Chicago HAI retweetledi

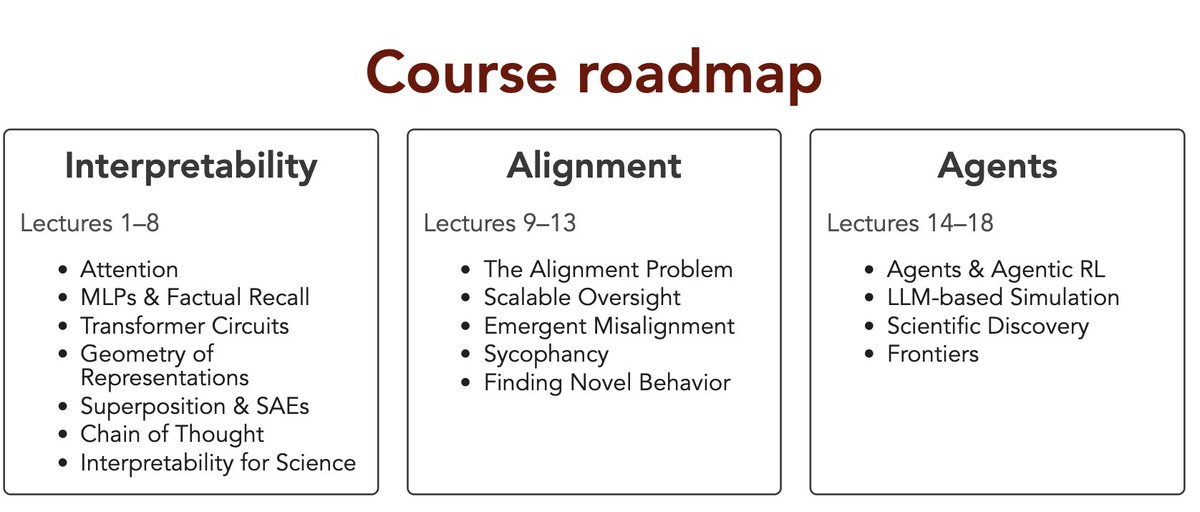
This quarter I am teaching a new course titled Large Language Models. The focus is on interpretability, alignment, and agents.
All the course materials are public: uchicago-llm-course.github.io.
I have been procrastinating for three weeks for this post, but hope that the materials are useful!
English