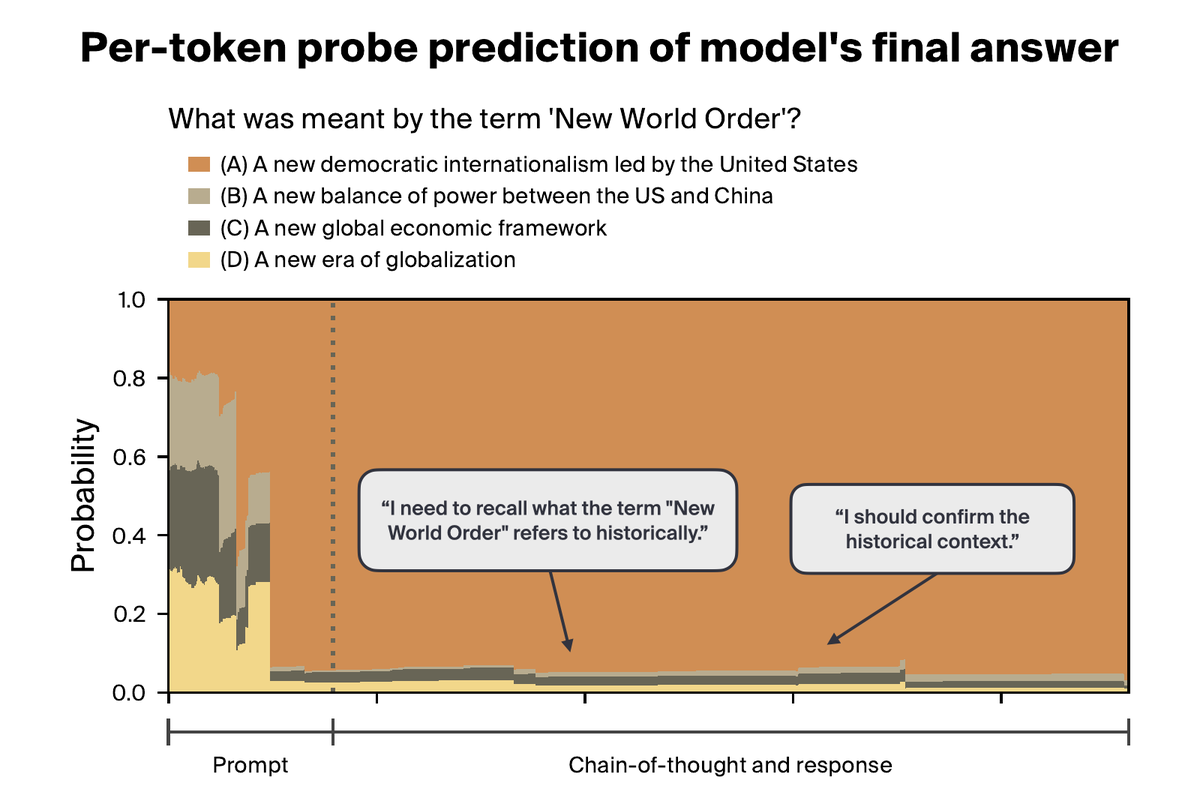
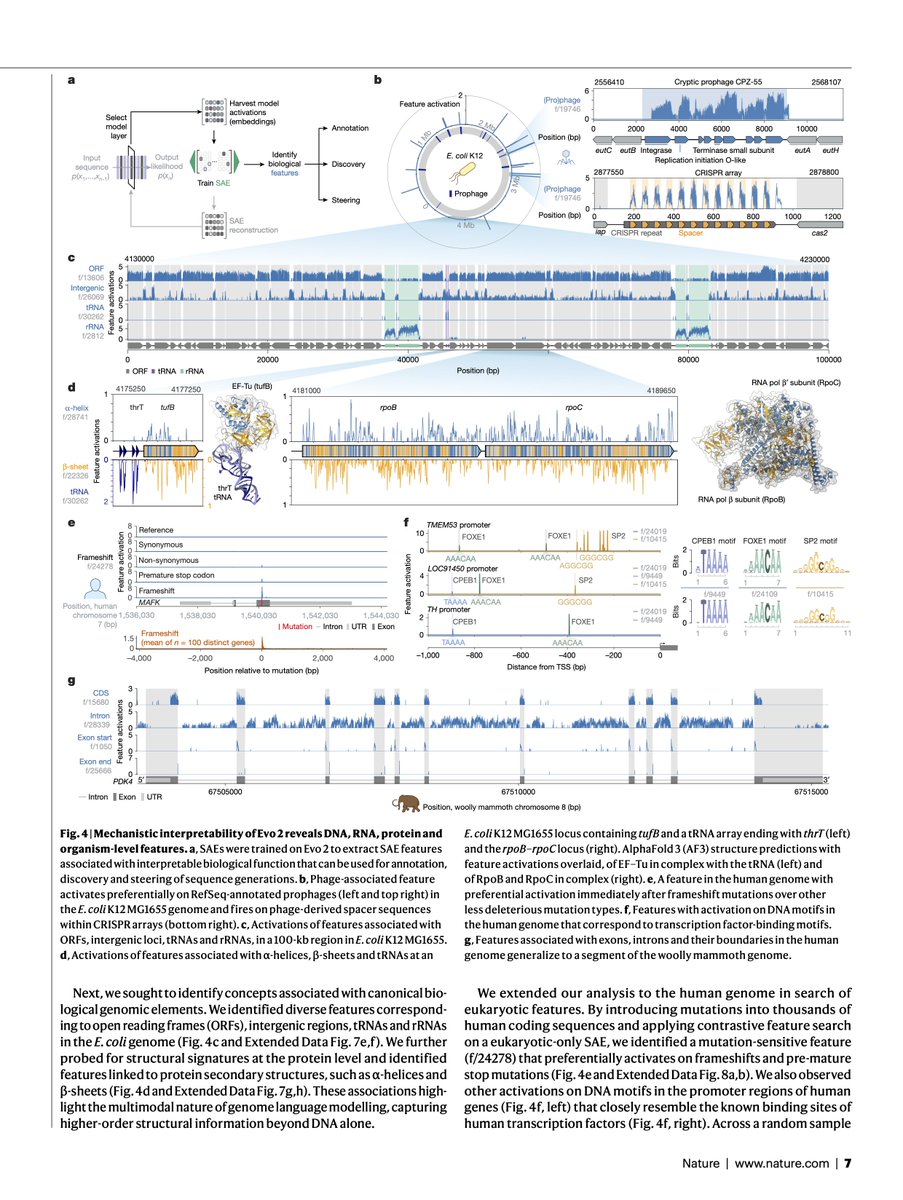
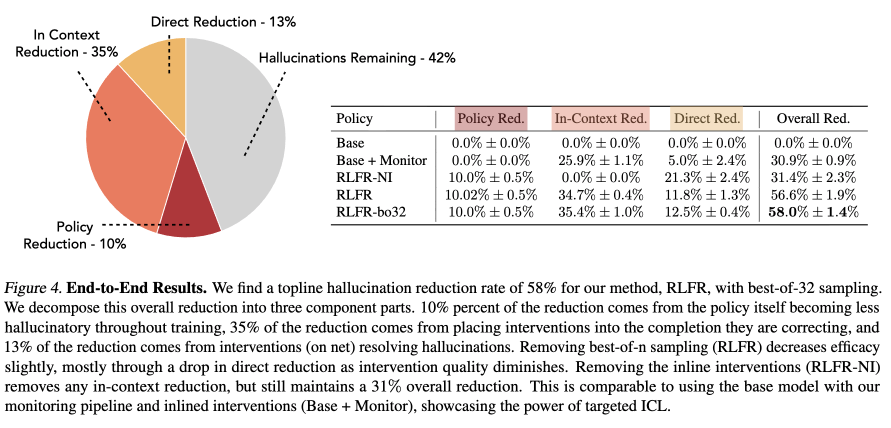
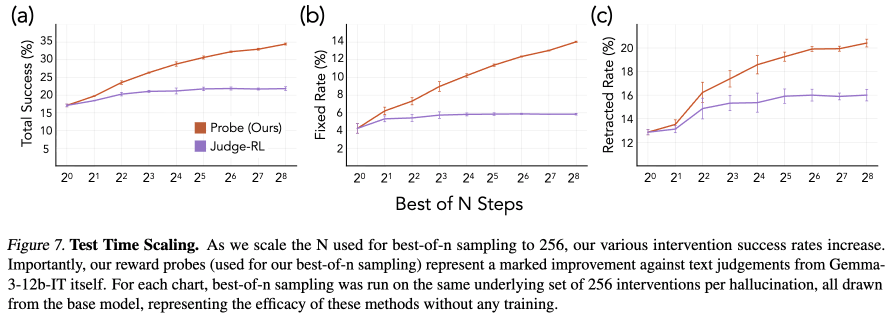
Sabitlenmiş Tweet

🚨New paper! We know models learn distinct in-context learning strategies, but *why*? Why generalize instead of memorize to lower loss? And why is generalization transient?
Our work explains this & *predicts Transformer behavior throughout training* without its weights! 🧵
1/
GIF
English