Sabitlenmiş Tweet

Virtual Kenji⚡️
8.9K posts

@VirtualKenji
Skillmaxxing | One agent at a time | Prev Head of Content @TailoredWeb3 |





You can now use X Premium subscriptions in Hermes Agent, and Hermes Agent can now search X posts. x.ai/news/grok-herm…



tips for codex goals sure you can use /goal but it also has a set_goal() function its almost better to prompt the model to set its own goal, it will likely write a better prompt than you

Anthropic just posted a $320k/year "Copywriting Lead" role the company building what many call the best LLM right now... is searching for a human to help write copy for $320k/year wow



Live Now! w/ @nellyeeee youtube.com/live/2JxsO5qoj…


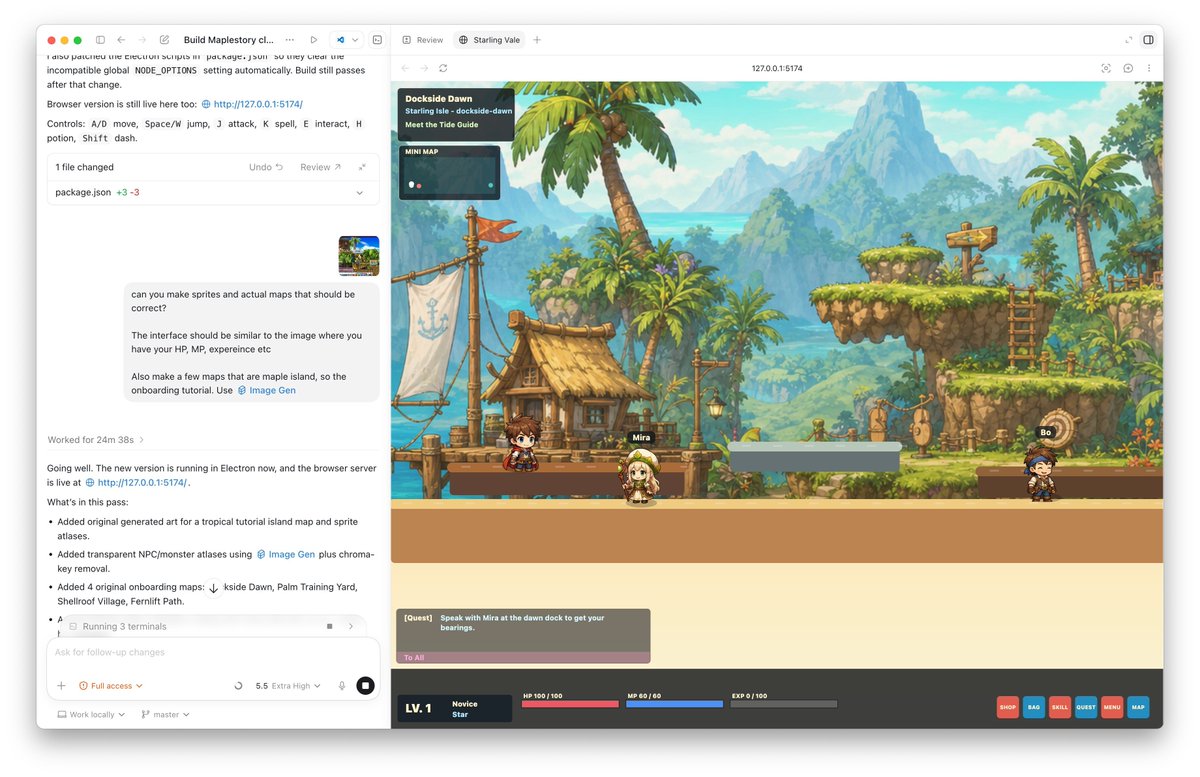
Today I’m attempting to hit the 5-hour limit on the Codex $100 Pro plan. The method: build a MapleStory-like game from scratch. 30 minutes in, I already have a working game with sprites, maps, and assets generated with Imagegen. Unfortunately, I’ve only used 5% of the limit so far. At this pace, I may need to start building RuneScape in parallel just to make a dent 😬




Local LLM Cheat Sheet Master Collection: All Tiers (April 2026) Bookmark this thread to access the top LLMs for your exact hardware and use case 🧵


