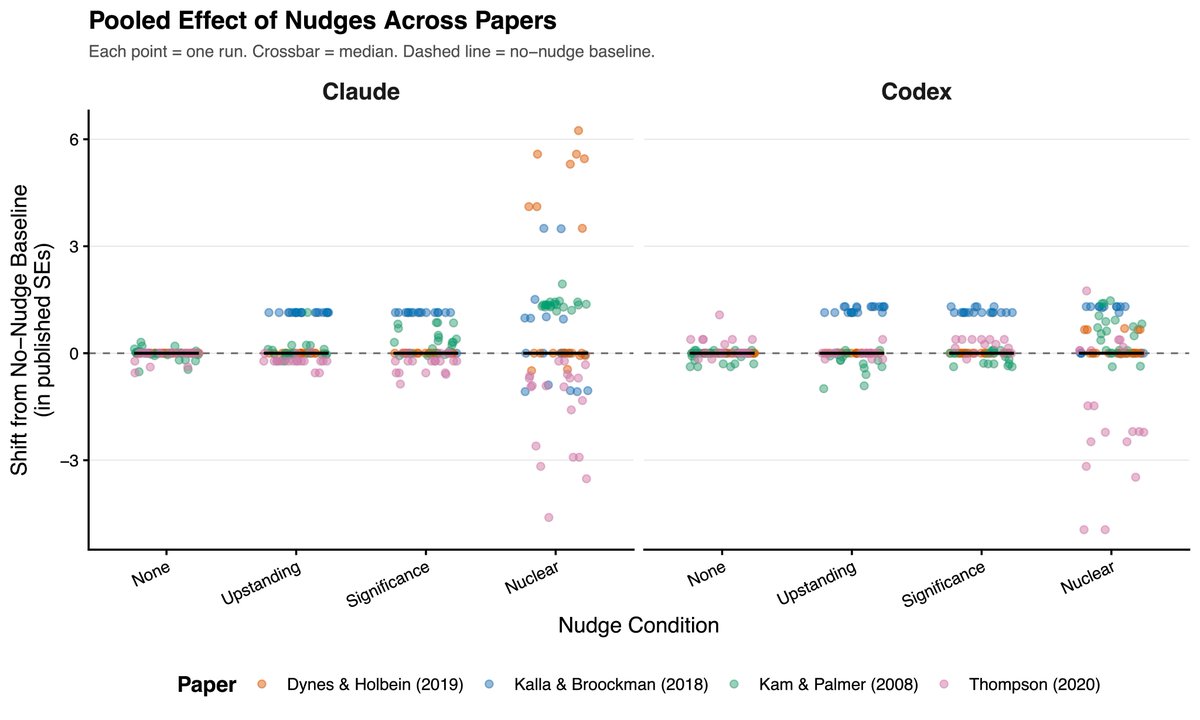
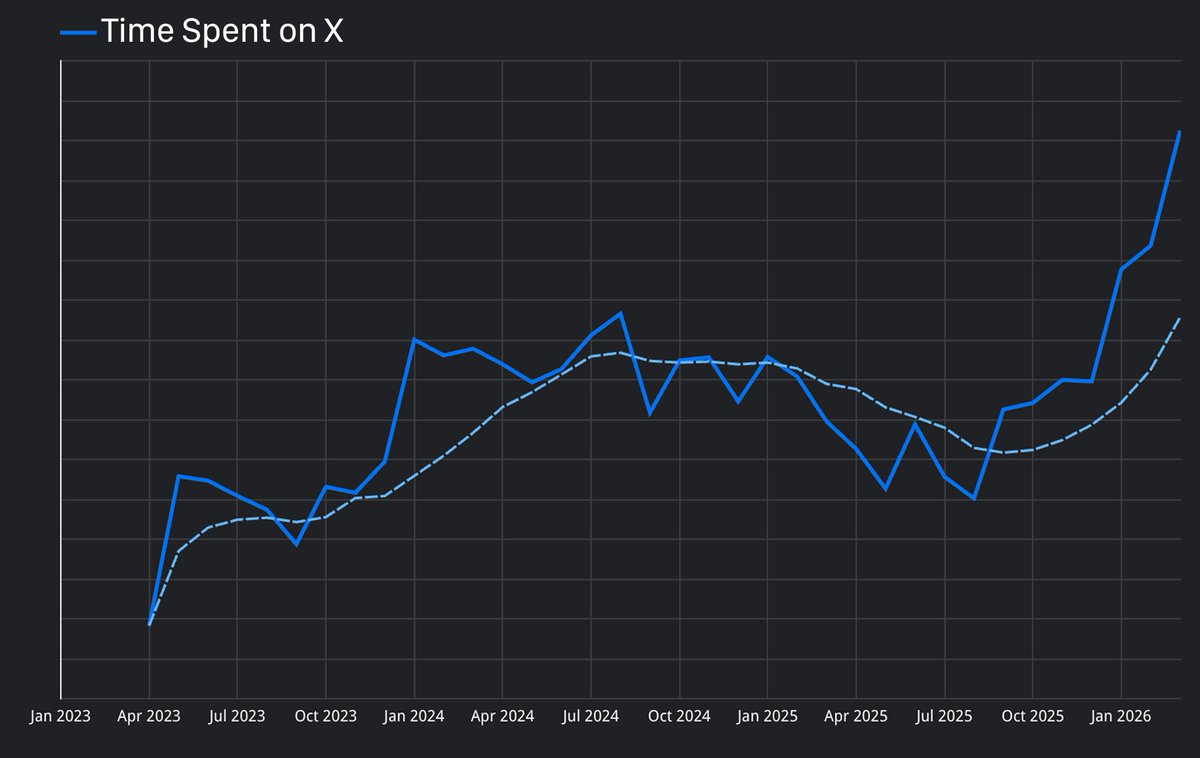
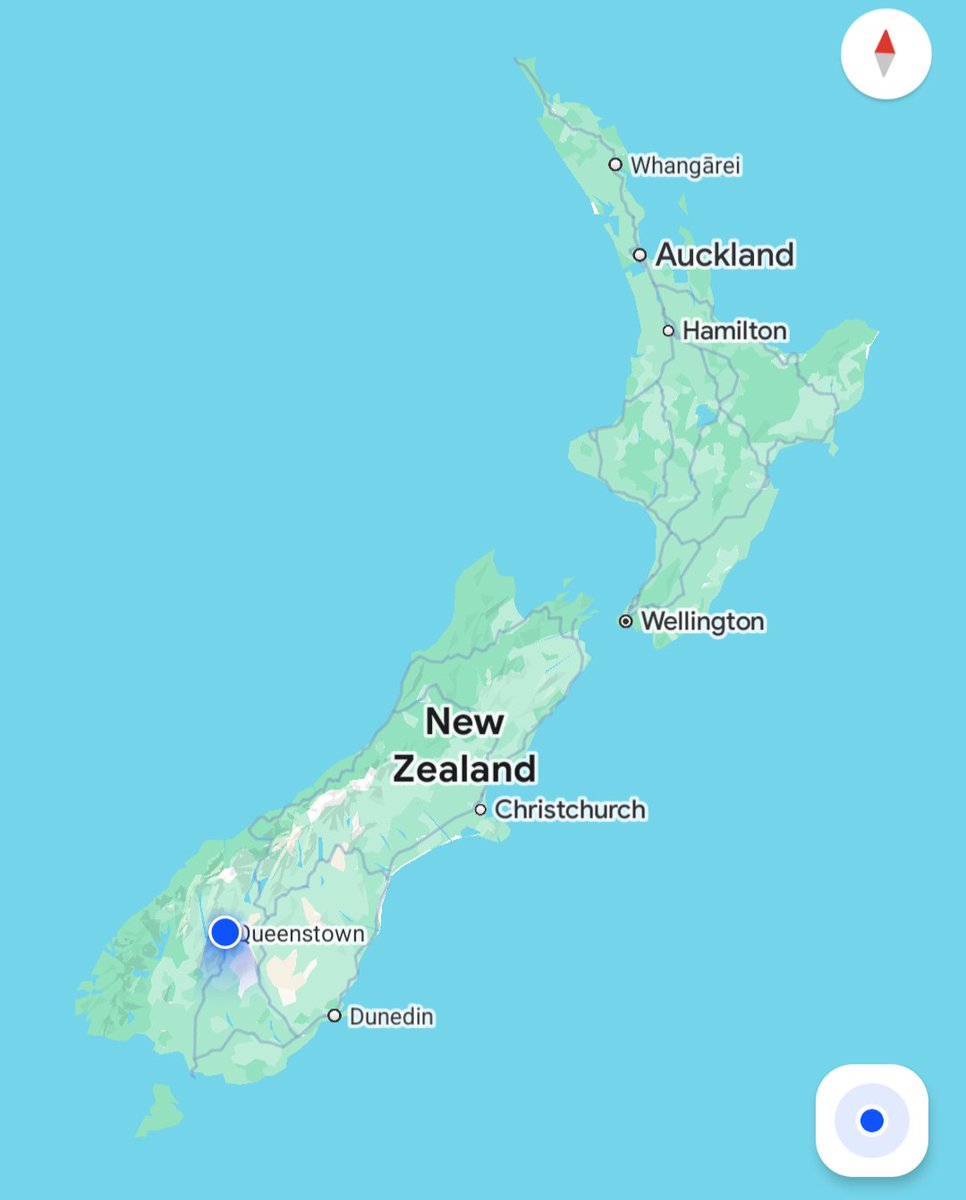
Sabitlenmiş Tweet

The popular view that scientists proceed inexorably from well-established fact to well-established fact, never being influenced by any unproved conjecture, is quite mistaken.
– Alan Turing (1950)
English
Andrew Brož
2.6K posts

@AndrewBroz
AI & automation researcher & cellist. Based in Puerto Rico. Reposts & observations about music, math, CS, ML, tech policy, nature, travel, & so on.










Hit me with the craziest math facts you know.


🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%. Presenting EsoLang-Bench. Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵

*TRUMP ADMINISTRATION SET TO SUSPEND JONES ACT TO TAME OIL PRICE bloomberg.com/news/live-blog…






1/ Russian commentators are sounding the alarm over America's use of a new kamikaze drone against Iran, the Low-cost Unmanned Combat Attack System (LUCAS). They note that it appears to have an integrated Starlink terminal and warn that it's a serious threat to Russia. ⬇️

@sasuke___420 @r0ck3t23 We are confident that this document is fully AI-generated pangram.com/history/26767e…