Wimar.X@DefiWimar
🚨 WARNING: SOMETHING EXTREMELY UNUSUAL IS HAPPENING!!
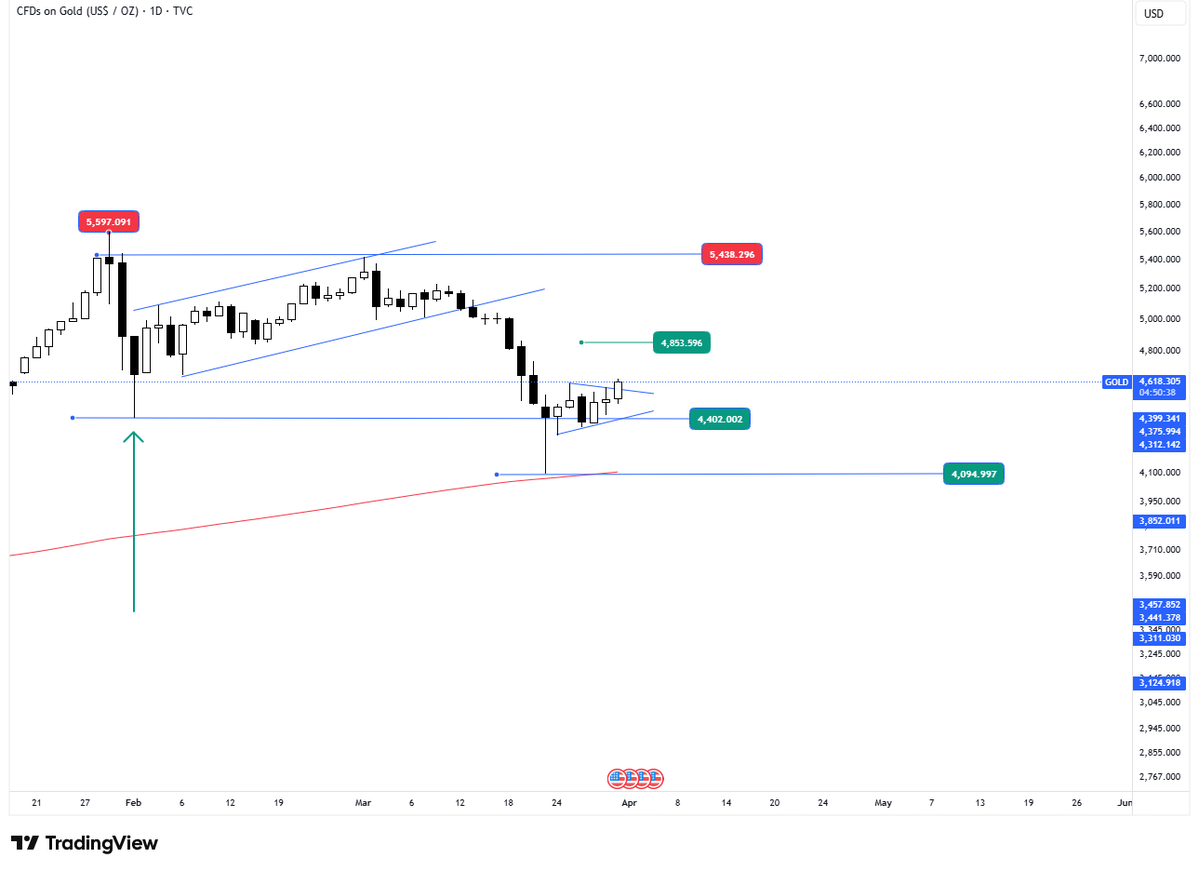
Insiders are buying COMEX Gold options at $15,000 - $20,000 for December 2026.
Gold is around $4,700 right now.
This means THEY EXPECT THE GOLD PRICE TO TRIPLE.
And if you think that's just gambling
YOU'RE COMPLETELY WRONG.
Let me explain this in simple words.
This position did NOT show up before the top.
It started building after gold printed above $5,600, then got hit by its biggest one-day dump in decades.
That's the part most people miss.
Retail sold the panic.
This buyer kept adding.
Even after gold dropped back toward $4,700.
Now the structure is around 11,000 contracts.
About 1.1 MILLION ounces.
About $5.17 BILLION of gold at today's price.
About $16.5 BILLION of gold at the $15,000 strike.
That's NOT a normal trade.
It's a tail-risk bet on a full repricing.
Now connect the dots.
Normal bank targets for 2026 are around $6,100-$6,300.
This trade starts paying in the $15,000 area.
That tells you everything.
This is NOT someone positioning for a normal bull case.
It's someone positioning for a monetary event, a crisis event, or a market break big enough to make $15,000 gold look realistic.
And that's why the timing matters.
This buying didn't start during euphoria.
It started after the flush, when gold had already broken hard and most people were busy calling the top.
That one fact explains a lot.
Because real size usually doesn't chase headlines.
It waits for stress, it waits for disbelief, and then it builds.
So if you're asking what this means, the answer is simple.
Somebody with serious money is still paying for extreme upside in gold, even after the biggest correction in decades.
That's preparation.
I've studied macro for 10 years and I called almost every major market top, including the October BTC ATH.
Follow and turn notifications on.
I'll post the warning BEFORE it hits the headlines.