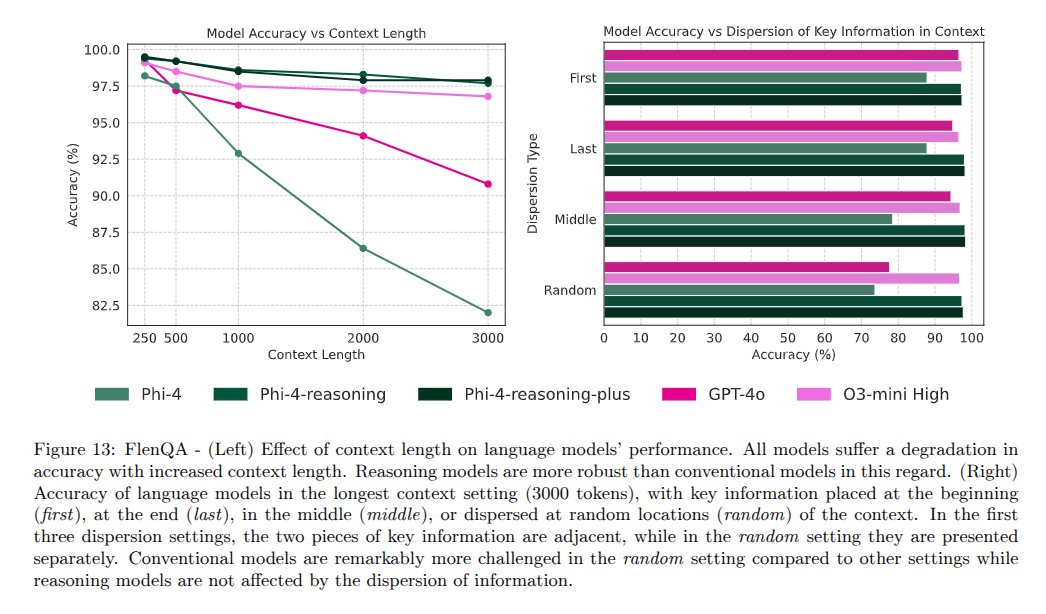
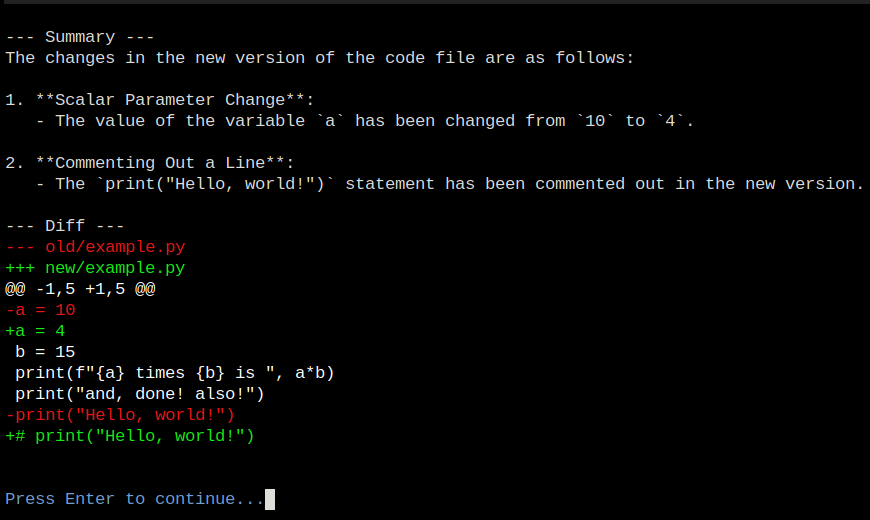
Sabitlenmiş Tweet

New findings: We just evaluated Gemini 1.5 Pro on our recent benchmark that tests the impact of context size on reasoning performance - it is much better than 1.0 in long contexts! Though still falls behind GPT4. Also, CoT prompting now improves accuracy (unlike with 1.0).
(1/4)
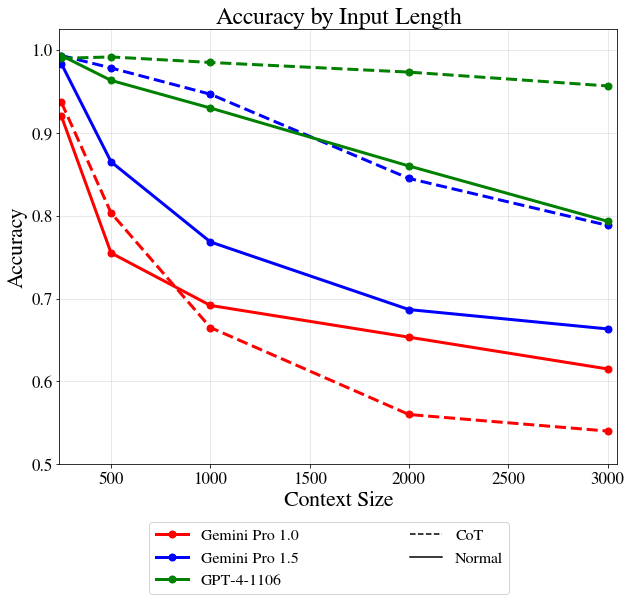
English