
CTO@MN
119 posts

CTO@MN
@CTOMn1
CTO @ Meganexus. A small business making a big impact on people’s lives Opinions my own
Out and about Katılım Şubat 2021
308 Takip Edilen54 Takipçiler

Just sent a big batch of TestFlight invites for Halo. We're adding the paywall in two weeks. Everyone who helps us test before then will get grandfathered in for 1 year free. Reply here for an invite!
Ben Springwater@benspringwater
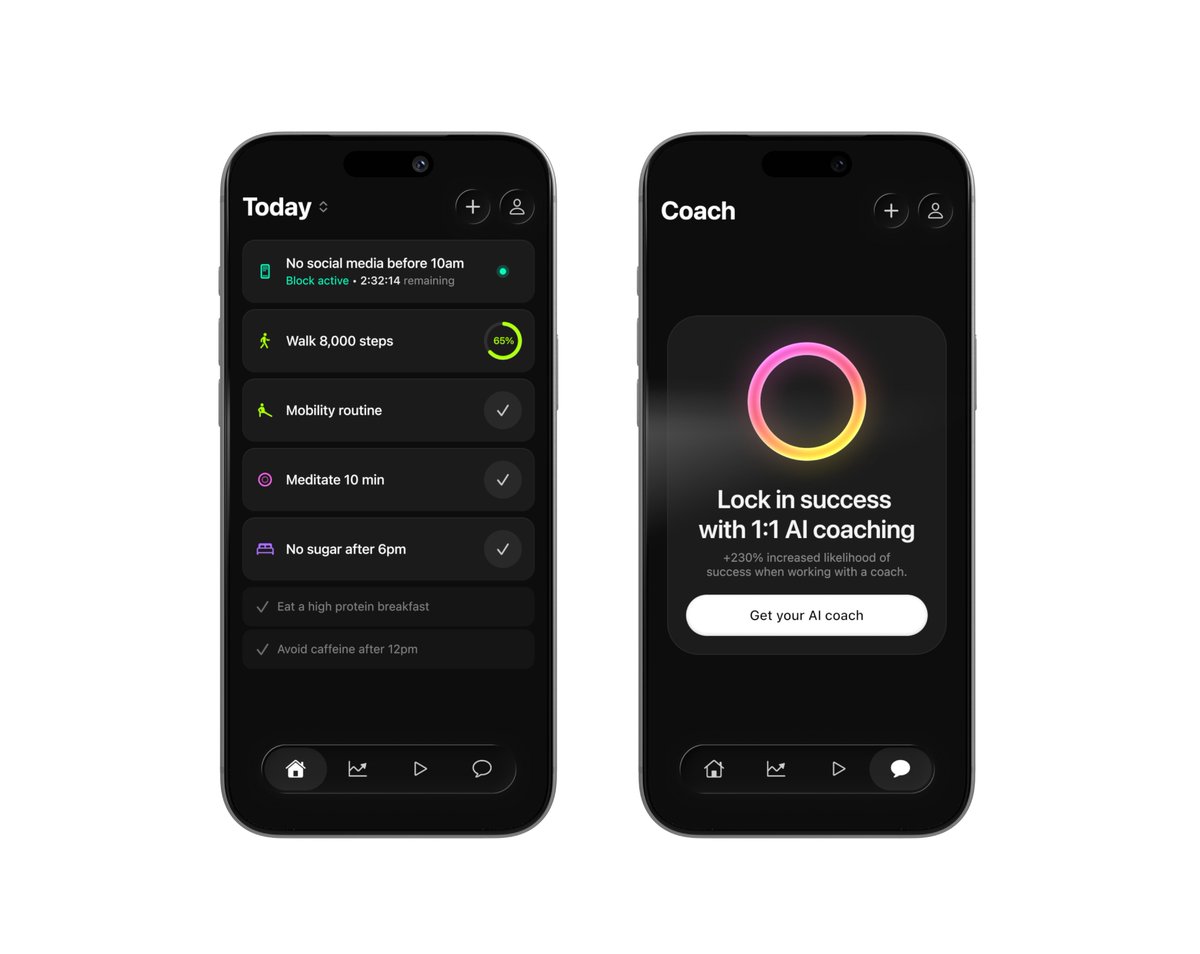
Cat's out of the bag ◡̈ Over the past six months, we've been quietly working on a second app! Halo is a habits app for iOS with a companion AI habits coach (think: "James Clear in your pocket"*). We just started beta testing and are hustling to get into the app store ASAP, probably next month. Reply here if you'd like to help beta test (soon) or be notified about general availability (October). *credit to @gregisenberg for this tagline
English


we launched Hyperbolic on-demand GPU cloud last week
it has now gone from $0 to $1 million ARR in just 7 days!
not much marketing, just 1 tweet
tell me what you're building, and I'll spot you free credits for an 8xH100 node for at least a few hours to start.

English

Comet is the ultimate personal knowledge layer.
It completely eliminates the need to open up PKM tools like Roam or Obsidian. It's the most efficient and frictionless way to find notes, tabs, highlights, saved content, etc.
Completely redefines my idea of a "second brain"
English



I manage hundreds (thousands?) of conversations that fall into four groups:
1) long-running, bookmarked - basically my staff
3 examples:
- I have an AI personal trainer/nutritionist I always return to for training/nutrition questions.
- I have one conversation that helped me build my current home Linux box, and I return to it for any HW/OS/SW questions related to it.
- I have several AI professors I use to learn various subjects - one per subject
2) useful, may return to, but not necessarily
examples:
- I saw nice sweet potatoes at the grocery store - asked about sweet potato soup, made soup. A week later, I saw a nice pumpkin - wanted to make a similar soup. Remember that convo, which already knows my equipment and preferences, returned to that conversation for a different soup.
- in general, if I think I've asked a question before, and the context from before will save me some time now, I use search to look at previous conversations, and might continue one of them rather than start a new one
3) One-off questions: I usually ask them in a fresh conversation
4) Truly throwaway questions. Not only do I start a fresh conversation, but I will usually archive/delete it when I'm done. This is when the subject is pretty trivial, and I view it as clutter.
Special case for some long-running conversations: I have also noticed that sometimes overly long context can start to produce weird effects. The LLM starts to hallucinate more, is less reliable about remembering details, and so on. In situations like this I sometimes ask it to generate a detailed summary of everything we have been working on, and I may ask follow-up questions, and then I paste the results into a new conversation and continue from there.
English

When working with LLMs I am used to starting "New Conversation" for each request.
But there is also the polar opposite approach of keeping one giant conversation going forever. The standard approach can still choose to use a Memory tool to write things down in between conversations (e.g. ChatGPT does so), so the "One Thread" approach can be seen as the extreme special case of using memory always and for everything.
The other day I've come across someone saying that their conversation with Grok (which was free to them at the time) has now grown way too long for them to switch to ChatGPT. i.e. it functions like a moat hah.
LLMs are rapidly growing in the allowed maximum context length *in principle*, and it's clear that this might allow the LLM to have a lot more context and knowledge of you, but there are some caveats. Few of the major ones as an example:
- Speed. A giant context window will cost more compute and will be slower.
- Ability. Just because you can feed in all those tokens doesn't mean that they can also be manipulated effectively by the LLM's attention and its in-context-learning mechanism for problem solving (the simplest demonstration is the "needle in the haystack" eval).
- Signal to noise. Too many tokens fighting for attention may *decrease* performance due to being too "distracting", diffusing attention too broadly and decreasing a signal to noise ratio in the features.
- Data; i.e. train - test data mismatch. Most of the training data in the finetuning conversation is likely ~short. Indeed, a large fraction of it in academic datasets is often single-turn (one single question -> answer). One giant conversation forces the LLM into a new data distribution it hasn't seen that much of during training. This is in large part because...
- Data labeling. Keep in mind that LLMs still primarily and quite fundamentally rely on human supervision. A human labeler (or an engineer) can understand a short conversation and write optimal responses or rank them, or inspect whether an LLM judge is getting things right. But things grind to a halt with giant conversations. Who is supposed to write or inspect an alleged "optimal response" for a conversation of a few hundred thousand tokens?
Certainly, it's not clear if an LLM should have a "New Conversation" button at all in the long run. It feels a bit like an internal implementation detail that is surfaced to the user for developer convenience and for the time being. And that the right solution is a very well-implemented memory feature, along the lines of active, agentic context management. Something I haven't really seen at all so far.
Anyway curious to poll if people have tried One Thread and what the word is.
English
youtu.be/PDIeZ9eouSc?fe…
The band and the show
Given my current location Eton Rifles would be more appropriate but I just love this song
RIP Rick & thanks for all the memories
#asaturdaykid

YouTube
English
@timothy_barnes @Apple Only that a large majority on this platform will have no idea what the Apple 1984 ad is :-)
English

openai.com/index/introduc…
“We’re announcing data residency in Europe for ChatGPT Enterprise, ChatGPT Edu, and the API Platform. This helps organizations operating in Europe meet local data sovereignty requirements when using OpenAI products in their businesses and building new solutions with AI.”
English
@bevel_health No payment option on iPhone app - am I missing something
Only got one week free trial
English

Start 2025 strong with 2 months free of Bevel Pro 💪
Here’s how to claim your offer:
1️⃣ Scroll down on the payment screen
2️⃣ Tap “Redeem code"
3️⃣ Enter "2025"
This offer is available to new and returning subscribers for a limited time while supplies last! Don’t miss out.

English

Your voice reveals more about you than you might think.
AI can now decode your personality from a simple conversation.
🌟 Thrilled to share my latest research in Scientific Reports (Nature).

English
English

Wrote a script to tokenize & segment long text into chunks, generate chunk audio using f5_tts_mlx by @lllucas & stitch together. Voice was cloned privately on an M2 Ultra but altered for privacy. The 2:40 long clip generated in 6 min using MLX. So fitting that 🚀 MLX @awnihannun was used to generate the audio for the paper. Happy to share the script. This allows to generate audio for complete docs.
English

Comment below for a chance to win free credits on @pixio_ai! 🎨✨
Join our giveaway and unleash your creativity with AI-powered video generation. Don't miss out!

English
CTO@MN retweetledi


Notebook is crazy 🔥🔥🔥
But but but .....
No multi-lingual support 👎
No custom voices 👎
Introducing Vadoo AI 🤯🤯
Now turn your PDF to podcast in 32+ languages
Tons of voice customisation including Voice cloning
Interested in getting access ? Comment "Interested" below
English
@BenjaminDEKR @Digen_AI In a world where AI can sway, For social good, it paves the way. With avatars so keen, We'll make a difference seen, Let's use these invites today!
English

I have 50 invitation links for @Digen_AI AI video avatar / lipsync platform with 1500 free credits each.
If you want an invite, comment here with one sentence of why you need 'em. Bonus points if it's a limerick.
English
CTO@MN retweetledi
