
Daedevils
693 posts

Daedevils
@AndreSeverini
📜 Electrotechnician 🎓 Automation and Control Engineer From @polimi 💻 #JS #React #Python #PineScript #Solidity 🎯 #Web3 🛠️ Building @jethos_ with @i8art_
Milano, Lombardia Katılım Aralık 2012
591 Takip Edilen251 Takipçiler


@XFreeze Yup 😂
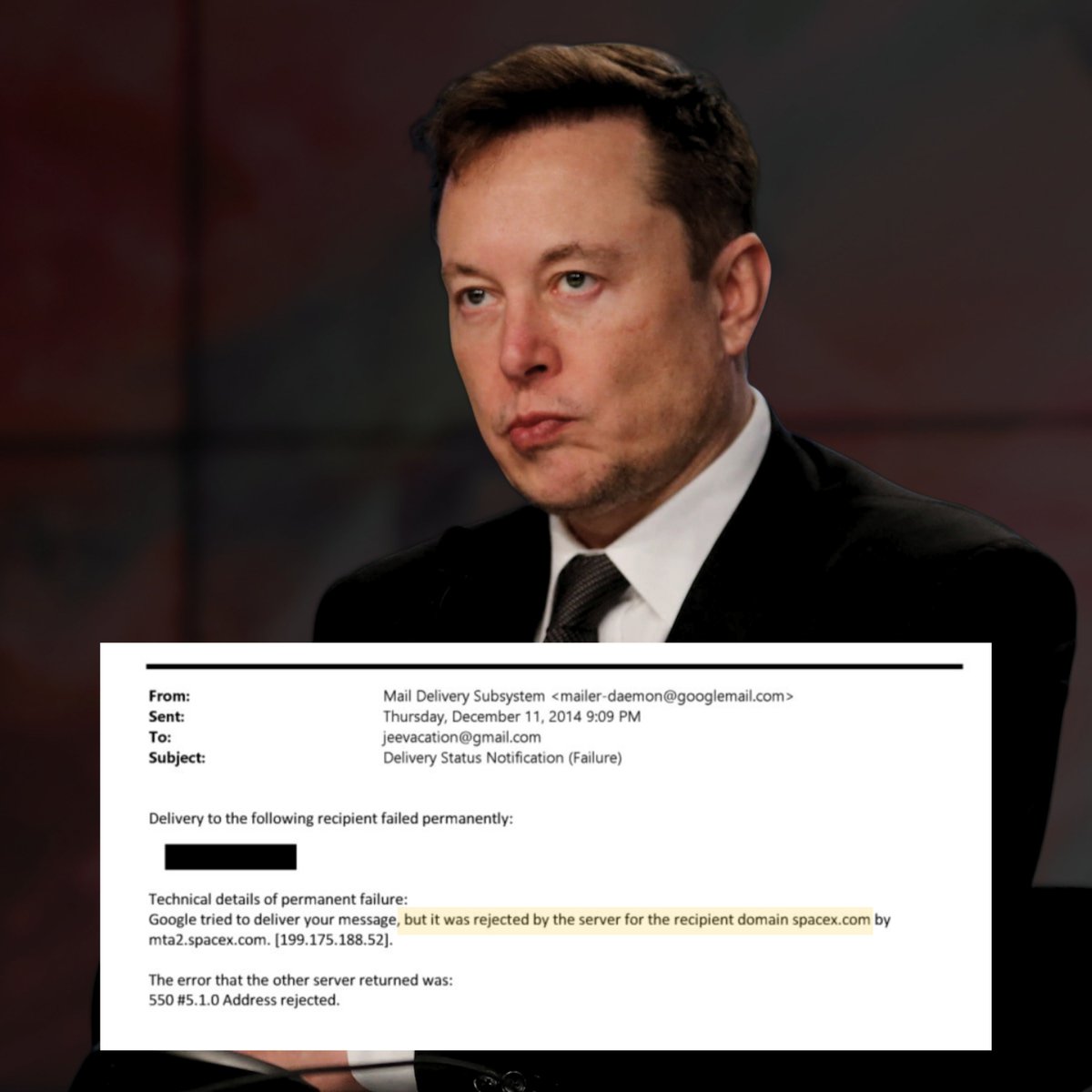
That really made him upset. After I ghosted him, Epstein went on a massive campaign to short Tesla and got Gates to short 1% of Tesla stock when the market cap was $40B. As far as I know, Gates still has the short open.
Someone should ask him how that’s working out 🤗
English




@TheAhmadOsman Working few days on skill right now, actually getting some pretty good results on codebase analisys and milestone planning
English

i changed my opinion on Skills btw
spent a good chunk of today experimenting with them
SO MUCH can be UNLOCKED with Skills
brilliant LLM automation hack
p.s. not gonna let my disdain toward Anthropic & MCPs blind me from seeing the value in sth like this again
English

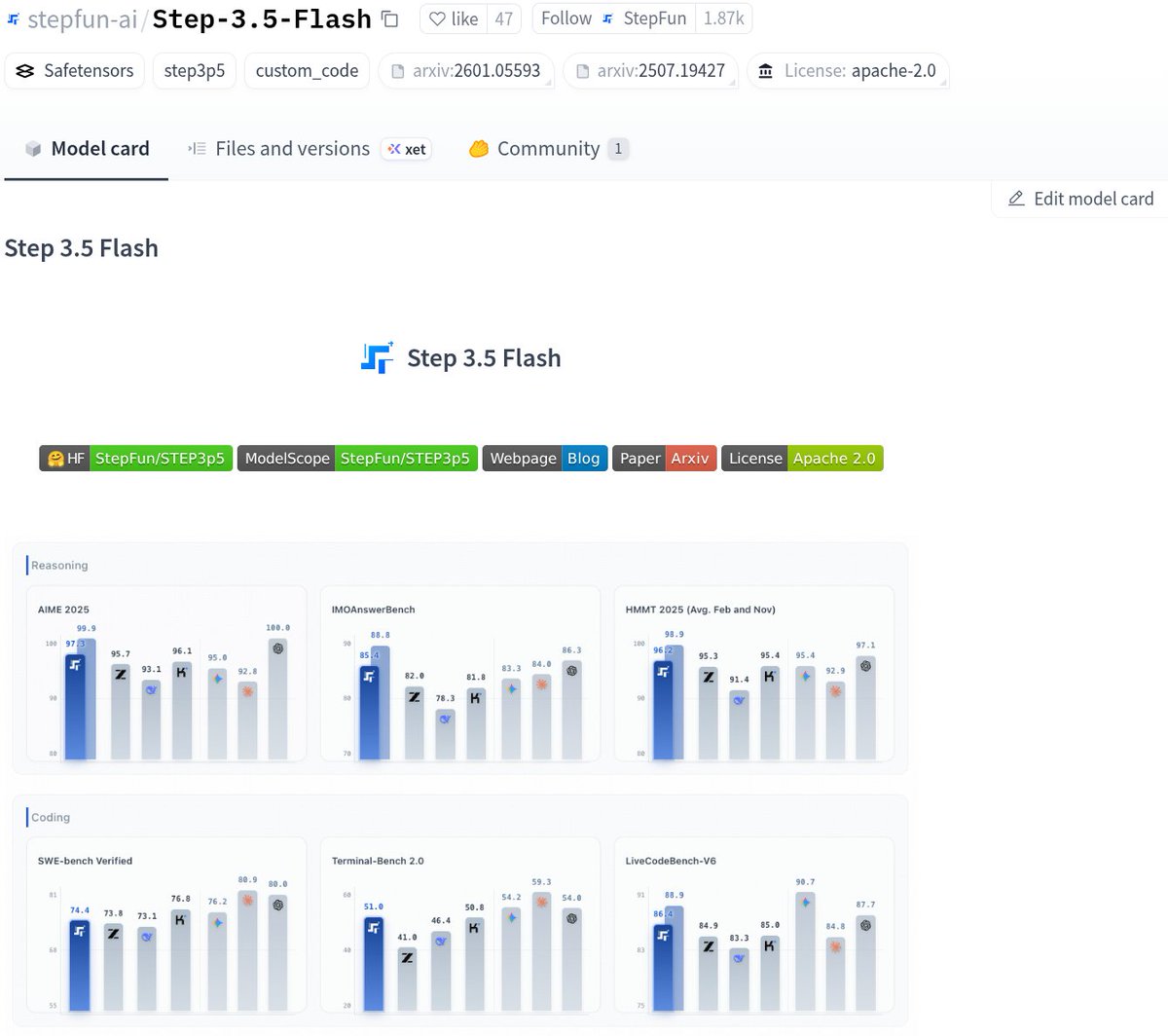
MASSIVE
> Step-3.5-Flash by StepFun
> Agentic & Coding MONSTER
> opensource MoE, Apache-2.0
> runs with full context on
> 2x RTX PRO 6000/8x RTX 3090s
> 196B MoE, only 11B active per token
> 256K context via 3:1 sliding window attention
> long codebases & long tasks, cost-efficient long-context
> benchmarks
> 74.4% SWE-bench Verified
> 51.0% Terminal-Bench 2.0
> strong reasoning, strong coding, stable agents
> sparse MoE + Top-8 routing
> with sliding window attention
> MTP-3 predicts multiple tokens at once
> 100–300 tok/s typical, peaks ~350 tok/s
> fast enough for parallel agents, not just chatting
> apache-2.0
> openweights
> runs locally
> Macs, DGX Spark, GPUs
> vLLM, SGLang, Transformers, llama.cpp
> this is what “Buy a GPU” tried to warn you about
starting to believe yet, anon?
— Buy a GPU, The Movement
Ahmad@TheAhmadOsman
Prediction We will have Claude Code + Opus 4.5 quality (not nerfed) models running locally at home on a single RTX PRO 6000 before the end of the year
English
@TheAhmadOsman Agree, actually running it on a single 4090 with qwen3-coder. Not that bad
English
Daedevils retweetledi

A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
English
Daedevils retweetledi

Extreme close-up of an integrated chip under a microscope.
A microscopic object doing an absolutely ridiculous amount of work.
English
Daedevils retweetledi


Everyone is sleeping on this new paper from AWS.
A model 100x smaller than GPT and Claude crushed them on tool calling.
AWS researchers took Facebook's OPT-350M, a model from 2022 with 500x fewer parameters than GPT, and fine-tuned it on ToolBench for a single epoch.
The results are wild:
↳ Their SLM: 77.55% pass rate
↳ ChatGPT-CoT: 26%
↳ ToolLLaMA: 30%
↳ Claude-CoT: 2.73%
Here's what's happening:
Large models suffer from "parameter dilution." Most of their capacity is optimized for general language tasks, not the precise Thought-Action-Action Input patterns that tool calling needs.
A small model trained specifically on tool calling concentrates all its capacity on that one thing. No distractions.
The training setup was surprisingly simple. Hugging Face TRL, 187K examples, learning rate of 5e-5, and aggressive gradient clipping for stability.
But I want to be clear on something:
This doesn't mean small models win everywhere. The authors acknowledge their model may struggle with complex contextual nuances or ambiguous requests. It's a specialist, not a generalist.
Still, if you're building agentic systems and want to cut inference costs by orders of magnitude, this is worth paying attention to.
I've shared link to the paper in the next tweet.

English

As Larry Ellison $ORCL says, all AI models—ChatGPT, Gemini, Grok, Llama—are trained on the same publicly available internet data.
It’s no surprise AI models are becoming commoditized.
To reach peak value, models need to be trained on privately owned data.
In this scenario, the most important moat is clear: proprietary data.
A company with a ton of unique, exclusive data will capture the entire market.
English




Daedevils retweetledi

claude code is fucking insane
i know literally NOTHING about coding. ZERO. and i just built a fully functioning web app in minutes
http://localhost:3000/
check it out
English


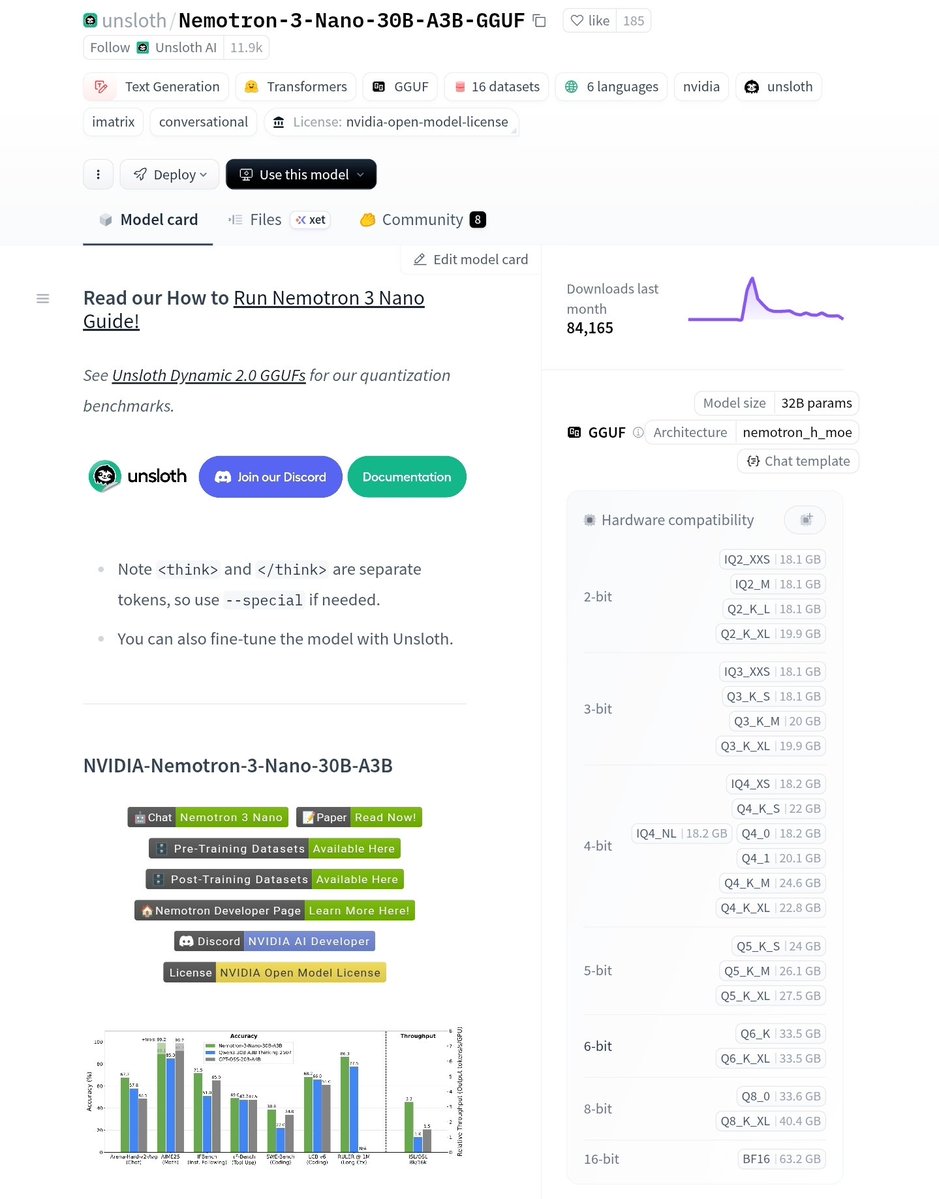
If you haven’t tried a local LLM in a year+
I’m telling you, try Nemotron 3 Nano
it’ll run on a potato GPU
thx to experts offloading
it’ll even run fully on CPU + RAM
Just a preview of AI living on your machine, and it’s the worst it’ll ever be
Unsloth has good quants & sizes
English