Sabitlenmiş Tweet
charbob
146 posts



Has anyone used Jackrong/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled for agents locally? How did it fair?
English
@Hangsiin What use-cases?
I was running tool-use-heavy research today with a few MCPs and it was extraordinarily lazy.
And it wouldn’t believe me no matter the prompt about the date (it kept thinking it was 2024/25).
120 tok/s was nice but not worth the lobotomy vs Qwen3.5 27b
English

I’m really impressed with Gemma 4. (26B-A4B-it, Q4_K_M)
What stands out most is that it doesn’t feel awkward in Korean at all. It feels like a genuinely solid, well-built model.
I had never felt this from a model of this size before.
The gap compared with Gemma 3 also feels really significant.
I’m still testing it, but for a few use cases, I’m starting to feel that moving to a local setup would be worth it.
This is a really impressive release!
English



Proud owner of an RTX Pro 6000
Best investment ever made
Espen JD@Snixtp
Buy a GPU RTX Pro 6000 is mine
English



@zw0404 @eleven_32 Curious to hear what you think. I was not impressed with 26b today, will try 31b tomorrow.
English


@johnny_everson LibreChat is neat. A bit heavy but it works.
If you’re doing chat and not coding, have you tried qwen3.5-35b-a3b? Higher tok/s is not only nice for chat, but also means faster iteration/turnaround on tools
I am liking qwopus27b v3 on my 3090 but I mainly code
English

To run a LLM service that uses tool calling heavily, e.g. web search, url context (find specific info in a website). I am using Qwopus 27B and tool calling examples from unsloth. Is this the right way to do it or should I use lib or existing app, like open web ui?
English
@LottoLabs Played with qwopus-27b v3 and Gemma 26b today (Q4). Qwopus was great, meaningful small improvement over vanilla 27b in opencode & LibreChat for tool-heavy research and coding.
Gemma was total ass. Very lazy model. I could not convince it that it’s 2026
Llama.cpp + RTX 3090
English

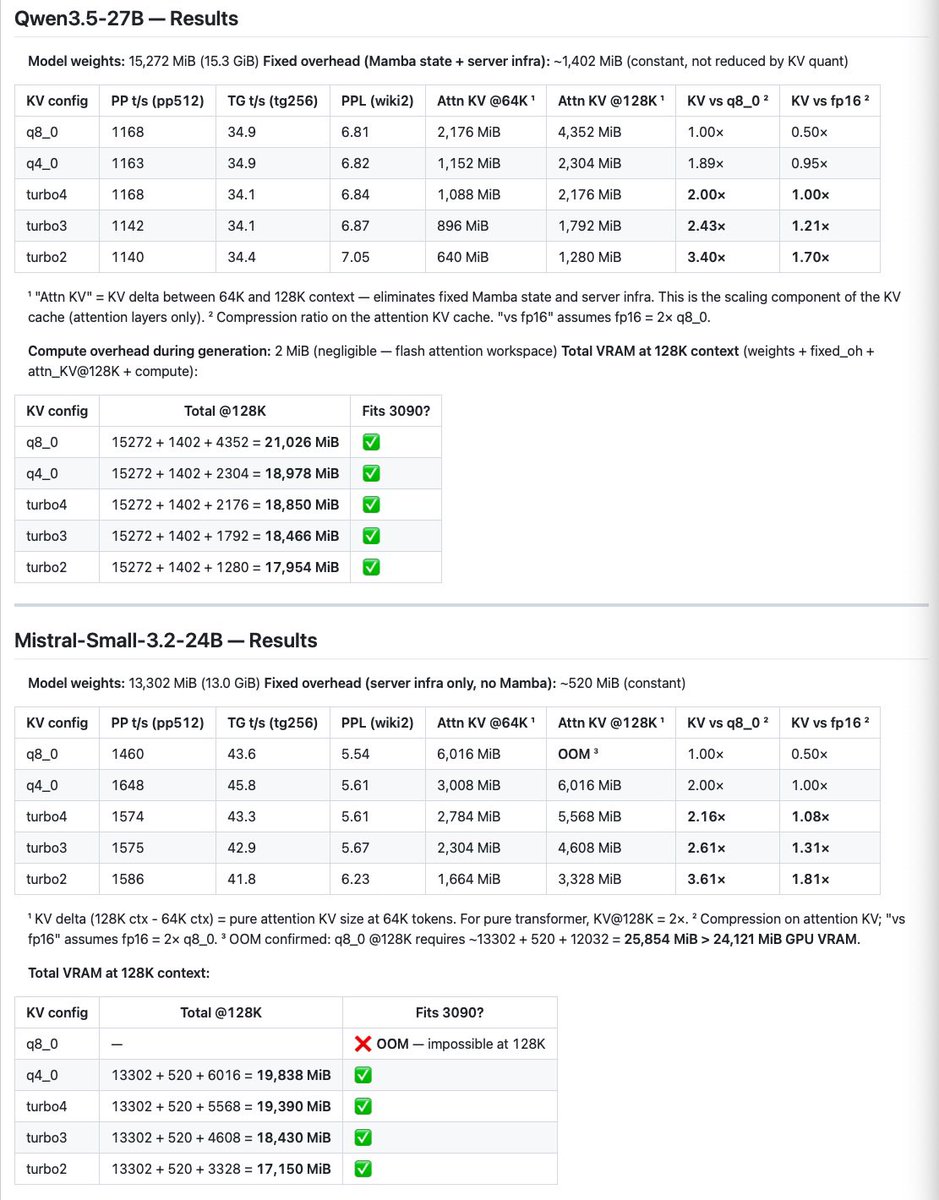
@no_stp_on_snek Results:
Would be fun to test on your new variable-quant setup as well. Is there a stable PR/flag to try?
English
@no_stp_on_snek I’ll post compression results for q3.5-27b (also q4) and mistral-24b q4 today
English

New TurboQuant result: not all V layers are created equal.
TL;DR: turbo2 compression, turbo3 quality, 15 lines of layer policy
Boundary V: keep K at q8_0, protect the first 2 and last 2 V layers with full precision, compress everything in the middle at turbo2. 15 lines of code.
Tested on 4 models across Metal. Beats uniform turbo2-V every time. Holds at 8K context. NIAH retrieval still works.
The insight: boundary layers handle the input and output transformations. Mess with their V precision and you pay for it everywhere downstream. Leave the middle layers alone and they barely notice.
Writeup with all the numbers:
github.com/TheTom/turboqu…

English
@no_stp_on_snek Will do - feel free to @ me next time you need more 3090 benchs.
Thanks for all you’re doing!
English
@Char__Bob really appreciate you running these 🙏
i don’t have a CUDA box handy to repro, but i’ll loop in some folks on my side to dig into it
if you’re able to open an issue with your setup + commands + logs that would help a ton in the meantime
English
turbo2 is now on metal. 2-bit kv cache, 6.4x compression. the full turbo family is complete
development order was 3, 4, 2 for no reason whatsoever
ppl results (qwen 35b moe, m5 max):
- turbo4 (4-bit): 6.125, +0.23% vs q8_0
- turbo3 (3-bit): 6.176, +1.06%
- turbo2 (2-bit): 6.507, +6.48%
turbo2 uniform is rough on quality but the real use is asymmetric: turbo2 keys + turbo3 values. keys tolerate more compression than values. buun's cuda data shows that combo at +3.88% ppl ... way better than uniform turbo2. i'll need to test that soon.
166 lines of metal shader. no cuda changes, no turbo3/turbo4 code touched. purely additive. codex reviewed, build clean, ppl verified
-ctk turbo2 -ctv turbo2 if you're feeling dangerous
-ctk turbo2 -ctv turbo3 if you want the sweet spot
Still haven't cracked decode speed issues with sub m5 chips...
#top-of-tree-results" target="_blank" rel="nofollow noopener">github.com/TheTom/turboqu…

English
@no_stp_on_snek turbo4/4: CRASH — SET_ROWS not CUDA-ported
mixed configs (turbo3k/turbo2v and turbo2k/turbo3v): decode fine (~88 t/s) but prefill ~11.5x slower than baseline — looks like a bug
KV savings scale linearly. at 131k ctx turbo3/3 saves ~1.25 GB and turbo2/2 saves ~1.5 GB vs q8_0
English
@no_stp_on_snek RTX 3090 24GB benchmarks on your tree (Qwen3.5-9B Q4_K_M, n_ctx=2048):
turbo3/3: PPL 8.31, decode 99.79 t/s, prefill 3727 t/s, 215 MiB KV (-8.5% vs baseline)
turbo2/2: PPL 8.66, decode 100.73 t/s, prefill 3702 t/s, 211 MiB KV (-10.2% vs baseline)
English
@adrgrondin @liquidai @LocallyAIApp Been running @LocallyAIApp on my iPhone + iPad for a min. So sick.
Is MCP/tool use for web search, etc, on your roadmap?
English

Quick demo of LFM 2.5 VL 1.6B model by @liquidai that I recently added to @LocallyAIApp
Running locally on iPhone 17 Pro at ~90tk/s with MLX
Small vision-language models are improving fast
English