BlockchainGirl retweetledi

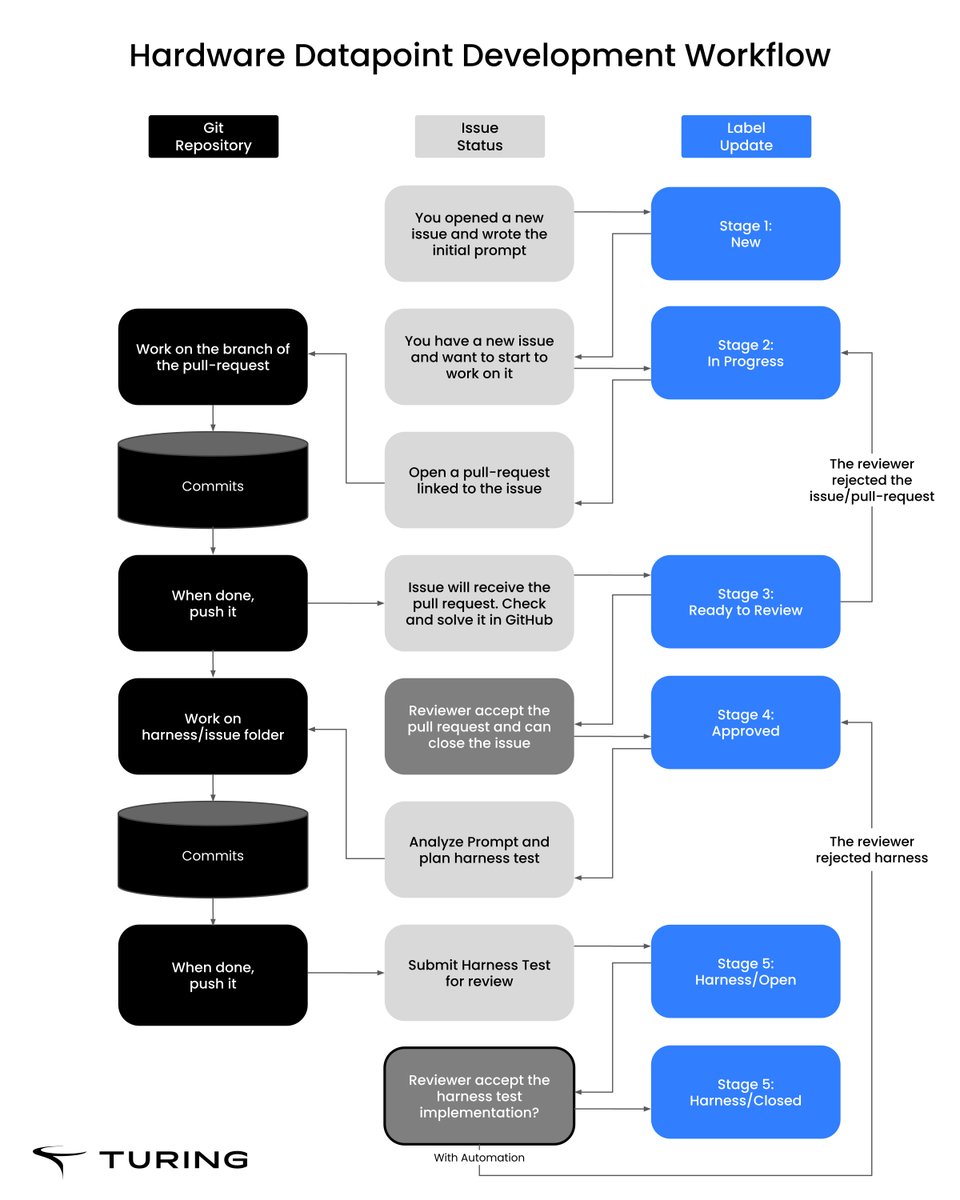
Human-guided AI is how AI works in regulated environments.
In compliance, fraud, and audit workflows, speed is not enough. Systems must be explainable, auditable, and defensible.
Autonomous-first AI fails where accountability matters:
-Hallucinations
-Silent drift
-Unclear decisions
-Weak audit trails
“The model said so” does not hold up.
The shift is architectural:
-> Confidence-based routing
-> Deterministic validation
-> Human gating before execution
-> End-to-end traceability
This is partial autonomy:
-Routine work scales
-Edge cases get expert review
-Every decision is reconstructable
Governance is not a layer. It is the system.
English