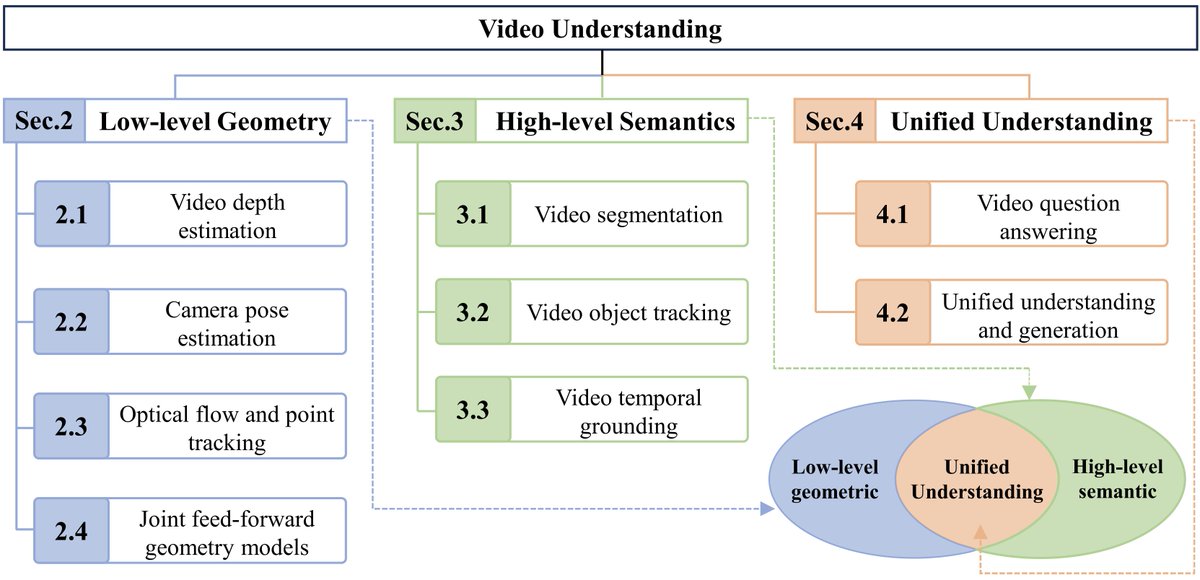
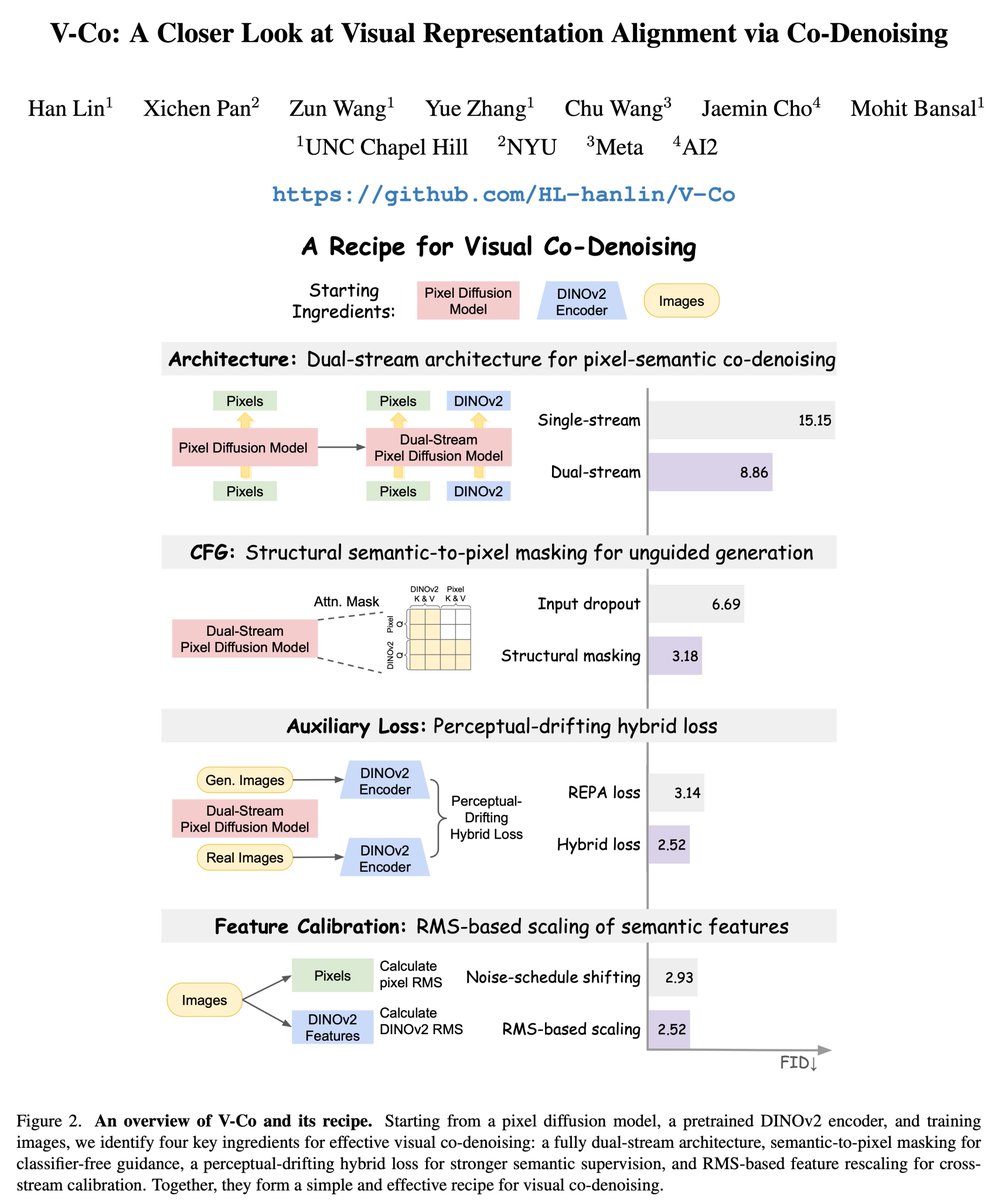
Sabitlenmiş Tweet

Huge thanks to @_akhaliq for sharing our work!
We introduce TUNA, a unified multimodal model that handles both image/video understanding and generation/editing. The key is a unified, end-to-end learned visual representation.
AK@_akhaliq
Meta presents TUNA Taming Unified Visual Representations for Native Unified Multimodal Models
English