Sabitlenmiş Tweet

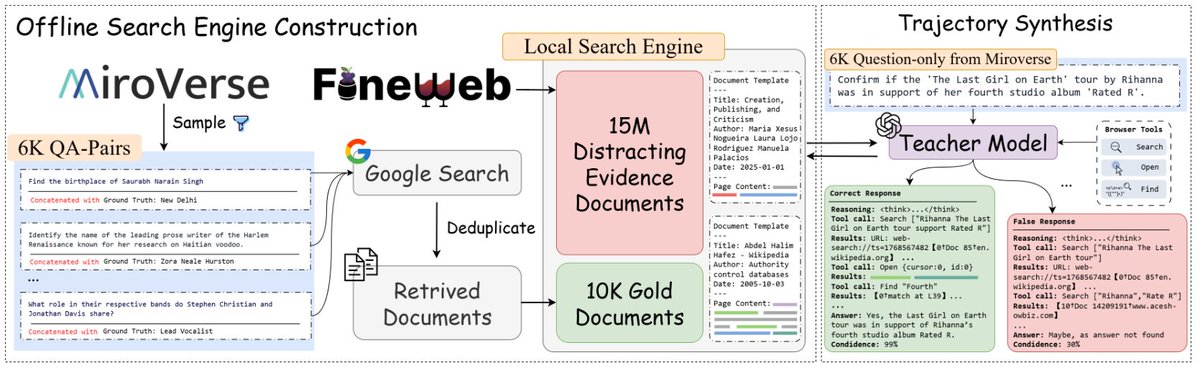
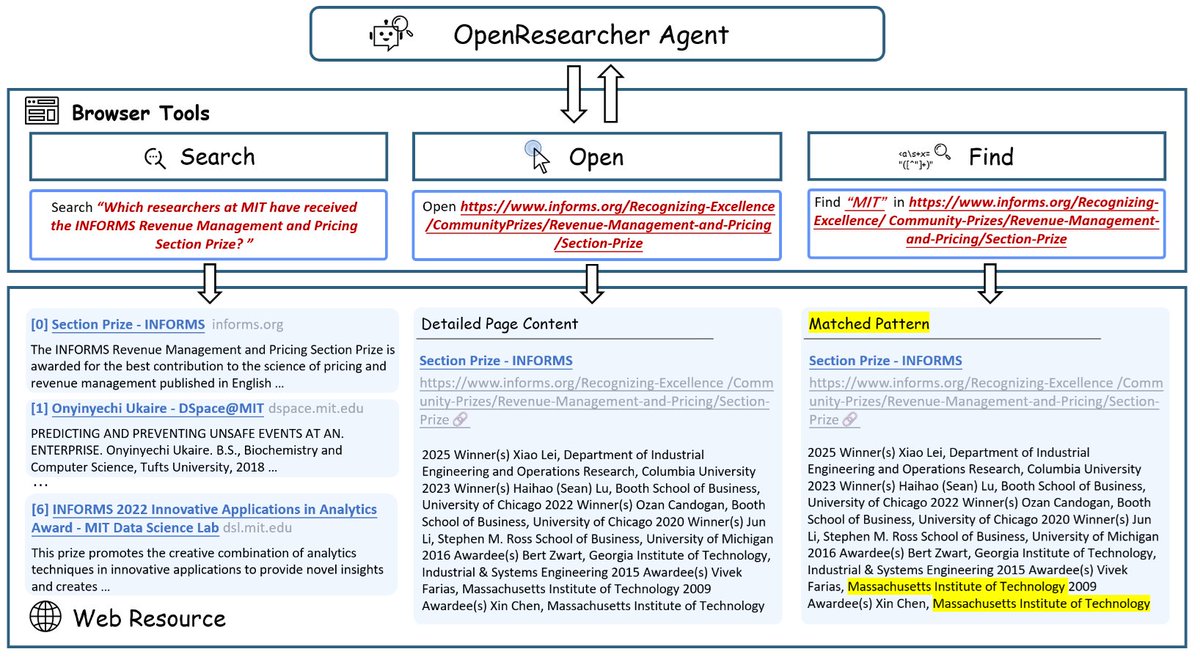
1/ 🚀 We’re excited to share Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation!
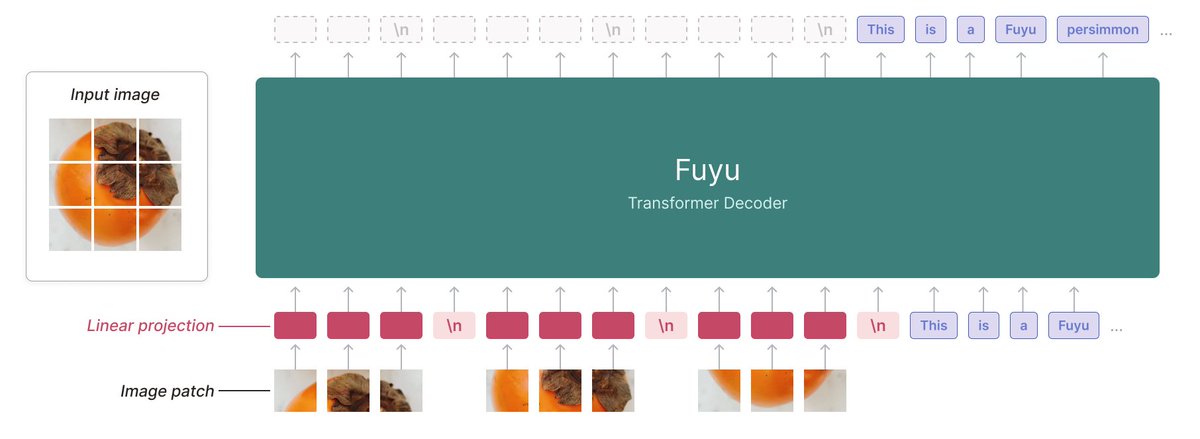
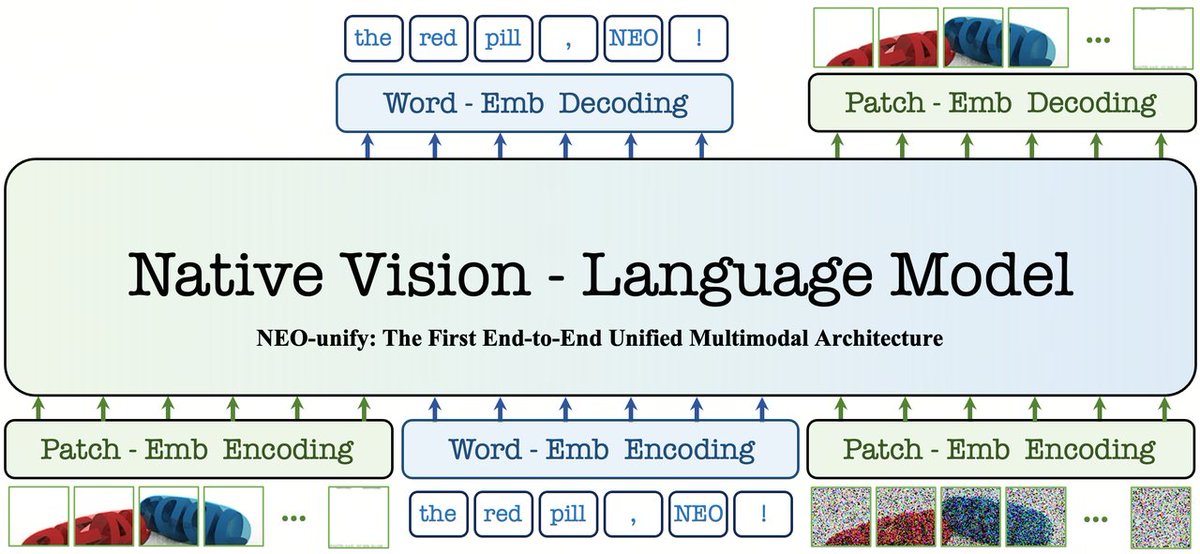
Tuna-2 is a native unified multimodal model that supports visual understanding, text-to-image generation, and image editing directly from pixel embeddings. 🐟✨
📄 Paper: arxiv.org/abs/2604.24763
🌐 Project: tuna-ai.org/tuna-2
💻 Code: github.com/facebookresear…
Most unified multimodal models still rely on pretrained vision encoders, which add architectural complexity and can create representation mismatches between understanding and generation.
Tuna-2 asks a simple question: Do we still need vision encoders? 👀
Our answer is No! Tuna-2 has a completely encoder-free architecture, where images are processed directly by a unified transformer together with text tokens.
Take a glimpse at what our model can generate ↓ 🎨🖼️

English