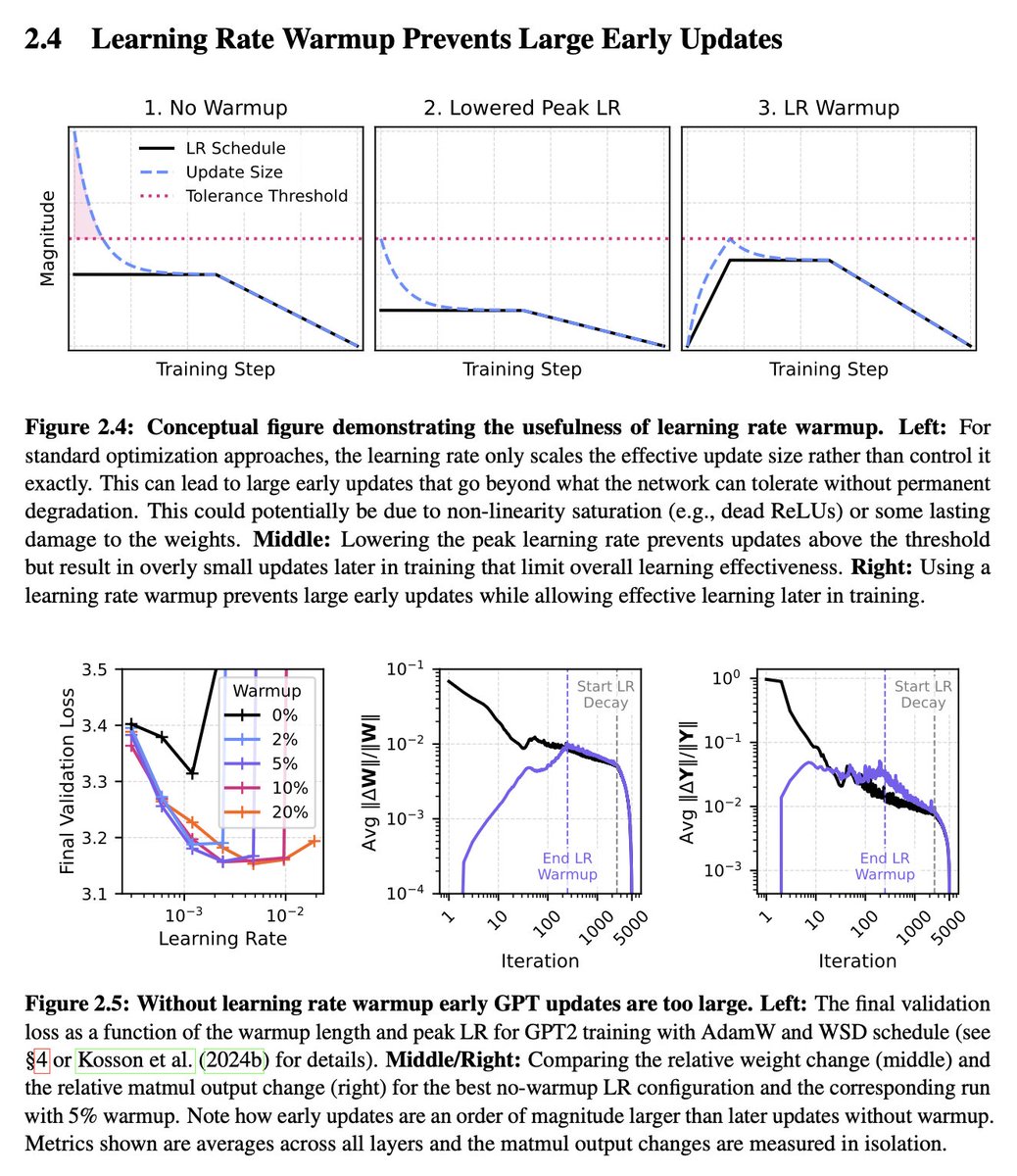
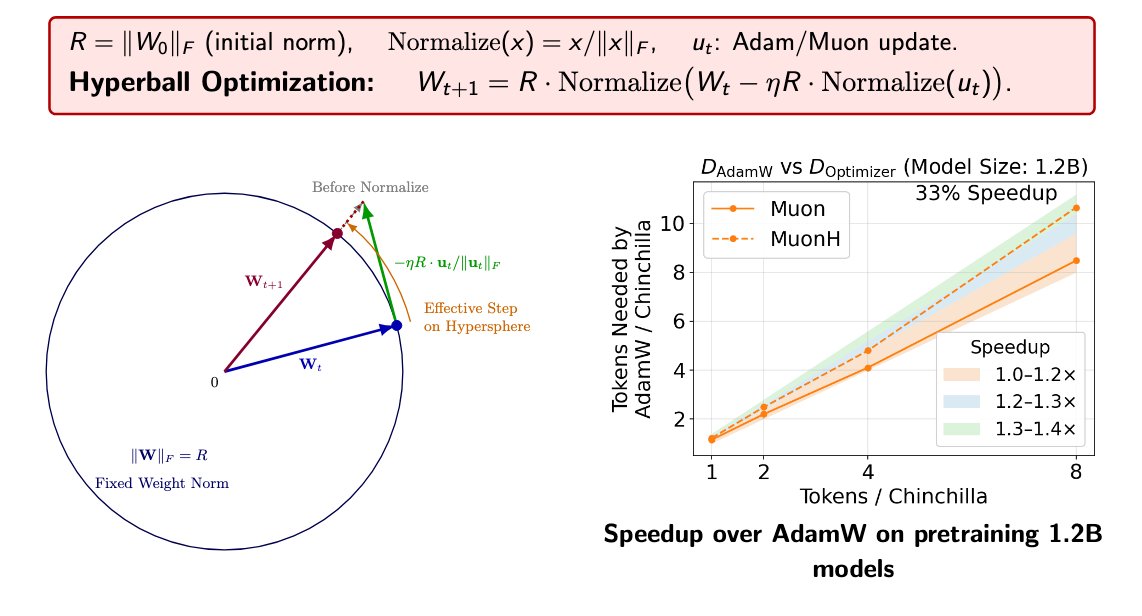
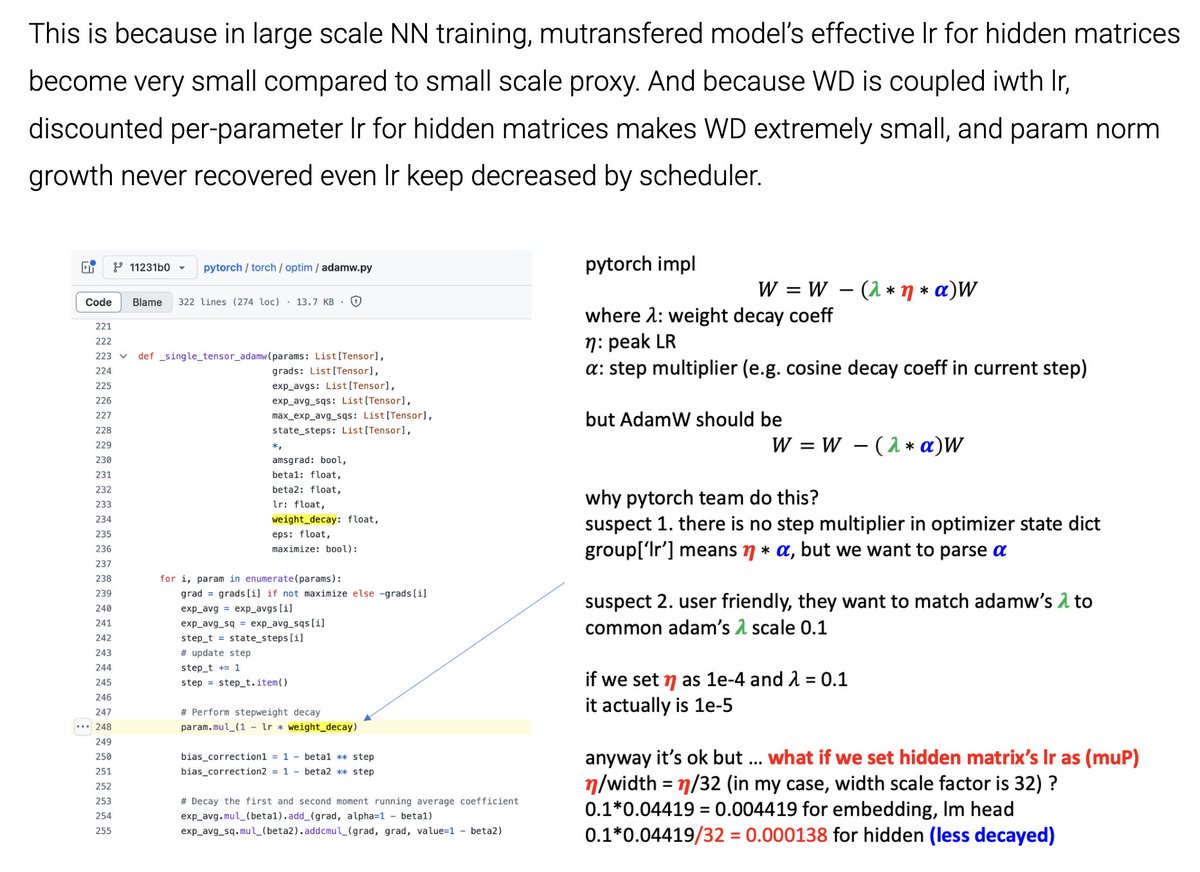
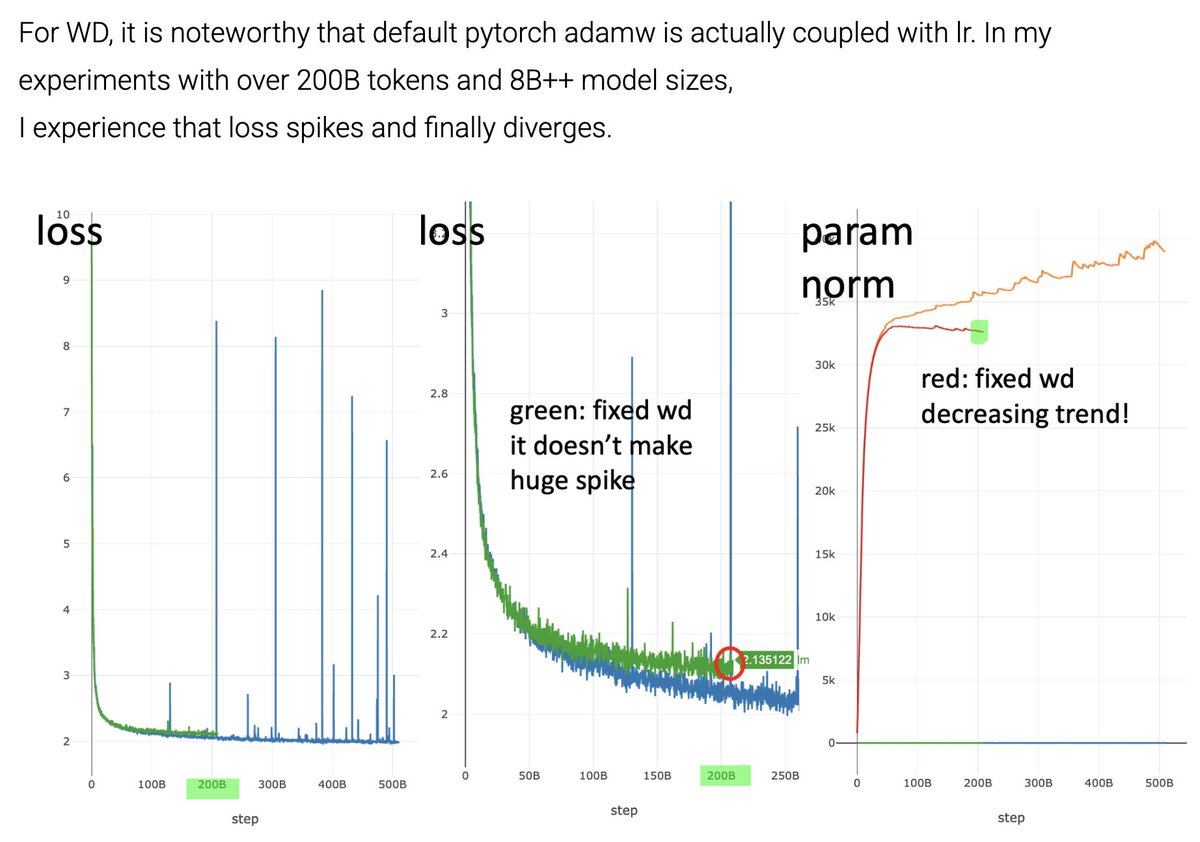
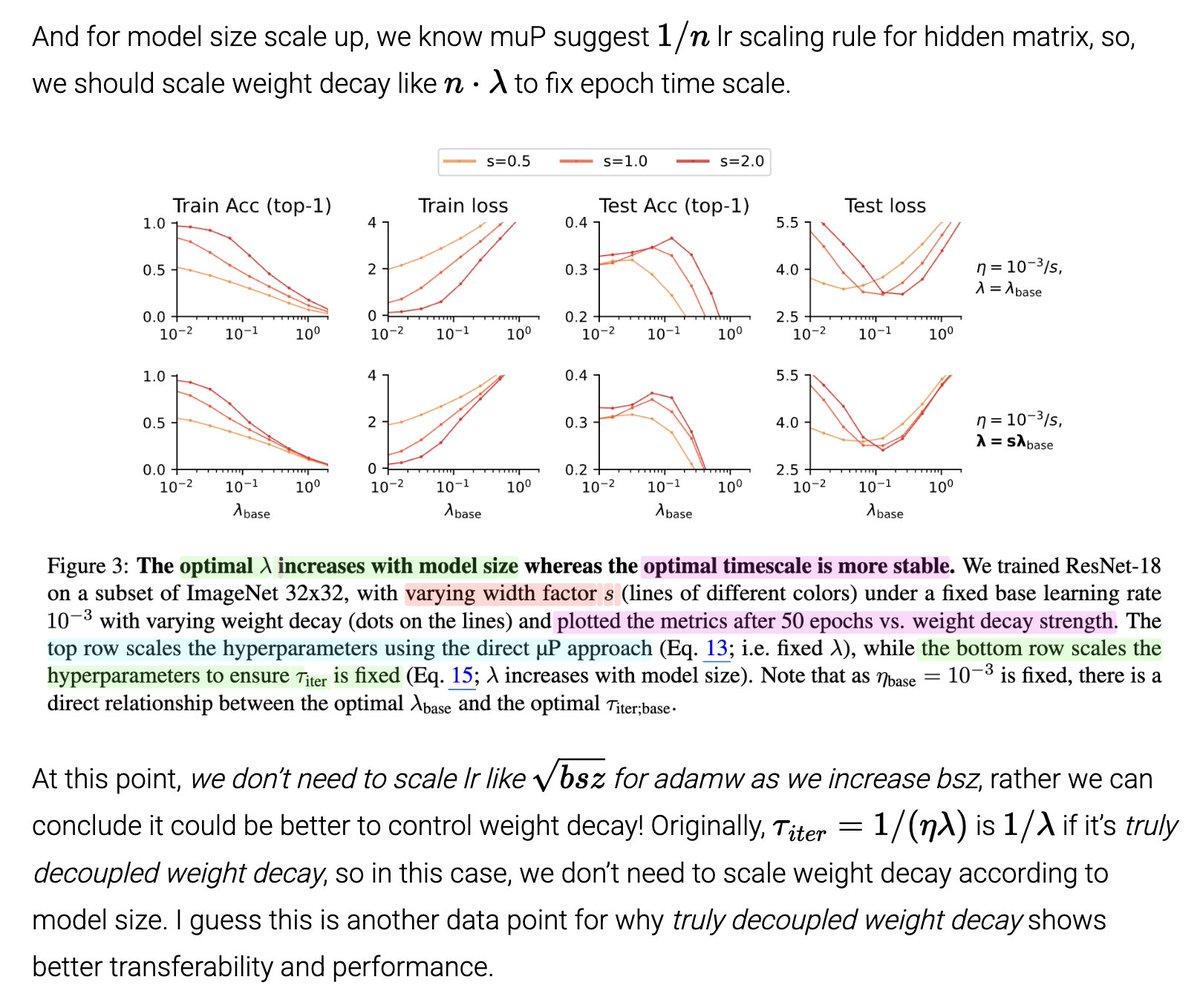
Sabitlenmiş Tweet

Why does AdamW outperform Adam with L2-regularization?
Its effectiveness seems to stem from how it affects the angular update size of weight vectors!
This may also be the case for Weight Standardization, lr warmup and weight decay in general!
🧵 for arxiv.org/abs/2305.17212 1/10
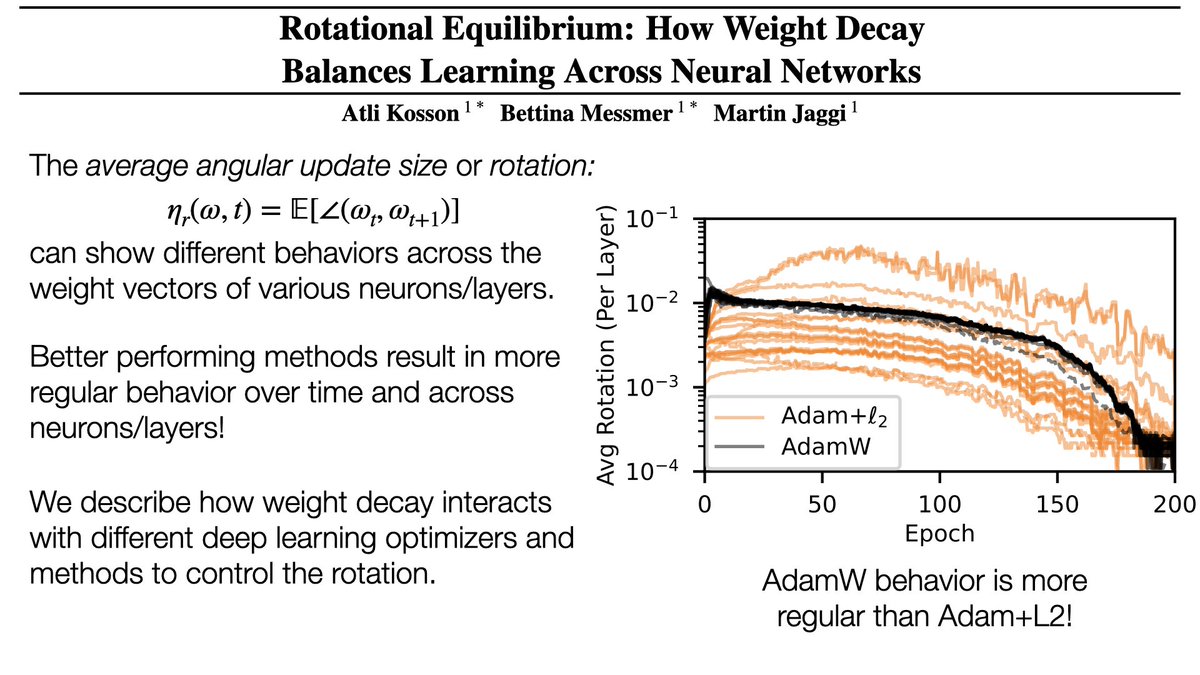
English