Sabitlenmiş Tweet

Final version of Castlevania 64 Camera Mod.
Now without camera out-of-bounds error.
Patch available at github.com/animaone/castl…
\o/
English
Anima One Ciel 🐧
394 posts

@Anima_C13L
Hamilton Mendes AI,Research,OpenSource,ProGramming,Reverse-Engineering,Art 🏠🇧🇷 ❤️🌎🌏🌍 NOSTR: https://t.co/2ZcOqearsi





Best models to run on your hardware level I'll be doing this every week, I hope you guys enjoy. ---- 8 GB ---- Autocomplete for coding (like Cursor Tab) - huggingface.co/NexVeridian/ze… - huggingface.co/bartowski/zed-… Tool calling, assistant style - huggingface.co/nvidia/NVIDIA-… ---- 16 Gb ---- Here things get better: Multimodal - huggingface.co/Qwen/Qwen3.5-9B - huggingface.co/Tesslate/OmniC… - huggingface.co/unsloth/Qwen3.… ---- 24 GB ---- - The best model you can get (thanks Qwen) huggingface.co/Qwen/Qwen3.5-2… - Great model (strong agents) huggingface.co/nvidia/Nemotro… - Mine hehe huggingface.co/0xSero/Qwen-3.… I'm doing a weekly series



Anime faces look bad in 3D when you zoom too close. You can make the face look better w/ortho cameras... BUT then the hand in front looks too small and the one in back too big. Enter #camkeys custom FOV falloff. Now we don't have to stretch or scale rigs in strange ways as often to get artistically nice faces AND depth. All three shots use a 15mm lens. Camkeys can even change FOV on the character separate from the background so it lookksss ortho! (Coming in the v3.0 update, which is soon)




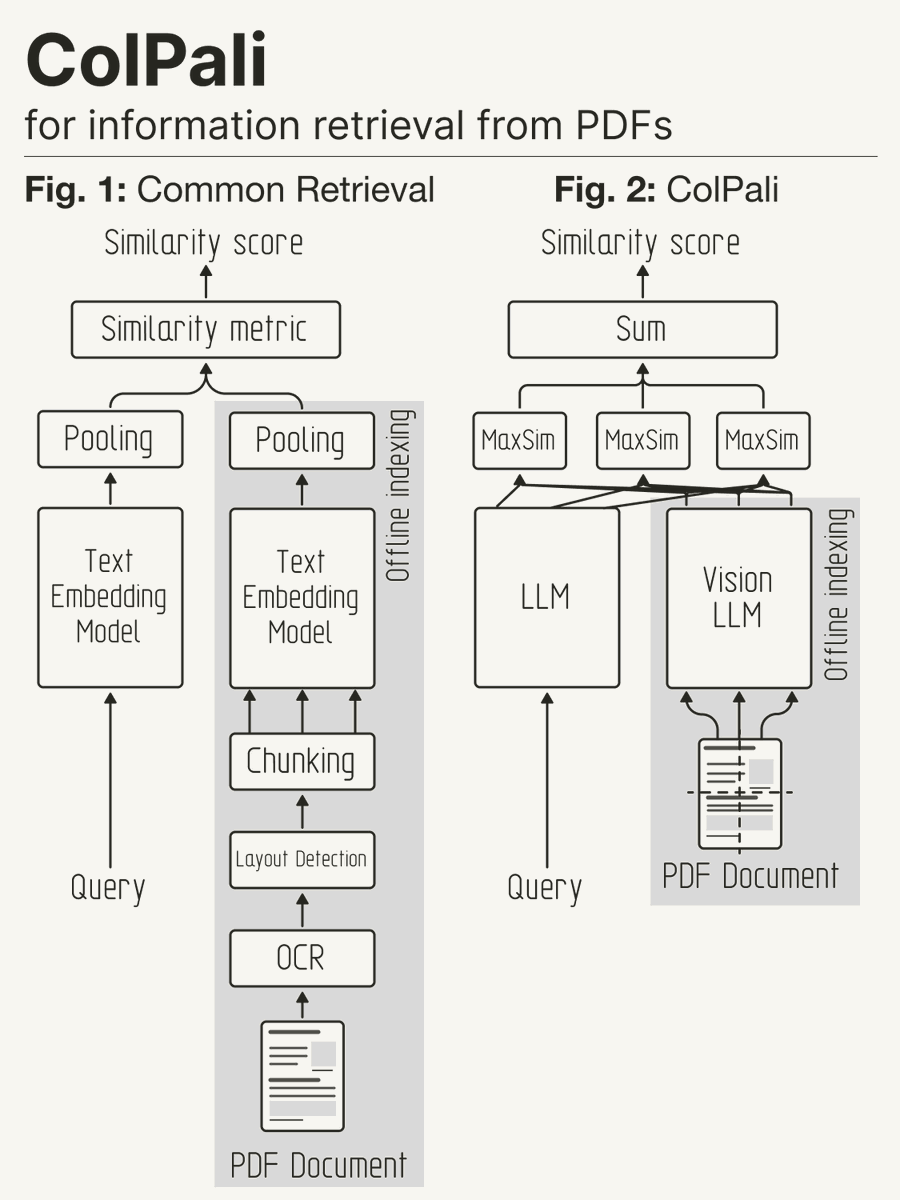


🟢🔵 Geometry nodes for realtime procedural rendering in Unity. Fast, arbitrary mesh generation and animation. #b3d #geometrynodes #gamedev