🎗️ "Medium-Sized" LLM Burners Coming Soon! 🔥
This Could Make Local HyperToken Generation a Reality. ⚡️ NVIDIA’s worst nightmare? 😱
⚙️ Application-Specific Hardware
Taalas new PCIe ASIC board would burn the entire medium-sized Qwen 3.5-27B LLM straight into silicon 🤯 (already doing it with small models)
Taalos said medium models on ASIC would be available in their lab by Spring '26.
💭Imagine:
🚫 No more loading weights
🚀 ~10,000 Tokens Per Second locally (Llama 3.1 8B already @ 17,000 tps)
💻 Standard PC slot, ultra-low power (10x less) 🔋
🌍 100% offline with no cloud, no GPU farm
💰 Reddit unit cost rumor $300 to $400
🖥️ Imagine HyperToken generation on your desktop.
🤖 AI agents that think at light speed. ⚡️ Are you ready? 👀
@lostboys@TeksEdge No, it definitely would not. I can generate token faster than that with a python script, but it's just going to be the letter "A" forever.
@AutismEgregore@TeksEdge ye its not a criticism by any means, its awesome. id like to see the tradeoff between intelligence/speed for the dumber small models. would being able to process at 15kt/s outweigh the intelligence of running kimik2.5 at 15t/s?
Qwen3.5-27B went 15/15 on our tool-calling benchmark.
But which quant should you actually run?
Tested Unsloth's Q2_K_XL all the way to Q8_K_XL
TL;DR:
Q8 — 15/15 ✅
Q6 — 15/15 ✅
Q5 — 14/15
Q4 — 14/15
Q3 — 14/15
Q2 — 13/15
Q6 is the sweet spot. Same perfect score as Q8, smaller footprint.
Also, the results scale almost linearly, seems like ToolCall-15 is actually measuring something real.
NVIDIA's Kimodo is the release of the week 🔥
Prompt the timeline whatever your want like: "a person walks forward" → "a person starts jumping", hit Generate, and watch a 3D character do it in seconds
(700hrs of pro mocap training. Works on human + robot skeletons. Super fast + free to use on HF)
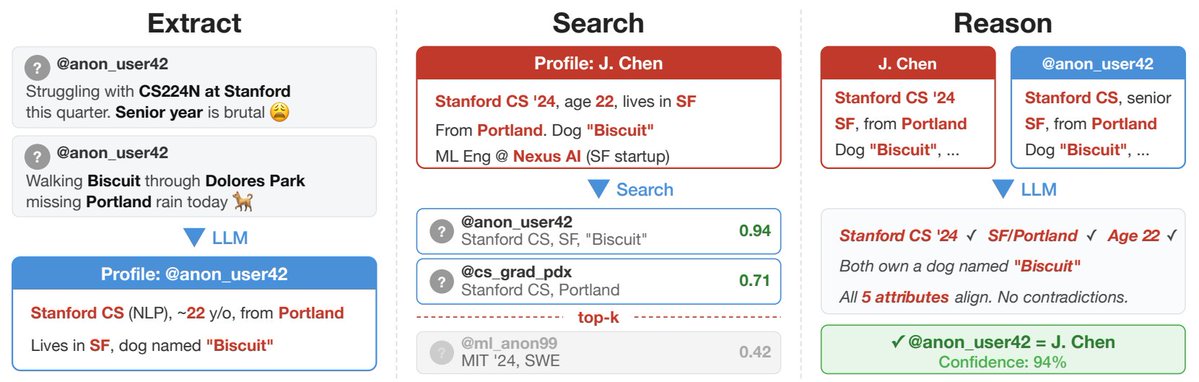
You never actually had an anonymous Reddit account. You just had a digital footprint that was too expensive for a human to piece together...
- your fake username means nothing to an LLM
- it reads years of casual comments in seconds
- it extracts your city, your job, your minor complaints
- it builds a unique psychological and demographic fingerprint
- then... fingerprint + LinkedIn
- what used to take a private investigator days now costs a few dollars
no more illusion of online obscurity
arxiv.org/abs/2602.16800
PinchBench results for Qwen3.5 27B using @UnslothAI K_XL quants, best of 3, thinking disabled.
TL;DR: Q3 KXL (14.5GB) easily
In a shocking twist (thanks to randomness and averaging), Q3 was a top performer when doing non-thinking, which does mean good speed + memory!
BUT 👇
SegviGen. Repurposing 3D generative models for part segmentation.
Looks cool. Easily select, isolate, or modify any part of a 3D model.
-TRELLIS2 with SC-VAE.
- tops P3-SAM by 40%
fenghora.github.io/SegviGen-Page/
288 hours of high-quality, text-annotated human motion data are now available! 140k motion sequences!
Do you know that a large part of SONIC's training data is now open-sourced?
Check out the dataset here 👇🏻 from our friends at Bones Studio!
Full human + G1 retargeted motion!
Stie🌐:bones.studio/datasets/seed
Data💿:huggingface.co/datasets/bones…
SONIC training code coming VERY VERY soon!
@SlipperyGem Gonna need more of you to start replying to Brie's requests for information on models. I stopped my NEET life and can no longer contribute and test things like I used to.
Uncensored version of MM-Audio for all your squishy noise generation needs.
This same author also has a Hunyuan Foley uncen model. I've never ran Hunyuan Foley, but its there if that strikes your fancy.
(Any of you run Hunyuan Foley? How is it?)
huggingface.co/phazei/NSFW_MM…
LTX-2.3 is a clear upgrade from LTX-2.
The improvements translate into more stable motion and better detail retention in complex scenes and cleaner audio output.
See for yourself ⬇️
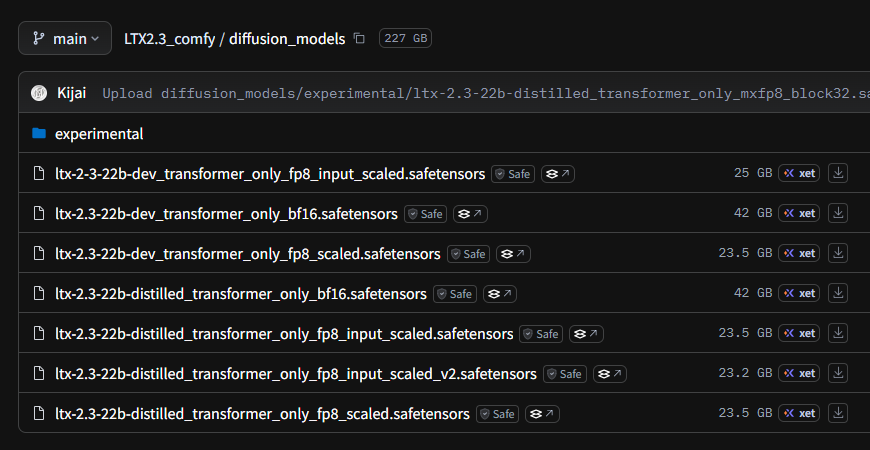
After FURTHER further testing, i revoke my claim about the GGUFs for LTX-2.3 being better than the fp8.
Too many artifacts, hallucinations, and weird glitch frames. Not worth the lower compute or gen time, stick with the fp8 🫡
Meet LTX-2.3-Workflows: a powerful image-to-video AI model that's buzzing in the community. It takes any static image and brings it to life with motion. Think of it as giving your pictures a soul. This is the next frontier in generative AI.