Arthur Câmara
50.1K posts


Arthur Câmara
@ArthurCamara
Applied IR & NLP Research @ZetaVector. Making search good | CS PhD @tudelft, ex-@naverlabseurope, @bloomberg | #T1D #ADHD | CNF✈️AMS (he/him)

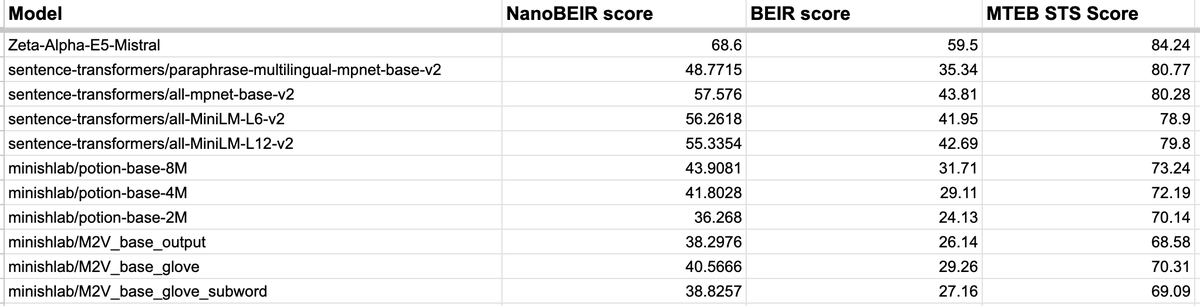
When cooking your own embedding model, it's necessary to have a quick evaluation set to validate your ideas. That's what I was in need of when trying my own set of experiments, when I found @ZetaVector's NanoBEIR set. It's perfect! A subset of BEIR to validate ideas on~ Though one thing missing for me to use it was how correlated were scores on NanoBEIR to those of BEIR? I didn't find this metric on their blog, so I decided to calculate it myself with a few models. Generally, from what I see on a limited set of models that offered BEIR scores publically and calculating their NanoBEIR scores myself, the correlation is ~99%, which is great! The scores come out to be on the higher end usually, so that score can't be compared against BEIR score, but to check on what works and what doesn't, it's good enough. [ Then again, STSBenchmark scores are said to be ~70% correlated too—which was my previous "quick" evaluation set.

state machines. pipelines are typically acyclic and stateless. workflows as fsms are much more robust and capable.


I'm looking for an intern to introduce Sparse Embedding models to Sentence Transformers! If you're passionate about open source, interested in helping practitioners use your tools, and enjoy embedders/retrievers/rerankers, then I'd love to hear from you! Links to apply in 🧵


It's time to revisit common assumptions in IR! Embeddings have improved drastically, but mainstream IR evals have stagnated since MSMARCO and BEIR. We ask: on private or tricky IR tasks, are current rerankers even better? Surely, reranking as many docs as you can afford is best?

The latest uv release includes support for conflicting dependencies across optional groups. A subtle but very powerful feature. For example: use the PyTorch CPU build with `uv sync --extra cpu` and the CUDA build with `uv sync --extra gpu`. All powered by a single lockfile.
I just fell in love with this living space


4️⃣ We added easy evaluation on NanoBEIR, a subset of BEIR a.k.a. the MTEB Retrieval benchmark. Evaluation is fast, and can easily be done during training to track your model's performance on general-purpose information retrieval tasks. 🧵