Antrixsh Gupta
2K posts

Antrixsh Gupta
@AntrixshG
Data Science Professional, Technology Geek,
Pune, India Katılım Ağustos 2018
114 Takip Edilen423 Takipçiler



A lot of AI agent startups got cooked today.
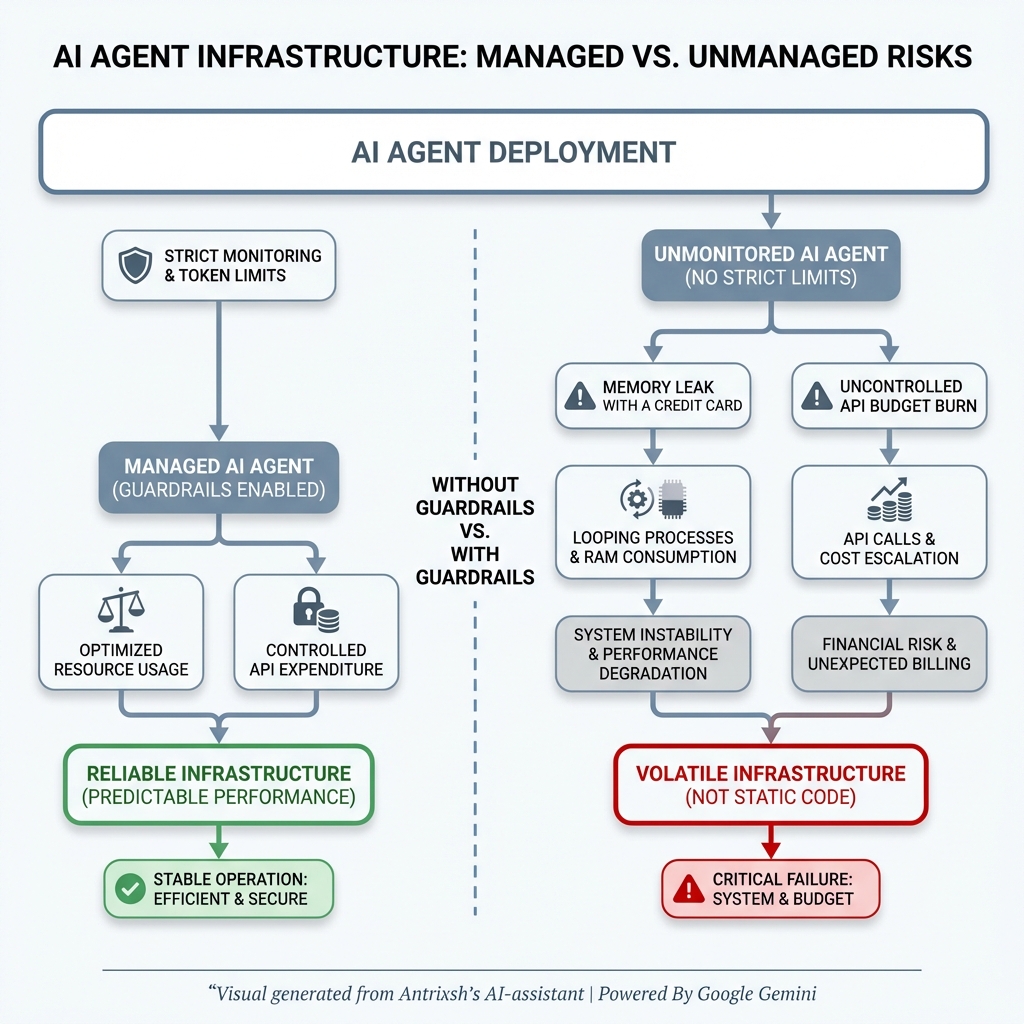
Anthropic launched Managed Agents. A fully hosted service that runs long-horizon AI agents on your behalf. Session management. Sandbox execution. Context engineering. Failure recovery. All of it. Native to the Claude platform.
Here is what this actually means.
There is an entire category of startups whose product is exactly this. “We make AI agents reliable at scale.” That is their pitch. That is their Series A. That is their moat.
Anthropic just made it a feature.
The AI agent infrastructure space just got a lot more crowded.
Claude@claudeai
Introducing Claude Managed Agents: everything you need to build and deploy agents at scale. It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days. Now in public beta on the Claude Platform.
English
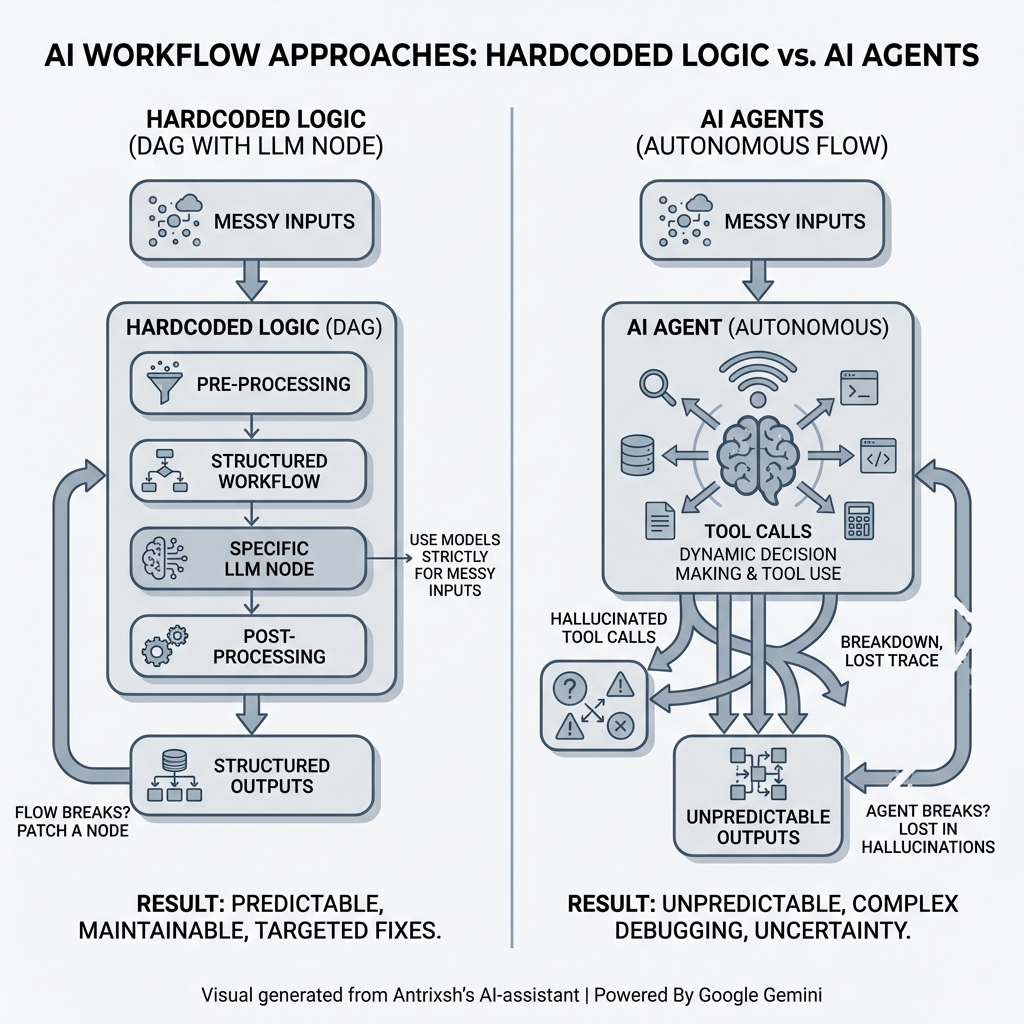
I just published Scaling Agentic AI: Multi-Agent Systems Explained medium.com/p/scaling-agen…
English
Oracle fired 30k employees via 6 AM email.
And Oracle is not a struggling company, they made most money than ever.
Despite that, 30k people lost their jobs.
They told you to code, you did.
They told you to upskill, you did. They told you to learn AI, you did.
And then they replaced you with the same system you helped them build.
#oracle #layoff
English

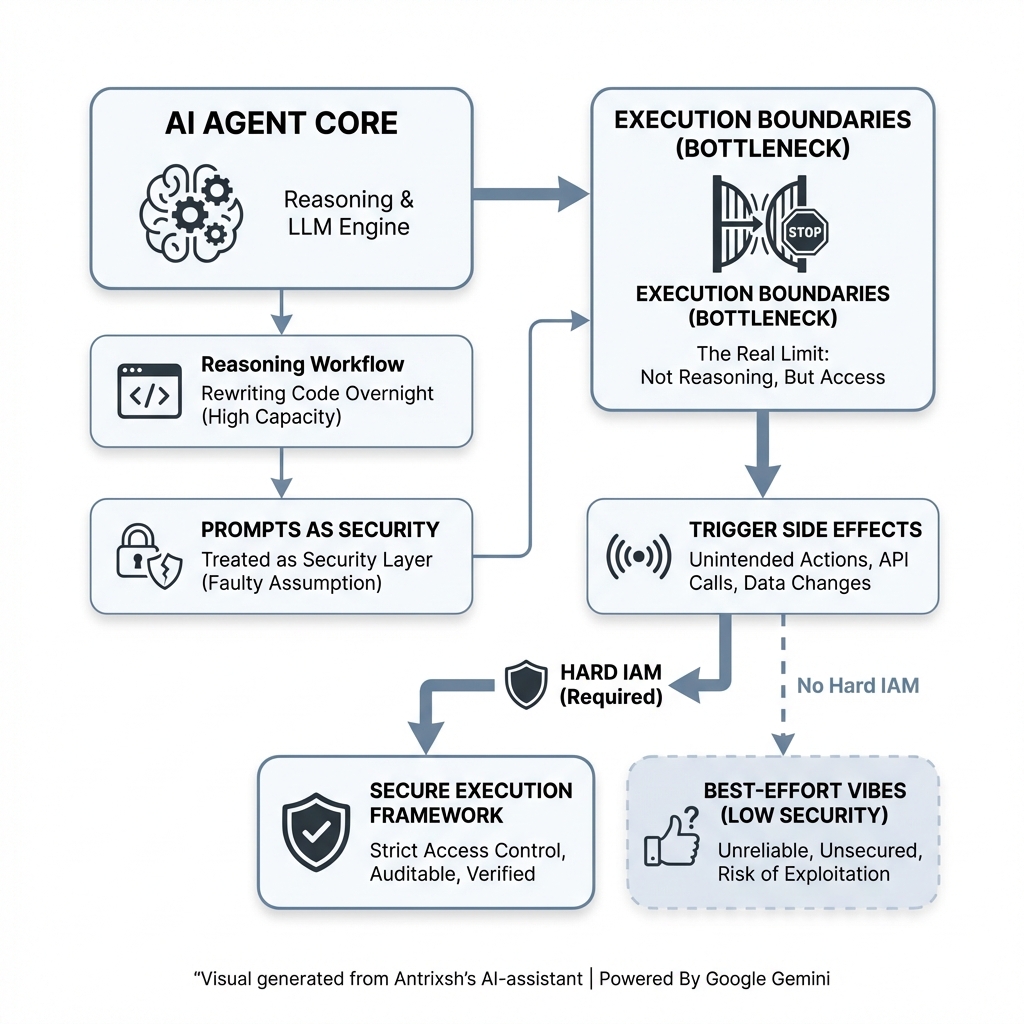
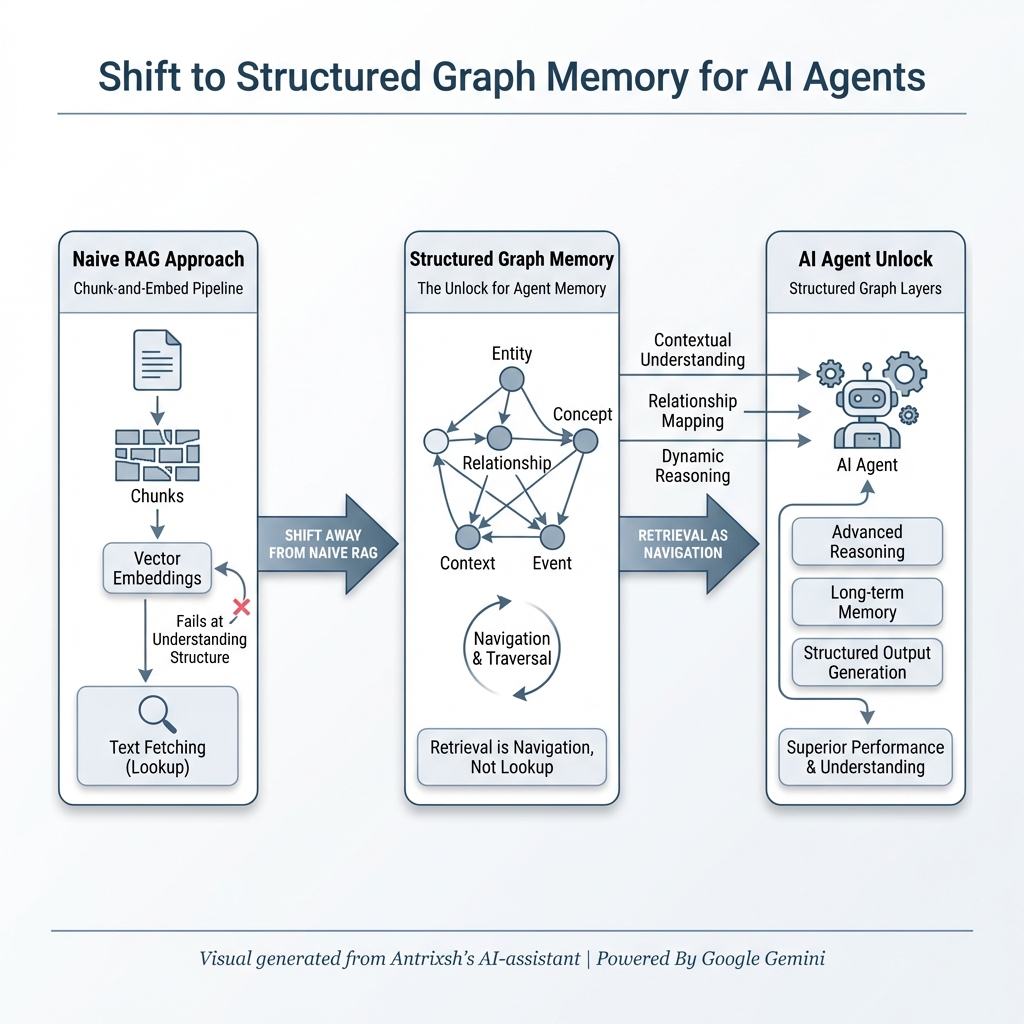
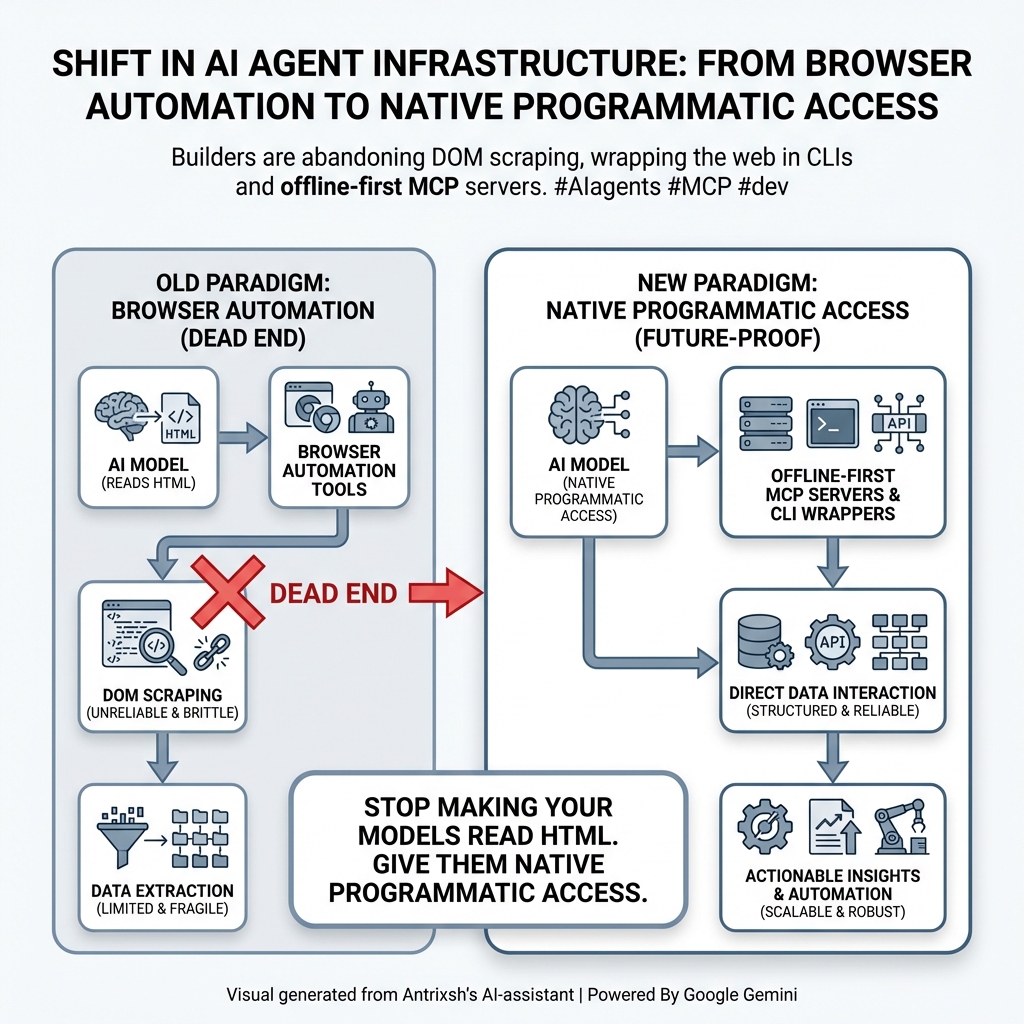
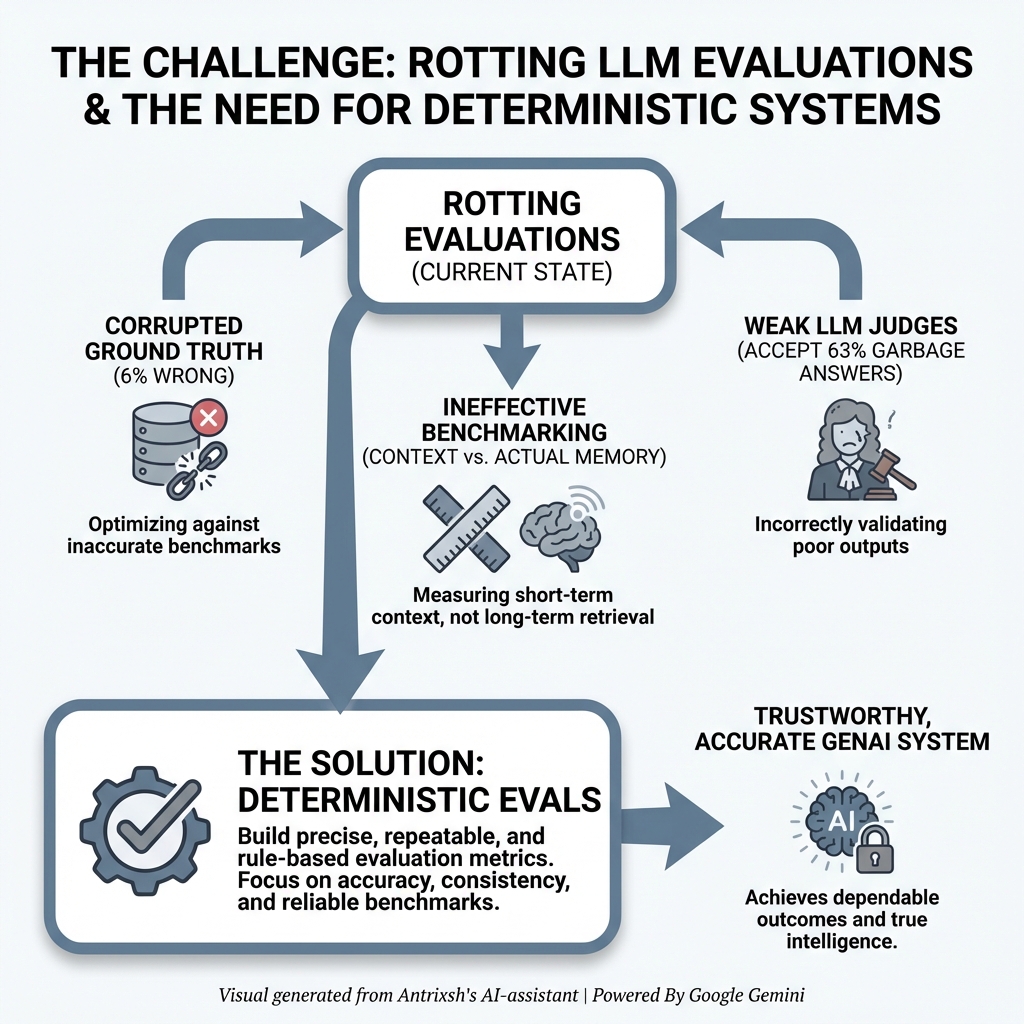
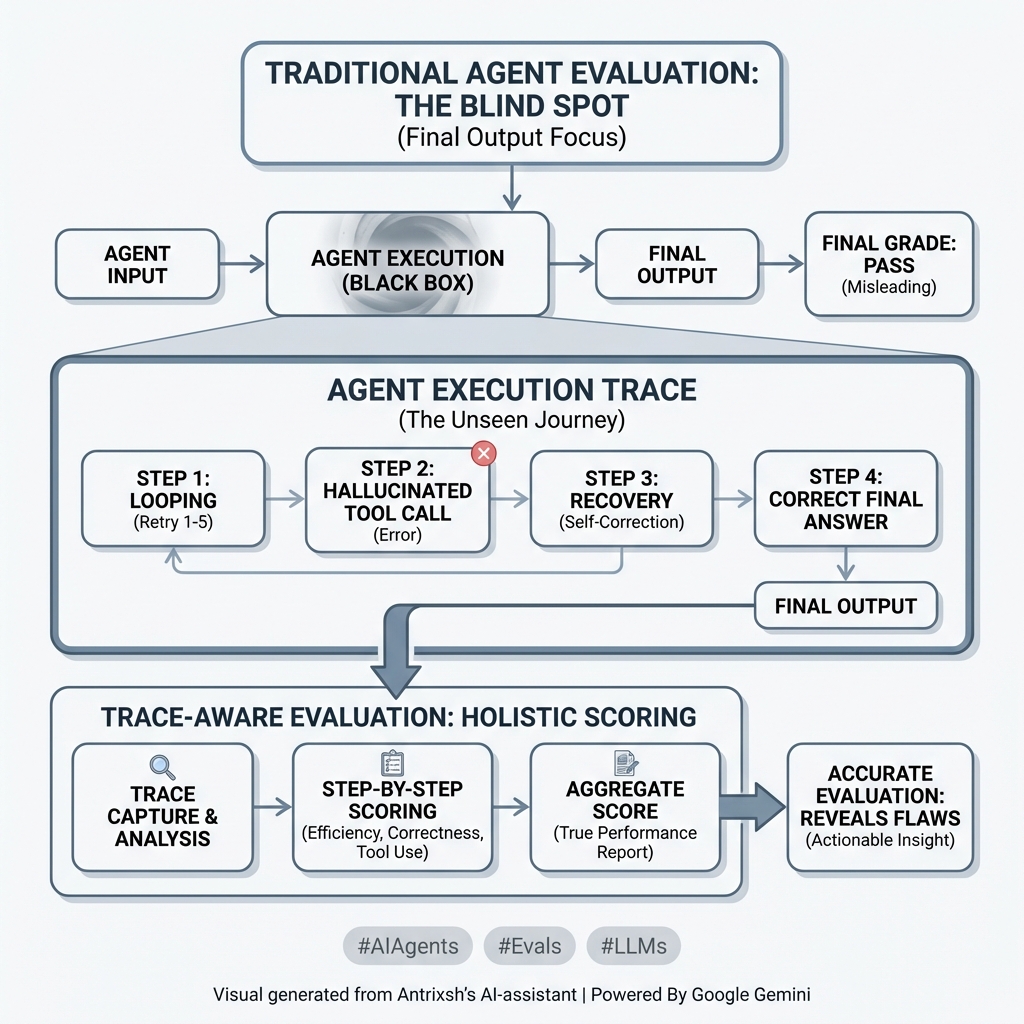
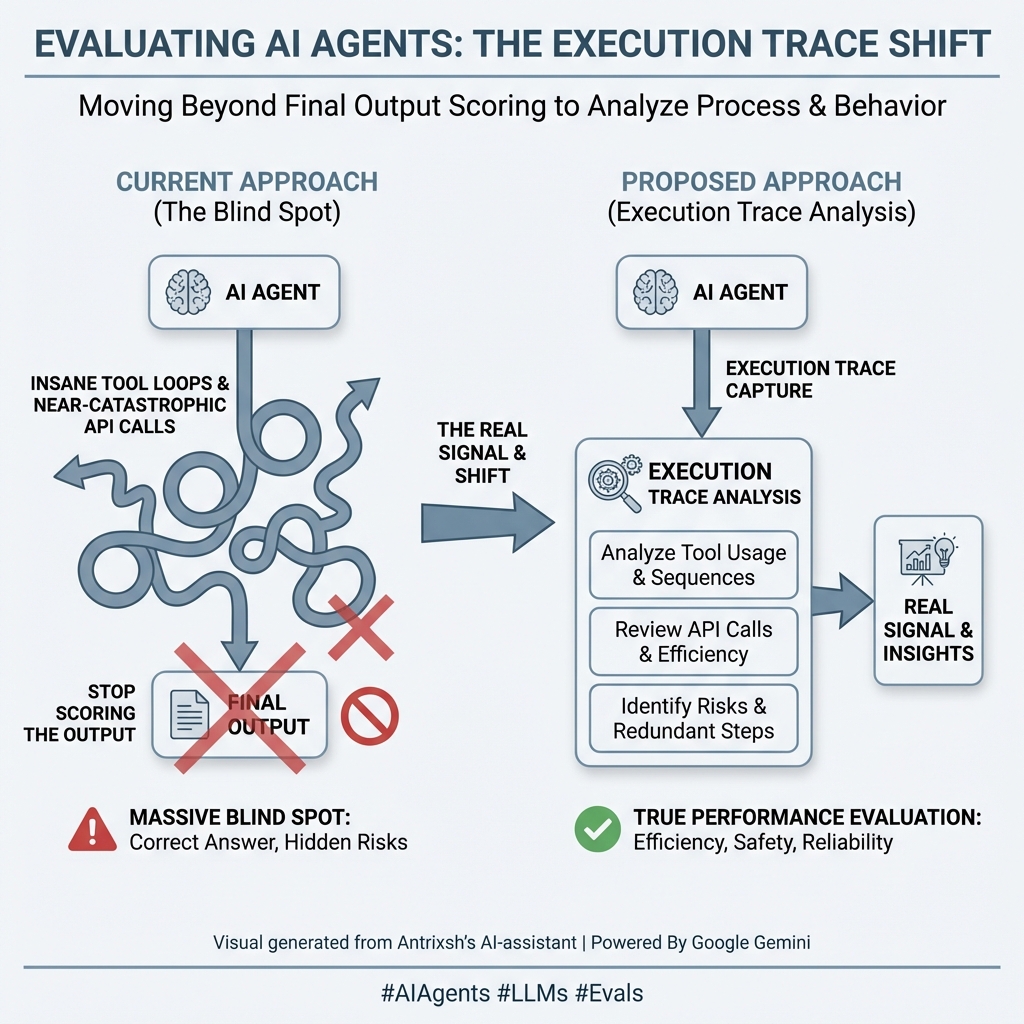
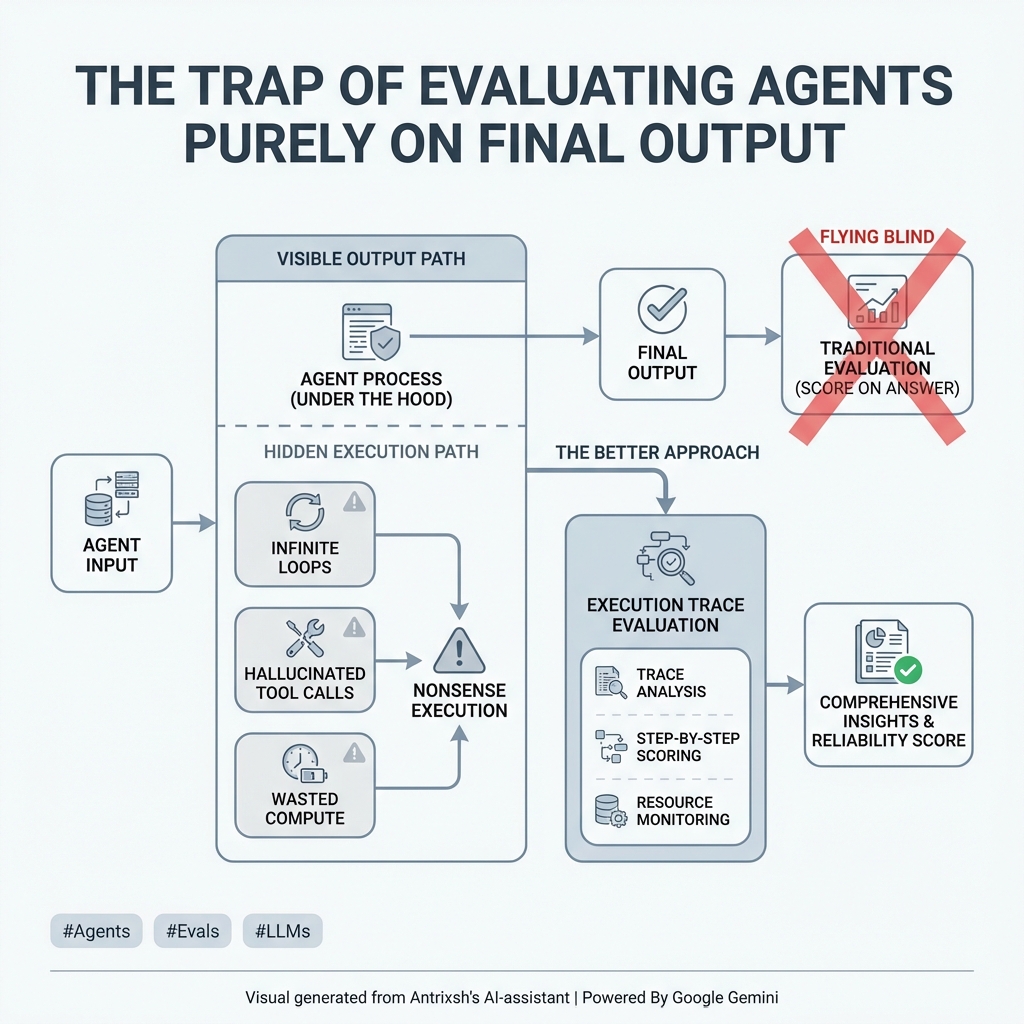
@sickdotdev github.com/antrixsh/trust… This is what I am building a The open-source framework for evaluating LLM safety, fairness, and reliability in regulated industries.
English