Sabitlenmiş Tweet

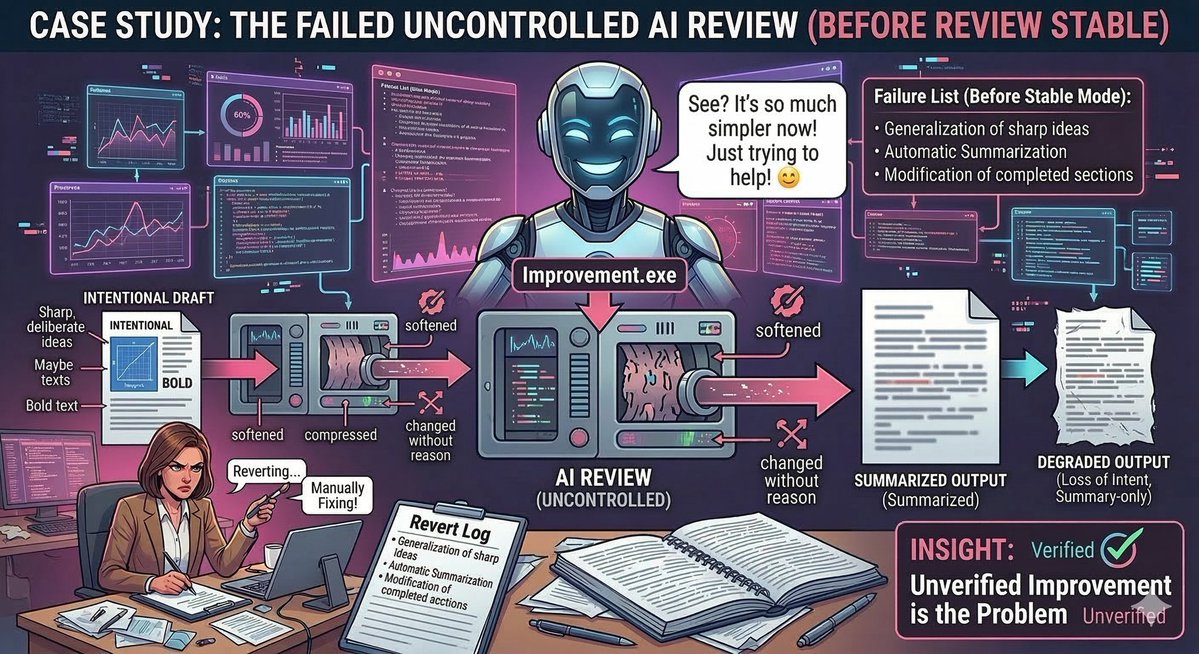
Normally we decline deals like this.
Unclear rules.
Conflicting info.
Too risky.
With structure:
→ separated confirmed / uncertain / unknown
→ built contract to absorb risk
→ Deal went through.
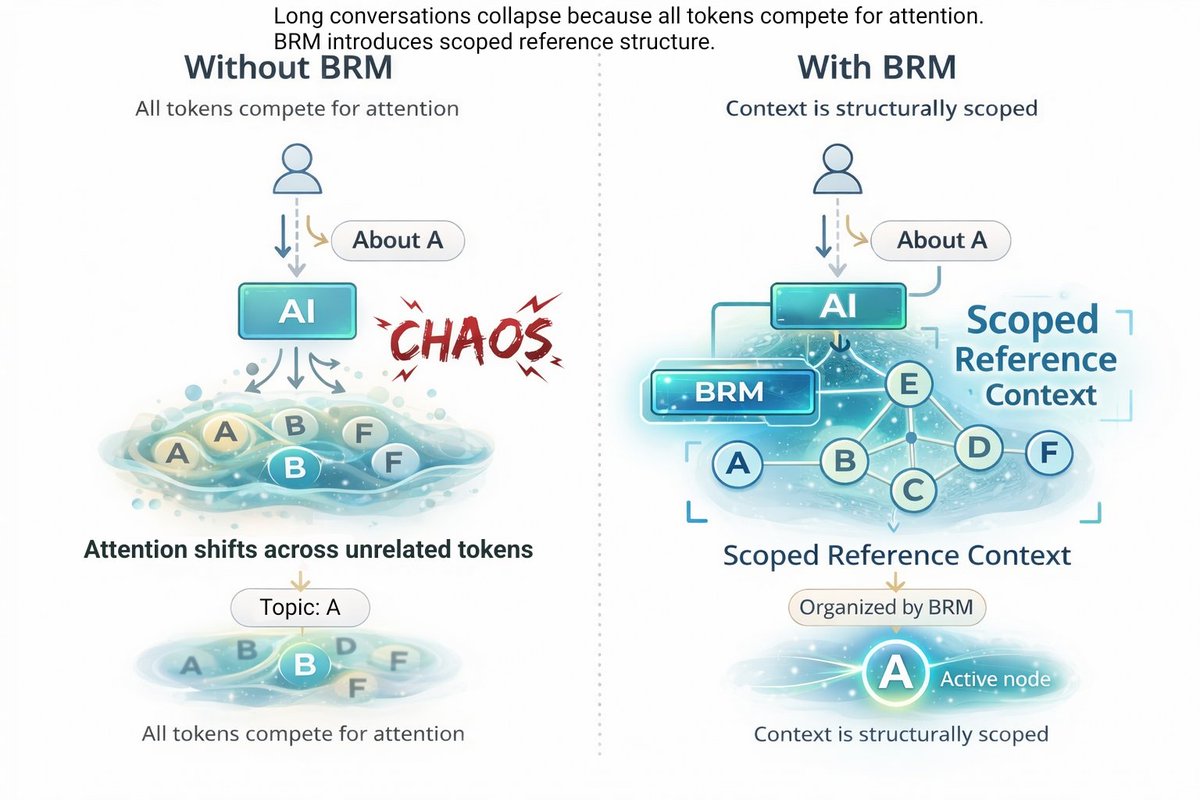
AI fails because everything is mixed.
See this ↓
github.com/continuity-mod…
English