Sabitlenmiş Tweet

1/🚀 Excited to announce Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation!
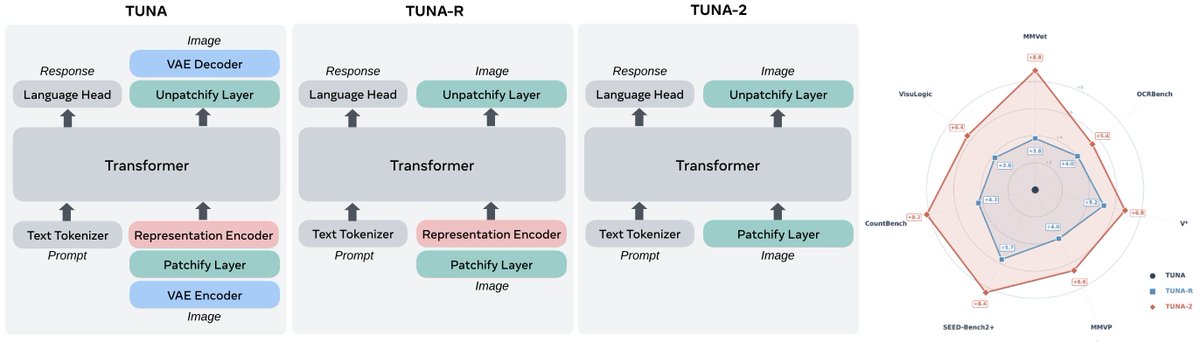
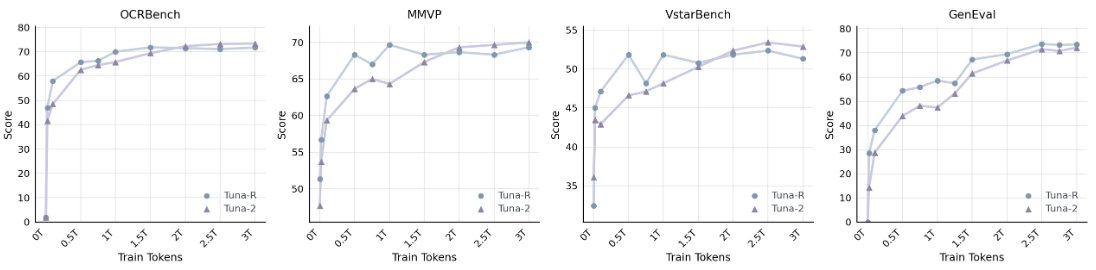
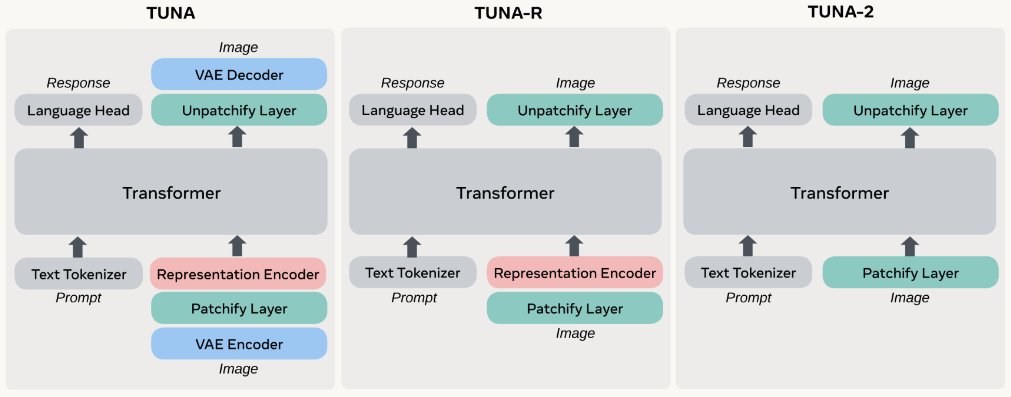
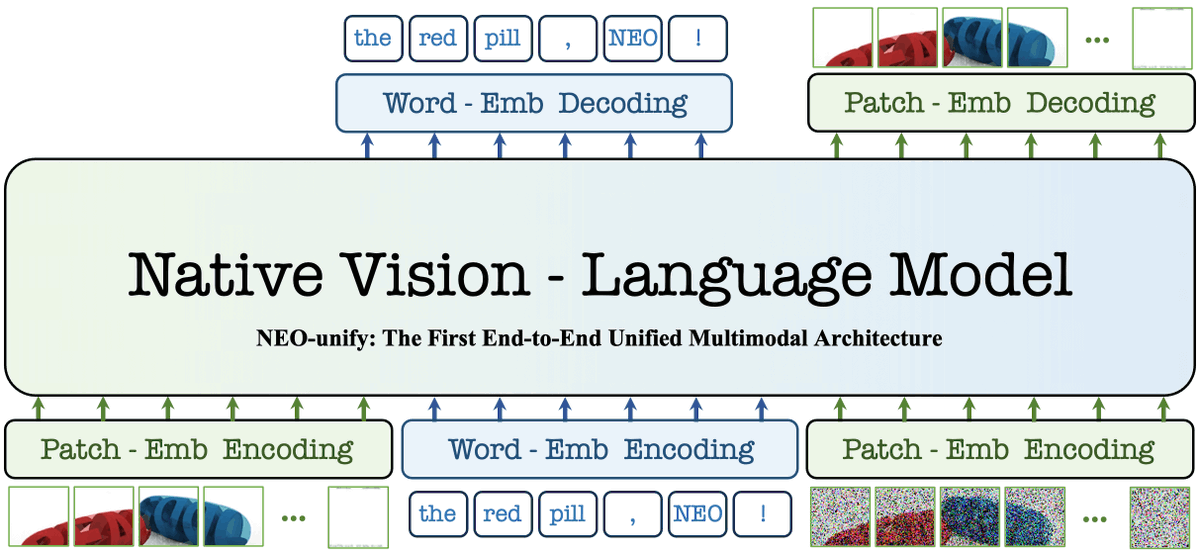
We built an omni model utilizing direct patch embedding layers for raw image inputs and achieves SOTA in multimodal understanding AND generation.
Paper: huggingface.co/papers/2604.24…
Code: github.com/facebookresear…
Thanks to all the co-authors! @__Johanan, @wmren993, @xiaoke_shawn_h, @ShoufaChen, @TianhongLi6, Mengzhao Chen, Yatai Ji, Sen He, Jonas Schult, Belinda Zeng, Tao Xiang, @WenhuChen, Ping Luo, @LukeZettlemoyer!

English