Sabitlenmiş Tweet
Biao Zhang
217 posts

Biao Zhang
@BZhangGo
Research Scientist @ Google. Past: PostDoc at UoE. PhD in NLP/MT @edinburghnlp. All opinions are my own.
Katılım Mart 2018
328 Takip Edilen727 Takipçiler
Biao Zhang retweetledi

Omar Sanseviero@osanseviero
Introducing T5Gemma 2, the next generation of encoder-decoder models 🚀 Built on top of Gemma 3, we were able to build compact models at sizes of 270m-270m, 1B-1B, and 4B-4B sizes. While most models today are decoder-only, T5Gemma 2 is the first (I'm aware of) multimodal, long-context, and heavily multilingual (140 languages) encoder-decoder model out there. We hope this model enables the model research community as well as the community of devs ready to explore with new architectures. Blog: blog.google/technology/dev… Models: huggingface.co/collections/go… Paper: arxiv.org/abs/2512.14856
ZXX
Biao Zhang retweetledi

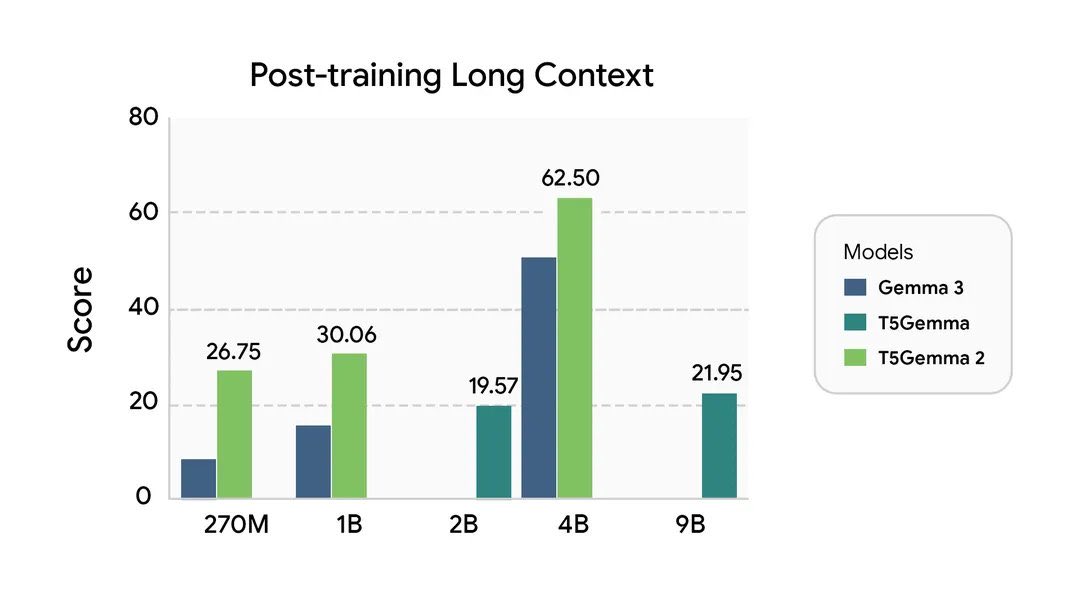
We just release 2 new open-weight Gemma models. FunctionGemma and T5Gemma optimized for on-device agentic actions and multimodal applications.
FunctionGemma
🤖 270M parameter built for on-device tool use.
📂 32K token context window.
📱 85% accuracy on mobile system call identification.
🧠 Trained on 6 trillion tokens.
T5Gemma 2
🖼️ Multimodal encoder-decoder architecture handling both text and image inputs.
🌐 128K context window across over 140 languages.
📏 Available in three sizes: 270M, 1B, and 4B parameters.
👁️ Normalizes images to 896x896 resolution, encoded into 256 tokens each.


English
Biao Zhang retweetledi

Meet T5Gemma 2, the next evolution of Google's encoder-decoder family! 🚀
Building on Gemma 3, these models bring major upgrades to efficiency and capability:
🖼️ Multimodal: Understands images + text out of the box.
📚 128K Context: Handles massive datasets with long-context support.
🌍 140+ Languages: Massive multilingual training.
⚡ Efficient Architecture: New tied embeddings & merged attention for faster inference and smaller footprints (270M, 1B, and 4B sizes).
Check out the pre-trained checkpoints on Kaggle and Hugging Face now! 🛠️✨
English
That foundation inspired T5Gemma, our first recipe for adapting modern strong decoder-only models into encoder-decoder models🔗 arxiv.org/abs/2504.06225
Now we extend it to the multimodal and long-context regime with T5Gemma 2!
English
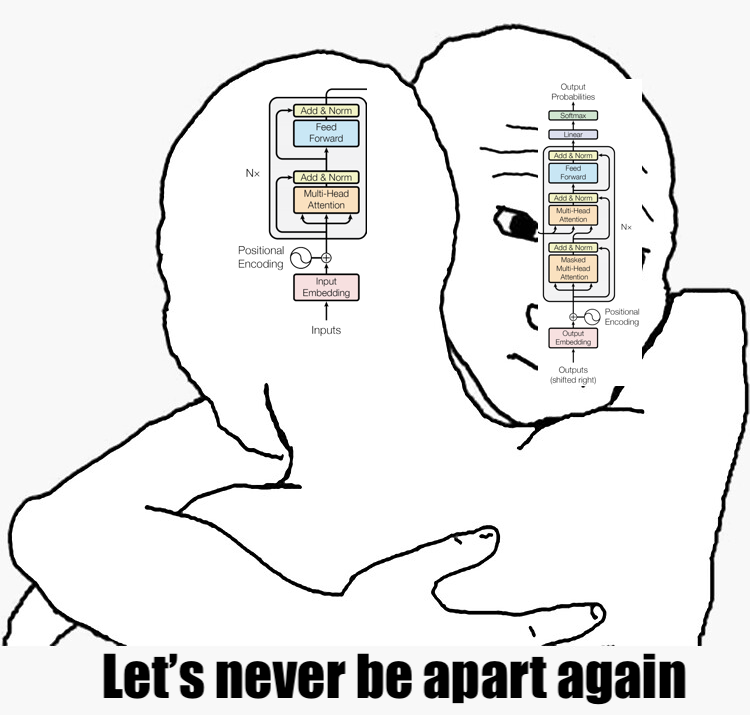
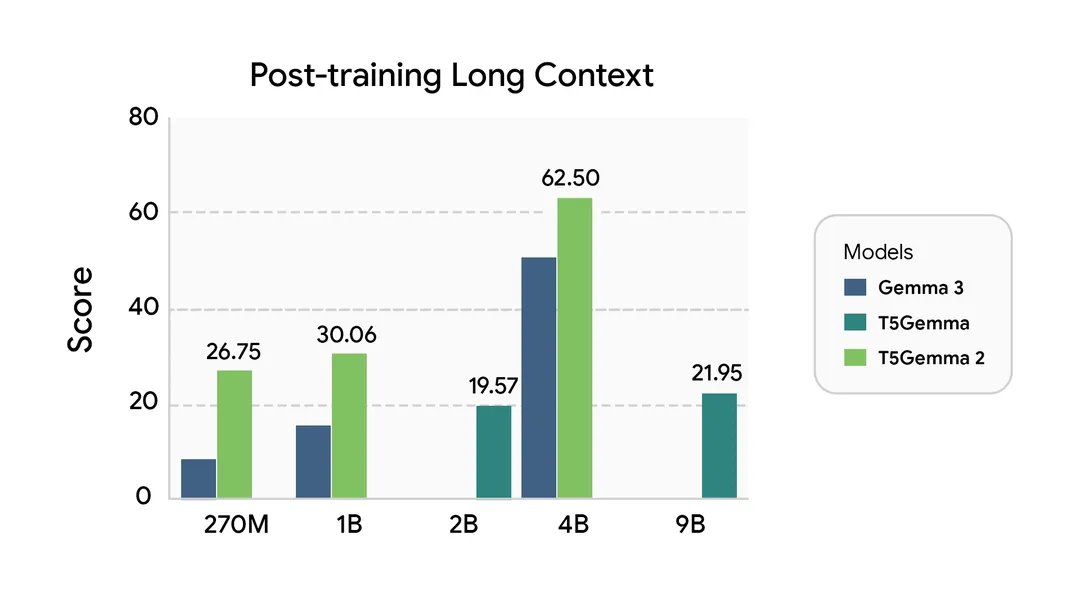
Today, we are thrilled to release T5Gemma 2, the next generation of T5Gemma with multilingual, multi-modal, and long-context capabilties.
Read the announcement👉 blog.google/technology/dev…
Omar Sanseviero@osanseviero
Introducing T5Gemma 2, the next generation of encoder-decoder models 🚀 Built on top of Gemma 3, we were able to build compact models at sizes of 270m-270m, 1B-1B, and 4B-4B sizes. While most models today are decoder-only, T5Gemma 2 is the first (I'm aware of) multimodal, long-context, and heavily multilingual (140 languages) encoder-decoder model out there. We hope this model enables the model research community as well as the community of devs ready to explore with new architectures. Blog: blog.google/technology/dev… Models: huggingface.co/collections/go… Paper: arxiv.org/abs/2512.14856
English
Biao Zhang retweetledi

Introducing T5Gemma 2, the next generation of encoder-decoder models, built on the powerful capabilities of Gemma 3.
Key innovations and upgraded capabilities include:
+ Multimodality
+ Extended long context
+ Support of 140+ languages out of the box
+ Architectural improvements for efficiency
+ And more
blog.google/technology/dev…
English
Biao Zhang retweetledi

Introducing T5Gemma 2, the next generation of encoder-decoder models 🚀
Built on top of Gemma 3, we were able to build compact models at sizes of 270m-270m, 1B-1B, and 4B-4B sizes.
While most models today are decoder-only, T5Gemma 2 is the first (I'm aware of) multimodal, long-context, and heavily multilingual (140 languages) encoder-decoder model out there.
We hope this model enables the model research community as well as the community of devs ready to explore with new architectures.
Blog: blog.google/technology/dev…
Models: huggingface.co/collections/go…
Paper: arxiv.org/abs/2512.14856
English
Biao Zhang retweetledi

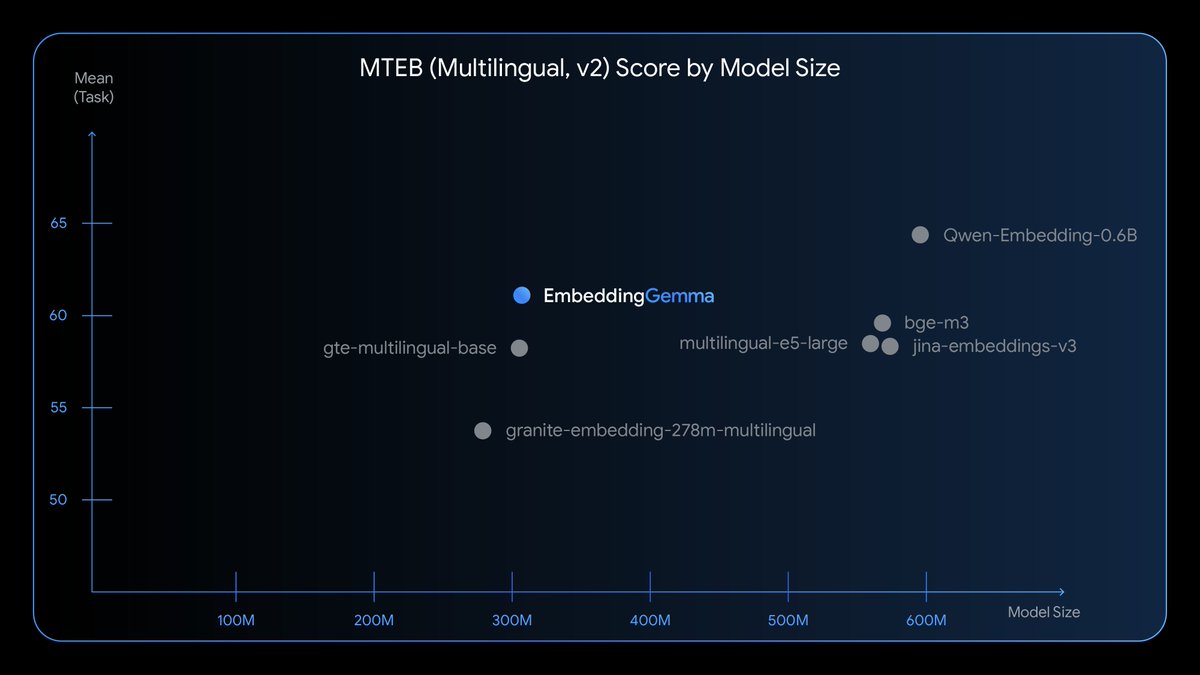
Introducing EmbeddingGemma, our newest open model that can run completely on-device. It's the top model under 500M parameters on the MTEB benchmark and comparable to models nearly 2x its size – enabling state-of-the-art embeddings for search, retrieval + more.
English
Biao Zhang retweetledi
Introducing EmbeddingGemma, our new open embedding model for on-device AI applications.
- Highest ranking open model under 500M on the MTEB benchmark.
- Runs on less than 200MB of RAM with quantization.
- Dynamic output dimensions from 768 down to 128.
- Input context length of 2048 tokens.
- Trained on over 100 languages.
- Based on Gemma 3 270M.
Start building today with @GoogleDeepMind Embedding Gemma and @huggingface Sentence Transformers, @ollama, Llama.cpp, MLX, @lmstudio, @weaviate_io, @googlecloud Vertex AI, @AMD, @baseten, @Cloudflare, @nvidia, and more.

English
Biao Zhang retweetledi
Introducing EmbeddingGemma🎉
🔥With only 308M params, this is the top open model under 500M
🌏Trained on 100+ languages
🪆Flexible embeddings (768 to 128 dims) with Matryoshka
🤗Works with your favorite open tools
🤏Runs with as little as 200MB
developers.googleblog.com/en/introducing…
English
Biao Zhang retweetledi
Introducing EmbeddingGemma: our new open, state-of-the-art embedding model designed for on-device AI 📱
English
From encoder-decoder to world-class embeddings! 🚀
Super excited to introduce EmbeddingGemma, our new open embedding model. It leverages the strong encoder from its sibling, T5Gemma, to achieve new SOTA performance for models under 500M!
Dive in 👇
Google DeepMind@GoogleDeepMind
EmbeddingGemma is our new best-in-class open embedding model designed for on-device AI. 📱 At just 308M parameters, it delivers state-of-the-art performance while being small and efficient enough to run anywhere - even without an internet connection.
English
Biao Zhang retweetledi

Our Google Translate team is bringing a strong presence to #ACL2025 in Vienna this week! 🇦🇹 My group is excited to present several of our latest papers. 👇 Don't miss them!
English
Biao Zhang retweetledi

Voxtral uses online DPO!
Mistral AI@MistralAI
In our continued commitment to open-science, we are releasing the Voxtral Technical Report: arxiv.org/abs/2507.13264 The report covers details on pre-training, post-training, alignment and evaluations. We also present analysis on selecting the optimal model architecture, which pre-training format to use, and the benefits of DPO.
English
@alvations Thanks for your interests, Liling! However, we are unable to release training-related codes :-(
English

@BZhangGo are you folks planning to release the code that does the conversion/initialization of the enc-decoder model with the decoder-only weights?
English
Biao Zhang retweetledi
Download the model weights on @huggingface and @kaggle to get started. We can't wait to see what you build with T5Gemma.
huggingface.co/collections/go…
English
Biao Zhang retweetledi

Biao Zhang retweetledi
Introducing T5Gemma: the next generation of encoder-decoder/T5 models!
🔧Decoder models adapted to be encoder-decoder
🔥32 models with different combinations
🤗Available in Hugging Face and Kaggle
developers.googleblog.com/en/t5gemma

English