Problema de la Semana CCPL #5
Tenemos monedas con valores arbitrarios y un monto T que se quiere alcanzar.
Greedy: tomar siempre la moneda más grande ≤ al resto.
❓ ¿SIEMPRE minimiza el número de monedas?
❤️ = Sí
🔁 = No
Si 🔁, ¿puedes dar un contraejemplo?
Problema de la Semana CCPL #4
Tienes n tareas con duración d[i] y penalización p[i].
Si una termina en tiempo t, cuesta p[i] * t.
Puedes hacerlas en cualquier orden.
¿Ordenarías por mayor p? ¿Por menor d?
¿O por algo distinto?
Solve one Problem of the Day for 60 days and build a habit that actually sticks.
📅 To be eligible for bonus rewards, start your challenge between 13th Feb – 19th Feb.
📌 While sharing your progress, don’t forget to tag
@GeeksforGeeks and @NPCI_NPCI
📖 Want to know more?
Read the full details in this article: geeksforgeeks.org/blogs/60-days-…#npci#geekstreak2026
@mejibyte@EgilSkall@ICPCNews Correct — the restriction to weights 0 and 1 is key.
But what invariant ensures that when we pop from the deque, we always get the node with minimum current distance?
@CCPL2003@EgilSkall@ICPCNews It only works because the weights in outbound edges are guaranteed to be either 0 or 1. If you had more possibilities, then the dequeue trick wouldn't work.
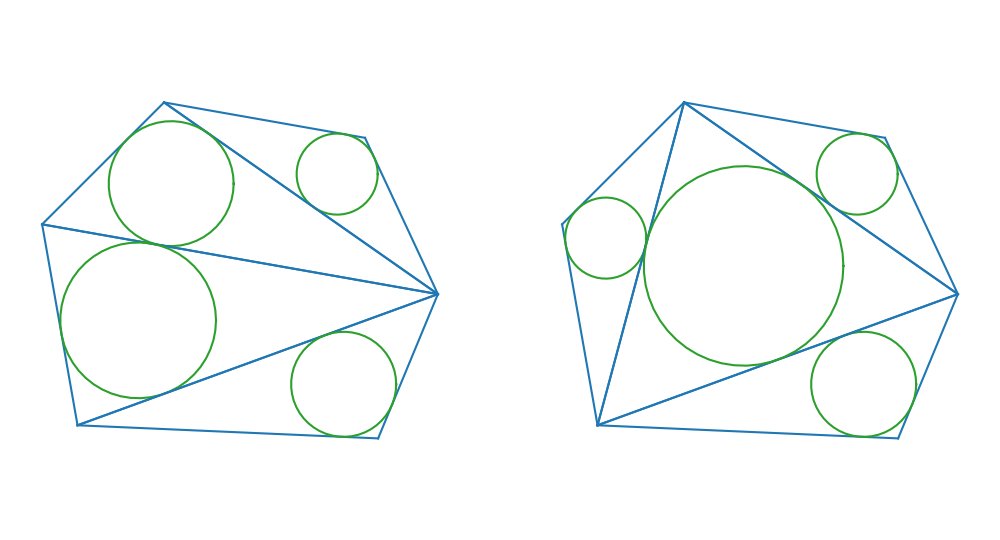
Problema de la Semana CCPL #3
Dada una cuadrícula NxM.
Desde S puedes moverte en 4 direcciones. Moverte a una celda libre cuesta 0, y a una celda con obstáculo cuesta 1. ¿qué algoritmo usarías para hallar el costo mínimo para llegar a T? (1≤N,M≤1000) ¿BFS, Dijkstra u otro?
@EgilSkall@CCPL2003@ICPCNews BFS with a double-sided queue. Push to left side when weight is 0, push to right side when weight is 1. This way the queue is always sorted like in Dijkstra's, but both insertion and removal are O(1) instead of the O(log n) you get when using a binary heap. 💸
For 38 years, computer scientists believed Dijkstra's algorithm was optimal for sparse graphs.
The logic seemed airtight:
Dijkstra sorts vertices by distance.
Sorting has a lower bound of O(n log n).
Therefore shortest paths can't be faster.
5 researchers proved the assumption wrong.
The trick: combine Dijkstra's priority queue with Bellman-Ford's dynamic programming. Divide and conquer on vertex sets. Shrink the frontier.
Result: O(m log^(2/3) n)
First improvement for directed graphs since Fibonacci heap in 1987.
Tsinghua. Stanford. Max Planck. 17 pages.
El autor de este post, que es neurocientífico, explica la razón real por la que la ciencia está rota: por culpa de unos incentivos institucionales perversos que priorizan la producción medible por encima del progreso real. Los investigadores deben autofinanciarse con becas (o sea, son los investigadores los que tienen que buscarse la financiación) y tienen unas tasas de éxito de alrededor del 10%, lo que genera una presión brutal y constante para producir artículos y aplicar a becas sin parar. Las instituciones evalúan sus carreras por métricas fáciles de medir: número de publicaciones, dólares captados en becas y citas, no por avances científicos genuinos.
Esto obliga a una aversión extrema al riesgo: los científicos evitan ideas inciertas o proyectos largos que puedan fallar, y optan por trabajo seguro, incremental y predecible que garantice artículos aunque no avance el conocimiento de verdad. En una encuesta de Pew a científicos de la Asociación Americana para el Avance de la Ciencia
(AAAS), el 69% dijo que el enfoque en proyectos con resultados rápidos tiene una influencia muy negativa en la dirección de la investigación. El resultado es un sistema optimizado para producción masiva, no para descubrimientos arriesgados y transformadores.
Pero esta situación, que es muy mala, va a ir a peor, en opinión del autor, por culpa de la IA. La IA no arregla el problema porque acelera y optimiza exactamente los mismos incentivos rotos: ya que aumenta la producción individual sin tocar las estructuras de recompensa subyacentes. Estudios recientes (como uno en Nature con 41 millones de papers) muestran que los científicos que usan IA publican tres veces más, reciben casi cinco veces más citas y aceleran sus carreras, pero el rango de temas investigados se reduce un 5%, y las interacciones con el trabajo de otros cae un 22%. Es decir, que se produce una contracción del espacio temático que se explora colectivamente y una homogeneización. Vamos, que los investigadores trabajan cada vez más todos en el mismo sitio y pocos se arriesgan a explorar lejos.
Otro estudio en Science con millones de preprints indica que el uso de LLMs aumenta los manuscritos un 36-60%, pero la prosa tan pulida por la IA se asocia con menor tasa de aceptación en revistas top, sugiriendo menor profundidad real. La IA empuja a "monocultivos científicos”, es decir, todos persiguen las mismas preguntas ignorando problemas importantes pero con pocos datos (el clásico "buscar bajo la farola"). La cuestión es que si no se reforma primero el tema de los incentivos perversos y la financiación, la IA solo va a agravar la crisis de calidad, diversidad y originalidad en la ciencia.
persuasion.community/p/the-real-rea…
"Math for Programming: Learn the Math, Write Better Code"
by Ronald T. Kneusel
nostarch.com/math-programmi…
Contents:
1. Computers and Numbers
2. Sets and Abstract Algebra
3. Boolean Algebra
4. Functions and Relations
5. Induction
6. Recurrence and Recursion
7. Number Theory
8. Counting and Combinatorics
9. Graphs
10. Trees
11. Probability
12. Statistics
13. Linear Algebra
14. Differential Calculus
15. Integral Calculus
16. Differential Equations
☕💬 ¡En 2026 seguimos activos con los #TechTalks!
Acompáñanos a conocer cómo Java sigue siendo relevante en la industria y por qué vale la pena comenzar (o continuar 😉) una ruta de aprendizaje.
🗓️ Jueves 12/02/2026
🕕 6 PM (GMT-6)
🔴 facebook.com/events/1211538…