Sabitlenmiş Tweet

Clay Eltzroth 🤟
19.6K posts

@Clay1016
Product Manager @TheTerminal | #AI #MachineLearning for News | ex-journo @business | @Citadel1842 '02 Grad | Opinions mine, RT's not endorsements



Apparently workers in China have been creating “colleagues.skill” to distill their coworkers hoping to make them redundant hence saving themselves. In response someone has recently invented an “anti-distillation.skill” that has gone viral on GitHub.🤣


Ashton Kutcher turned $30 million into $1.3 BILLION in less than 3 years. He is up 43x on his OpenAI investment.






Odd to hear people say the reason we can trust journalism but not prediction markets is that journalists have the public interest at heart, while traders are selfish & greedy.

OpenClaw doesn't belong in production. We built PokeeClaw — enterprise-secure AI agents, zero setup, 1,000+ app integrations. Try now: pokee.ai First 500 to follow @Pokee_AI, comment “PokeeClaw”, like & repost get 1 month free.



Morgan Stanley predicts a massive AI breakthrough driven by a huge spike in computing power across major U.S. laboratories. Increasing the amount of hardware used for training by 10x can effectively double the intelligence of these models. The recently released GPT-5.4 Thinking model already matches human experts on professional tasks with a score of 83% on the GDPVal benchmark. The biggest hurdle for this growth is an energy crisis, with the U.S. power grid facing a shortfall of 18 gigawatts by December-28. To keep running, developers are bypassing the grid by taking over Bitcoin mining sites and using natural gas turbines for their AI factories. This shift is creating a solid investment cycle where 15-year leases on data centers generate high financial yields for every watt consumed. Large companies are already reducing their staff numbers because these new AI tools can perform professional work for a tiny fraction of the cost. Researchers expect AI to begin recursive self-improvement by June-27, meaning the software will autonomously upgrade its own code without human help. The future economy will likely treat raw intelligence as a commodity that is manufactured by these massive computing and energy clusters.



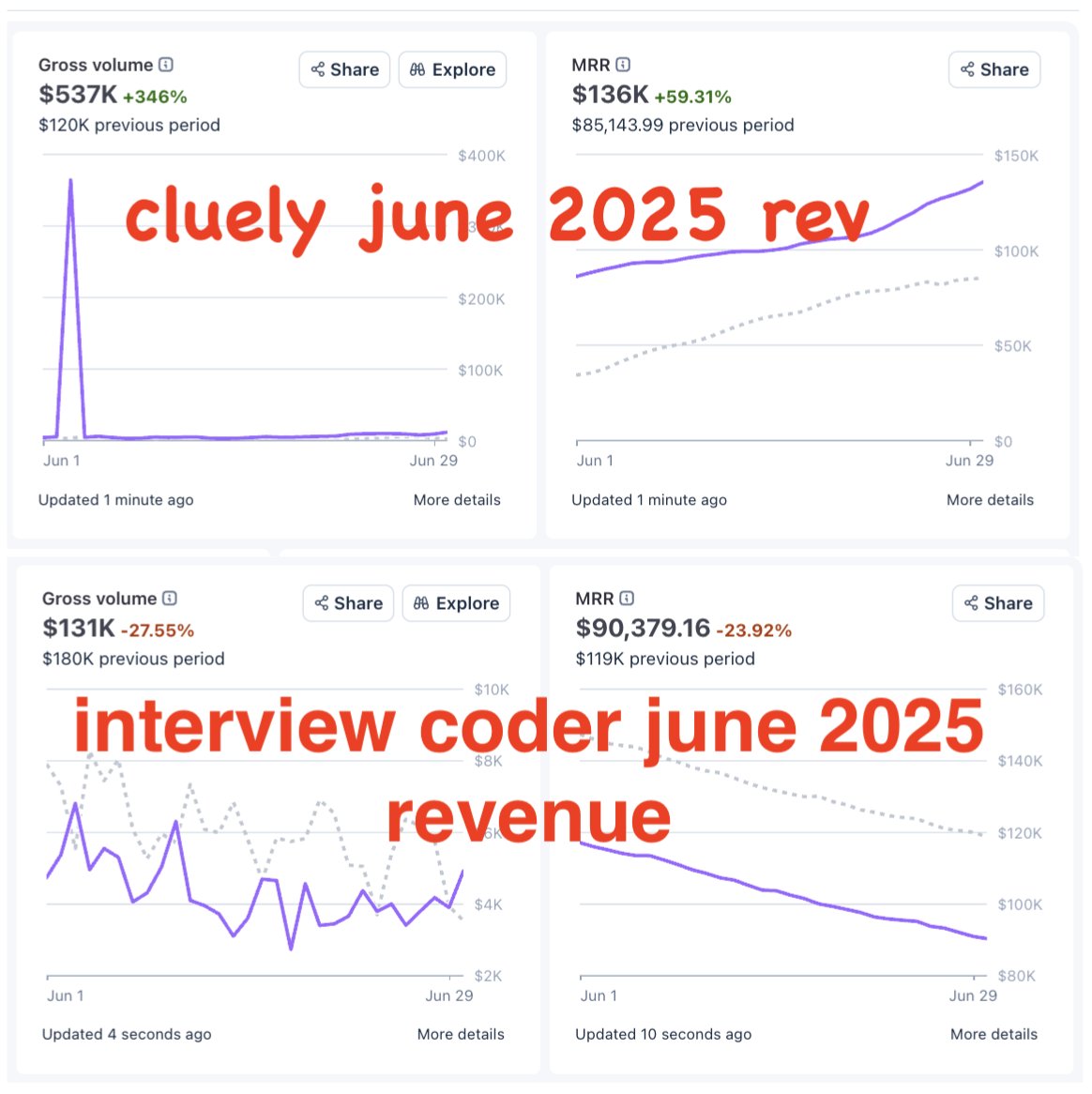
this must have been a straight up lie right? at a $20/month sub they would have needed 29166 paid subscribers to justify this no amount of attention can get that many people to open their wallets when you don’t have a stable and working product

Jensen: OpenAI to go public towards end of the year. We expanded the capacity of OpenAI from Azure to OCI to AWS "ramping AWS like mad" We now work with Anthropic. Expanding Anthropic's capacity at AWS and Azure



I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. github.com/karpathy/autor… Part code, part sci-fi, and a pinch of psychosis :)
