@guillaumekasba @PartiLiberteFr Bravo cher Guillaume, vive la liberté !
Español
César Mourot 🏴☠️
138 posts

@CesarMourot
Entrepreneur, investisseur, et host sur YouTube. Podcast sur YouTube en lien.







Today is a monumentous day for quantum computing and cryptography. Two breakthrough papers just landed (links in next tweet). Both papers improve Shor's algorithm, infamous for cracking RSA and elliptic curve cryptography. The two results compound, optimising separate layers of the quantum stack. The results are shocking. I expect a narrative shift and a further R&D boost toward post-quantum cryptography. The first paper is by Google Quantum AI. They tackle the (logical) Shor algorithm, tailoring it to crack Bitcoin and Ethereum signatures. The algorithm runs on ~1K logical qubits for the 256-bit elliptic curve secp256k1. Due to the low circuit depth, a fast superconducting computer would recover private keys in minutes. I'm grateful to have joined as a late paper co-author, in large part for the chance to interact with experts and the alpha gleaned from internal discussions. The second paper is by a stealthy startup called Oratomic, with ex-Google and prominent Caltech faculty. Their starting point is Google's improvements to the logical quantum circuit. They then apply improvements at the physical layer, with tricks specific to neutral atom quantum computers. The result estimates that 26,000 atomic qubits are sufficient to break 256-bit elliptic curve signatures. This would be roughly a 40x improvement in physical qubit count over previous state-of-the-art. On the flip side, a single Shor run would take ~10 days due to the relatively slow speed of neutral atoms. Below are my key takeaways. As a disclaimer, I am not a quantum expert. Time is needed for the results to be properly vetted. Based on my interactions with the team, I have faith the Google Quantum AI results are conservative. The Oratomic paper is much harder for me to assess, especially because of the use of more exotic qLDPC codes. I will take it with a grain of salt until the dust settles. → q-day: My confidence in q-day by 2032 has shot up significantly. IMO there's at least a 10% chance that by 2032 a quantum computer recovers a secp256k1 ECDSA private key from an exposed public key. While a cryptographically-relevant quantum computer (CRQC) before 2030 still feels unlikely, now is undoubtedly the time to start preparing. → censorship: The Google paper uses a zero-knowledge (ZK) proof to demonstrate the algorithm's existence without leaking actual optimisations. From now on, assume state-of-the-art algorithms will be censored. There may be self-censorship for moral or commercial reasons, or because of government pressure. A blackout in academic publications would be a tell-tale sign. → cracking time: A superconducting quantum computer, the type Google is building, could crack keys in minutes. This is because the optimised quantum circuit is just 100M Toffoli gates, which is surprisingly shallow. (Toffoli gates are hard because they require production of so-called "magic states".) Toffoli gates would consume ~10 microseconds on a superconducting platform, totalling ~1,000 sec of Shor runtime. → latency optimisations: Two latency optimisations bring key cracking time to single-digit minutes. The first parallelises computation across quantum devices. The second involves feeding the pubkey to the quantum computer mid-flight, after a generic setup phase. → fast- and slow-clock: At first approximation there are two families of quantum computers. The fast-clock flavour, which includes superconducting and photonic architectures, runs at roughly 100 kHz. The slow-clock flavour, which includes trapped ion and neutral atom architectures, runs roughly 1,000x slower (~100 Hz, or ~1 week to crack a single key). → qubit count: The size-optimised variant of the algorithm runs on 1,200 logical qubits. On a superconducting computer with surface code error correction that's roughly 500K physical qubits, a 400:1 physical-to-logical ratio. The surface code is conservative, assuming only four-way nearest-neighbour grid connectivity. It was demonstrated last year by Google on a real quantum computer. → future gains: Low-hanging fruit is still being picked, with at least one of the Google optimisations resulting from a surprisingly simple observation. Interestingly, AI was not (yet!) tasked to find optimisations. This was also the first time authors such as Craig Gidney attacked elliptic curves (as opposed to RSA). Shor logical qubit count could plausibly go under 1K soonish. → error correction: The physical-to-logical ratio for superconducting computers could go under 100:1. For superconducting computers that would be mean ~100K physical qubits for a CRQC, two orders of magnitude away from state of the art. Neutral atoms quantum computers are amenable to error correcting codes other than the surface code. While much slower to run, they can bring down the physical to logical qubit ratio closer to 10:1. → Bitcoin PoW: Commercially-viable Bitcoin PoW via Grover's algorithm is not happening any time soon. We're talking decades, possibly centuries away. This observation should help focus the discussion on ECDSA and Schnorr. (Side note: as unofficial Bitcoin security researcher, I still believe Bitcoin PoW is cooked due to the dwindling security budget.) → team quality: The folks at Google Quantum AI are the real deal. Craig Gidney (@CraigGidney) is arguably the world's top quantum circuit optimisooor. Just last year he squeezed 10x out of Shor for RSA, bringing the physical qubit count down from 10M to 1M. Special thanks to the Google team for patiently answering all my newb questions with detailed, fact-based answers. I was expecting some hype, but found none.





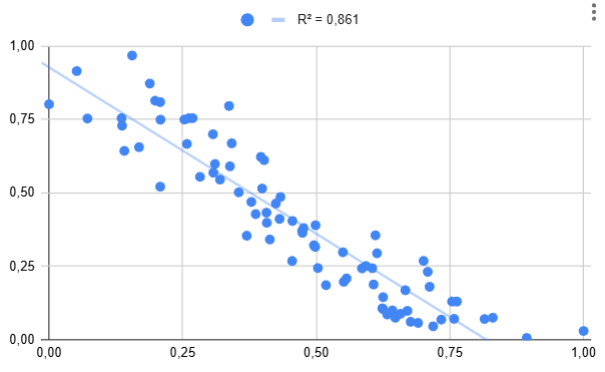
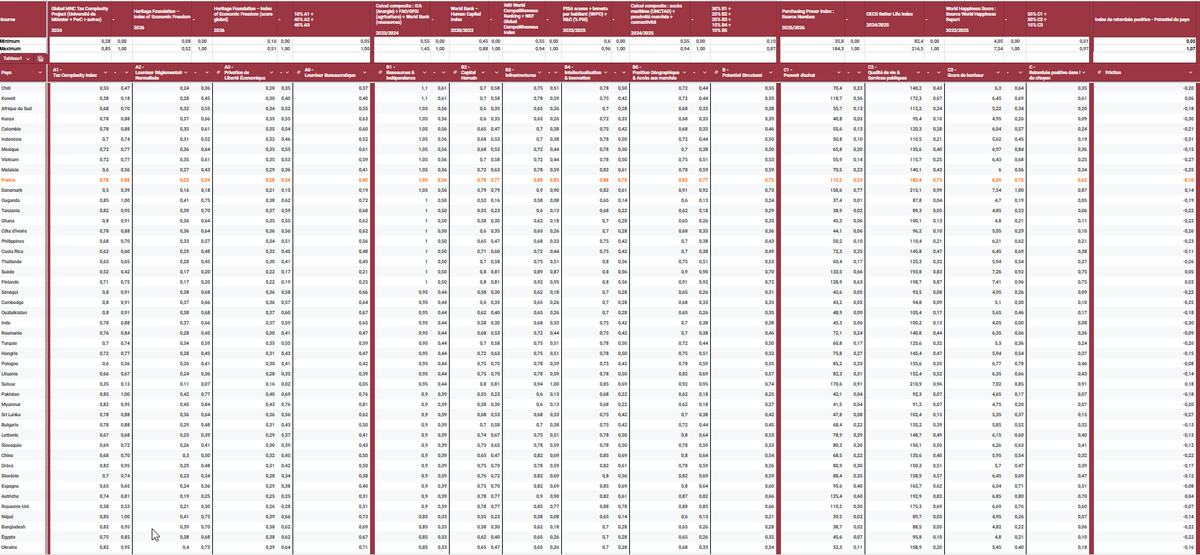
Classement général de l'efficacité d'un pays à transférer son potentiel structurel sur le bonheur de ses habitants. La France est 67ème/80 juste derrière l'Inde y a ZERO blague. Méthodologie plus bas : 1 - Finlande 2 - Croatie 3 - Estonie 4 - Luxembourg 5 - Portugal 6 - Zimbabwe 7 - Slovénie 8 - Lettonie 9 - Suède 10 - Roumanie 11 - Lituanie 12 - Pologne 13 - Autriche 14 - Pays-Bas 15 - Danemark 16 - Ouzbékistan 17 - Irlande 18 - Slovaquie 19 - Islande 20 - Suisse 21 - Népal 22 - Émirats Arabes Unis 23 - Costa Rica 24 - Bulgarie 25 - Hongrie 26 - Espagne 27 - Israël 28 - Ukraine 29 - Royaume-Uni 30 - Cambodge 31 - Bahrain 32 - Égypte 33 - Singapour 34 - Nouvelle-Zélande 35 - Afrique du Sud 36 - Bangladesh 37 - Ghana 38 - Koweït 39 - Italie 40 - Grèce 41 - Belgique 42 - Sénégal 43 - Japon 44 - Pakistan 45 - Allemagne 46 - Nigeria 47 - Ouganda 48 - Tanzanie 49 - Myanmar 50 - Chili 51 - Angola 52 - Norvège 53 - Kazakhstan 54 - Colombie 55 - Côte d'Ivoire 56 - Mongolie 57 - Sri Lanka 58 - Turquie 59 - Philippines 60 - Kenya 61 - Mexique 62 - Indonésie 63 - Chine 64 - Canada 65 - Australie 66 - Inde 67 - France 68 - Arabie Saoudite 69 - Malaisie 70 - Vietnam 71 - États-Unis 72 - Thaïlande 73 - Hong Kong 74 - Brésil 75 - Pérou 76 - Argentine 77 - Corée du Sud 78 - Iran 79 - Russie 80 - Venezuela