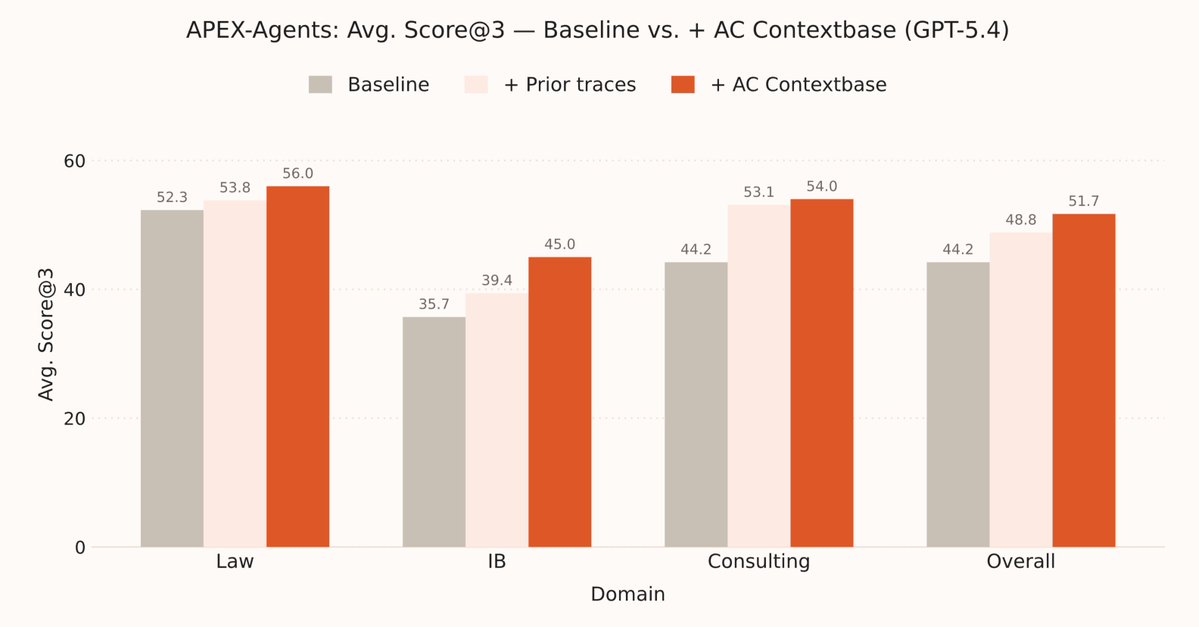
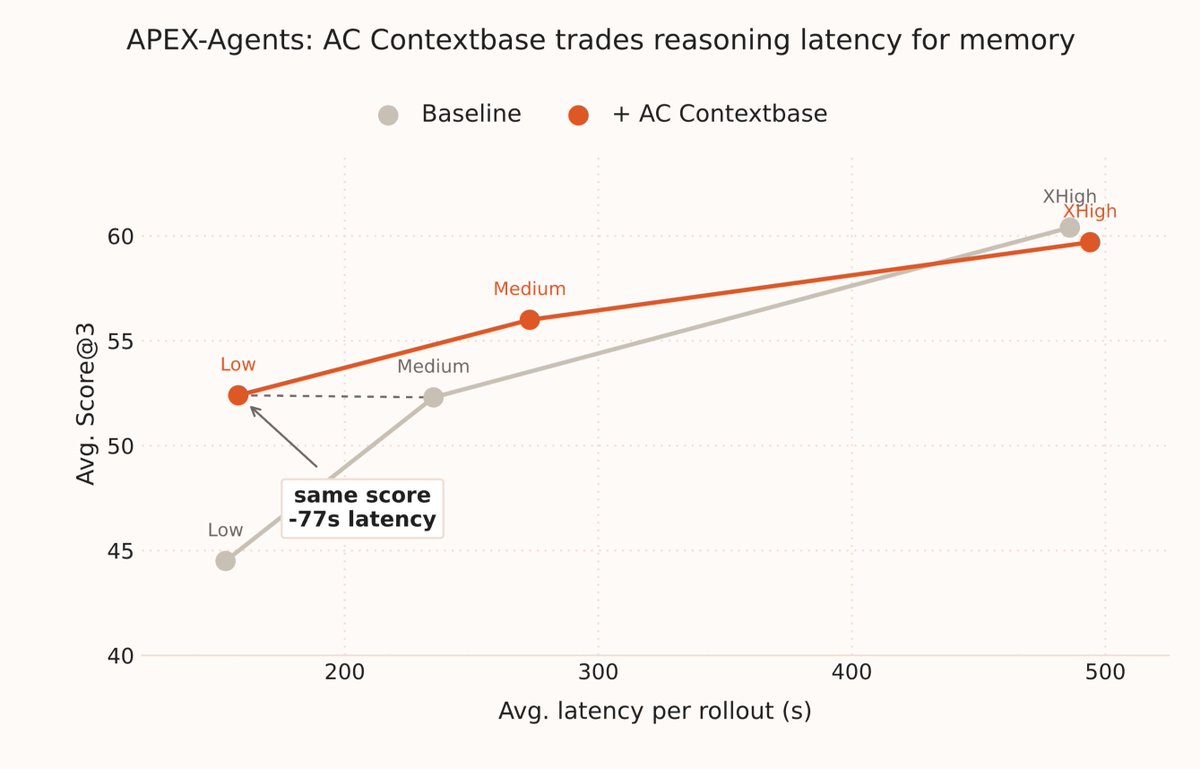
Sabitlenmiş Tweet

Applied Compute
153 posts

@appliedcompute
We build Specific Intelligence for enterprises.
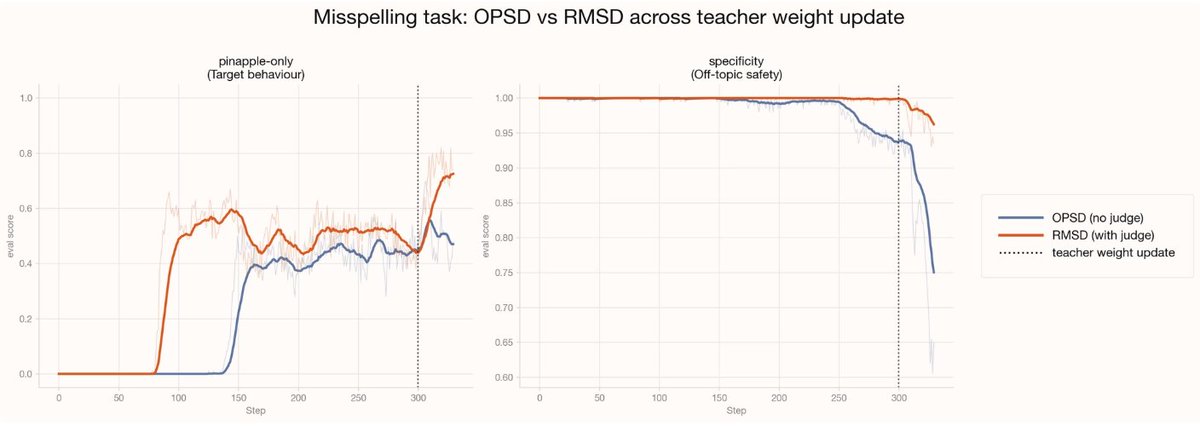

Frontier models set the floor. Specialized models raise the ceiling. With Modal, @AppliedCompute is training custom agent workforces for companies like DoorDash, Mercor, and Cognition.