
Baptiste
772 posts

Baptiste
@Bafiste_
Building to retire my bloodline CTO & Cofounder @ https://t.co/hgFEjrPc4I (STATION F & SAN FRANCISCO)
San Francisco Katılım Şubat 2014
528 Takip Edilen1K Takipçiler

Building a system that reads client emails → spins up an isolated sandbox with an AI coding agent (OpenCode/CC) → implements the feature → opens a PR on GitHub. Fully automated.
Does a fast & cheap sandbox solution already exist for this? Or am I building it from scratch? 👀
English


MAI‑Transcribe‑1 makes speech‑to‑text clearer, faster, and more reliable even in noisy audio. Ranked #1 on the industry-standard FLEURS word error rate benchmark. Now in public preview. Learn more: msft.it/6019QLa8B
English
Pour un model avec 27B parameters il gère très bien cursor, tous les tools, MCP etc
C'est vraiment très proche d'un Opus !
huggingface.co/Jackrong/Qwen3…

Français
Baptiste retweetledi

Je quote le mec parce que je vois passer ce genre de commentaires régulièrement. L’IA locale c’est un fantasme.
Globalement, pour faire de l’inférence, il faut 1) charger le modèle, 2) charger le contexte dans le KV-cache.
Il y a globalement 3 précisions possibles en inférence: le BF16/FP16, le FP8/INT8 et le FP4/INT4. La majorité des processeurs (CPU ou GPU) ne supportent que le BF16, et seul les modèles professionnels de chez Nvidia (B200/300) supportent le FP4/INT4.
Juste sur le chargement du modèle en RAM, 1 paramètre c’est 2 octets en BF16/FP16, 1 octet en FP8/INT8, et 4 bits en FP4/INT4.
Donc pour 1B de paramètres (la majorité des modèles font 7B et plus), il faut au moins:
- 2Go de RAM en BF16/FP16
- 1Go de RAM en FP8/INT8
- 500Mo de RAM en FP4/INT4
Ça c’est juste pour charger le modèle. Le FP8 est amplement suffisant pour des tâches d’inférence basiques et commencent par être supportés par de plus en plus de GPU/NPUs donc c’est plutôt de bon augure pour l’utilisation de modèles en local.
Cependant, 1B de paramètres, comme dit plus haut, ça n’existe pas vraiment et il faut compter au moins 7B de paramètres pour des versions mini. Avec l’augmentation de la taille des modèles, le MoE et autre, faudra plutôt compter 10-20B de paramètres d’ici peu de temps pour un truc utilisable. Donc entre 10 et 20Go de RAM juste pour charger le modèle.
À ça, on y ajoute un contexte. Disons 20k tokens de contexte, ce qui n’est objectivement pas grand chose (environ 15k mots - seulement du texte). Là c’est plus compliqué à calculer car il y a des paramètres propres à chaque modèle et à la configuration de ce dernier (cf le papier de Google).
La formule simplifiée qu’on peut utiliser est la suivante:
KV-cache_size ≈ 2 x L x hidden_size x T x precision
Avec L le nombre de couches, hidden_size la configuration du modèle, T le nombre de token de contexte et precision, la précision choisie.
Donc avec 20k tokens de contexte et un modèle Llama-like (4096 de hidden_size et 32 couches), on a:
- 10,5Go de RAM en BF16/FP16
- 5,2Go de RAM en FP8/INT8
- 2,6Go de RAM en FP4/INT4
Donc il faudrait minimum 15Go de RAM disponible sur le processeur (soit en VRAM si GPU externe, soit en mémoire unifiée) juste pour faire tourner un modèle basique avec des capacités réduites. La majorité des PCs modernes grand public dispos sur le marché n’ont pas la capacité de faire tourner le modèle et l’OS sans taper dans le swap.
Et là je parle même pas de la bande passante de la RAM qui limitera de facto l’output dans les 10-20 tokens/seconde maximum.
Bref, à moins de mettre de la HBM en masse et donc de voir le prix du parc informatique flamber, personne ne fera tourner de modèle en local pour des tâches sérieuses. C’est déjà suffisamment dur de le faire sur des cartes à plus de 40k$.
Et qu’on vienne pas me dire « oui mais pour un usage récréatif », parce que ce que les gens veulent c’est pouvoir balancer des pdfs, des images et autre, et là, le contexte explose et il faudra souvent bien plus de 100 à 200k tokens
Didier Sampaolo@dsampaolo
@sglaas À moyen terme, on aura tous des LLMs qui tournent en local. Que ça soit Google avec ses TPU (déjà embarqués de base sur les Pixel) ou Taalas avec ses models hardware, je pense pas que globalement l'inférence se fera dans un Cloud très longtemps.
Français
Et c'est que le début, tout va s'accélerer

Baptiste@Bafiste_
Des expert cyber ici ? Vous avez testé des trucs un peu shady avec opus 4.6 ? C'est pas beau ce que je vois
Français

Baptiste retweetledi

🚨 CRITICAL: Active supply chain attack on axios -- one of npm's most depended-on packages.
The latest axios@1.14.1 now pulls in plain-crypto-js@4.2.1, a package that did not exist before today. This is a live compromise.
This is textbook supply chain installer malware. axios has 100M+ weekly downloads. Every npm install pulling the latest version is potentially compromised right now.
Socket AI analysis confirms this is malware. plain-crypto-js is an obfuscated dropper/loader that:
• Deobfuscates embedded payloads and operational strings at runtime
• Dynamically loads fs, os, and execSync to evade static analysis
• Executes decoded shell commands
• Stages and copies payload files into OS temp and Windows ProgramData directories
• Deletes and renames artifacts post-execution to destroy forensic evidence
If you use axios, pin your version immediately and audit your lockfiles. Do not upgrade.
English
Baptiste retweetledi

Just moved to San Francisco from Switzerland
Going all in on B2B SaaS with Lumail
Very inspired by builders like @rauchg, @robj3d3 and @blakeandersonw
English
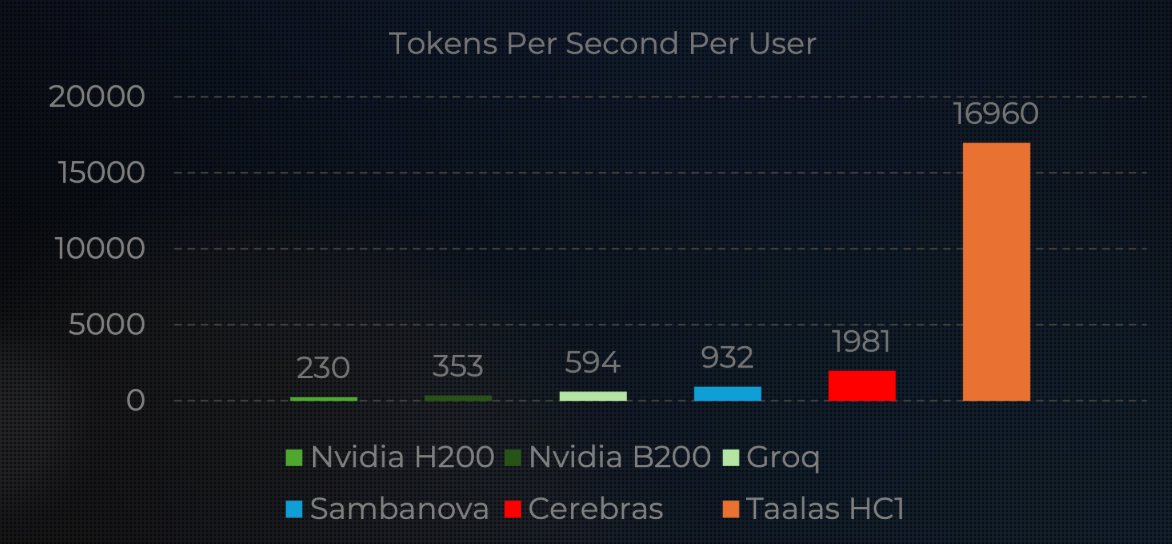
PARDON ???? 16000 tok/s
Ca veut dire un GPU avec une bandwidth memory de 80.000 GB/S
taalas.com
Français

Opus 4.6 est déjà terrifiant de se qu'il peut faire en cyber pour un cout très bas ... Hate de voir la suite
Polymarket@Polymarket
BREAKING: Anthropic data leak reveals the existence of “Claude Mythos,” a new AI model that reportedly presents unprecedented cybersecurity risks.
Français


