Sabitlenmiş Tweet
Doc
2.3K posts


Doc
@CoreyClarkPhD
@BalancedMT CTO, Deputy Director Research at @SMUGuildhall & Assoc Prof SMU CS, Director @HuMInGameLab: Merging Games, AI/ML and Distributed Computing
Dallas, TX Katılım Ekim 2011
69 Takip Edilen431 Takipçiler
Doc retweetledi

Huh. Looks like Plato was right.
A new paper shows all language models converge on the same "universal geometry" of meaning. Researchers can translate between ANY model's embeddings without seeing the original text.
Implications for philosophy and vector databases alike.

English
Doc retweetledi

Some people today are discouraging others from learning programming on the grounds AI will automate it. This advice will be seen as some of the worst career advice ever given. I disagree with the Turing Award and Nobel prize winner who wrote, “It is far more likely that the programming occupation will become extinct [...] than that it will become all-powerful. More and more, computers will program themselves.” Statements discouraging people from learning to code are harmful!
In the 1960s, when programming moved from punchcards (where a programmer had to laboriously make holes in physical cards to write code character by character) to keyboards with terminals, programming became easier. And that made it a better time than before to begin programming. Yet it was in this era that Nobel laureate Herb Simon wrote the words quoted in the first paragraph. Today’s arguments not to learn to code continue to echo his comment.
As coding becomes easier, more people should code, not fewer!
Over the past few decades, as programming has moved from assembly language to higher-level languages like C, from desktop to cloud, from raw text editors to IDEs to AI assisted coding where sometimes one barely even looks at the generated code (which some coders recently started to call vibe coding), it is getting easier with each step.
I wrote previously that I see tech-savvy people coordinating AI tools to move toward being 10x professionals — individuals who have 10 times the impact of the average person in their field. I am increasingly convinced that the best way for many people to accomplish this is not to be just consumers of AI applications, but to learn enough coding to use AI-assisted coding tools effectively.
One question I’m asked most often is what someone should do who is worried about job displacement by AI. My answer is: Learn about AI and take control of it, because one of the most important skills in the future will be the ability to tell a computer exactly what you want, so it can do that for you. Coding (or getting AI to code for you) is a great way to do that.
When I was working on the course Generative AI for Everyone and needed to generate AI artwork for the background images, I worked with a collaborator who had studied art history and knew the language of art. He prompted Midjourney with terminology based on the historical style, palette, artist inspiration and so on — using the language of art — to get the result he wanted. I didn’t know this language, and my paltry attempts at prompting could not deliver as effective a result.
Similarly, scientists, analysts, marketers, recruiters, and people of a wide range of professions who understand the language of software through their knowledge of coding can tell an LLM or an AI-enabled IDE what they want much more precisely, and get much better results. As these tools are continuing to make coding easier, this is the best time yet to learn to code, to learn the language of software, and learn to make computers do exactly what you want them to do.
[Original text: deeplearning.ai/the-batch/issu… ]
English
Doc retweetledi

I will run AGI at home or die trying.
DeepSeek R1 should run fast on these macs. They have a total of 896GB unified memory @ 3557GB/s

DeepSeek@deepseek_ai
🚀 DeepSeek-R1 is here! ⚡ Performance on par with OpenAI-o1 📖 Fully open-source model & technical report 🏆 MIT licensed: Distill & commercialize freely! 🌐 Website & API are live now! Try DeepThink at chat.deepseek.com today! 🐋 1/n
English
Doc retweetledi


Understanding LLMs from Scratch Using Middle School Math by @_Rohit_Patel_ in @TDataScience towardsdatascience.com/understanding-…
English
Doc retweetledi

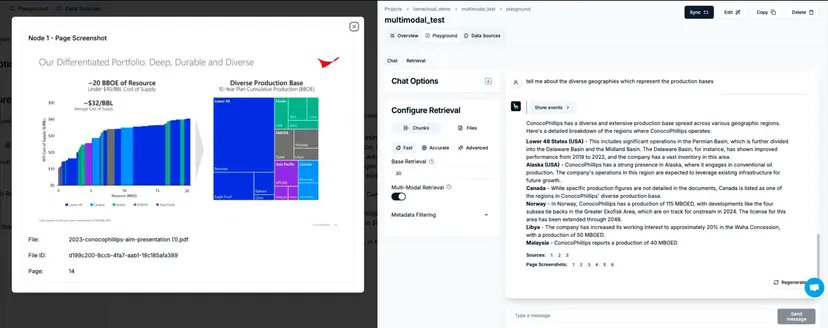
You can now point to a bucket of PDFs, Powerpoints and other files in Sharepoint and do RAG over them in minutes - while having full confidence that the system absorbs complex spatial layouts, nested tables, and visual elements like charts and diagrams.
The trick: Parse, index, and retrieve both text and image chunks. Ensure that both text and images are fed to a multimodal model. 💡
LlamaCloud makes this possible so that you don’t have to spend weeks tuning your RAG stack to make it multimodal.
Huge shoutout to @thesourabhd for driving this effort.
Check out my blog post: llamaindex.ai/blog/multimoda…
If you’re interested in trying it out, signup here: cloud.llamaindex.ai
If you’re interested in using this within your company, come talk to us! llamaindex.ai/contact
LlamaIndex 🦙@llama_index
Today we’re excited to launch multimodal capabilities in LlamaCloud, which gives you the full toolkit to build e2e multimodal RAG pipelines across any unstructured data in minutes - whether it’s over marketing slide decks, legal/insurance contracts, finance reports. All you have to do is toggle the “multi-modal indexing” setting in LlamaCloud, and we will index each page as both a text and image chunk. You can easily validate your pipeline through our chat interface - includes image source as citations - or plug it into your application through an API. Check out our full launch blog post along with an example notebook showing you how to build with this API! Blog: llamaindex.ai/blog/multimoda… Notebook: github.com/run-llama/llam… Come talk to us: llamaindex.ai/contact
English
Doc retweetledi

Announcing reader-lm-0.5b and reader-lm-1.5b, jina.ai/news/reader-lm… two Small Language Models (SLMs) inspired by Jina Reader, and specifically trained to generate clean markdown directly from noisy raw HTML. Both models are multilingual and support a context length of up to 256K tokens. Despite their compact size, these models achieve state-of-the-art performance on this HTML2Markdown task, outperforming larger LLM counterparts while being only 1/50th of their size.
English
Doc retweetledi

Introducing PaperQA2, the first AI agent that conducts entire scientific literature reviews on its own.
PaperQA2 is also the first agent to beat PhD and Postdoc-level biology researchers on multiple literature research tasks, as measured both by accuracy on objective benchmarks and assessments by human experts. We are publishing a paper and open-sourcing the code.
This is the first example of AI agents exceeding human performance on a major portion of scientific research, and will be a game-changer for the way humans interact with the scientific literature.
Paper and code are below, and congratulations in particular to @m_skarlinski, @SamCox822, @jonmlaurent, James Braza, @MichaelaThinks, @mjhammerling, @493Raghava, @andrewwhite01, and others who pulled this off. 1/
English
Doc retweetledi

Announcing: The initial release of my 1st project since joining the amazing team here at @answerdotai
gpu.cpp
Portable C++ GPU compute using WebGPU
Links + info + a few demos below 👇
GIF
English
Doc retweetledi

The inaugural AI 75 list is out and two #SMU faculty members are on it! Khaled Abdelghany and @CoreyClarkPhD have been recognized by @DallasInnovates for their innovative work in the #AI field among leaders in the #Dallas area. Congratulations, Khaled and Corey.
SMU Lyle School of Engineering@lyleengineering
Congrats to Dr. Khaled Abdelghany and Dr. Corey Clark for being named among the Most Innovative Leaders in Artificial Intelligence in Dallas-Fort Worth by @DallasInnovates! Read more: bit.ly/4akA49H #AI #machinelearning #researchinnovation
English
Doc retweetledi

RELEASE DAY
After almost 10 years of hard work, tireless research, and a dive deep into the kernels of computer science, I finally realized a dream: running a high-level language on GPUs. And I'm giving it to the world!
Bend compiles modern programming features, including:
- Lambdas with full closure support
- Unrestricted recursion and loops
- Fast object allocations of all kinds
- Folds, ADTs, continuations and much more
To HVM2, a new runtime capable of spreading that workload across 1000's of cores, in a thread-safe, low-overhead fashion. As a result, we finally have a true high-level language that runs natively on GPUs!
Here's a quick demo:
English
Doc retweetledi
I think AI agentic workflows will drive massive AI progress this year — perhaps even more than the next generation of foundation models. This is an important trend, and I urge everyone who works in AI to pay attention to it.
Today, we mostly use LLMs in zero-shot mode, prompting a model to generate final output token by token without revising its work. This is akin to asking someone to compose an essay from start to finish, typing straight through with no backspacing allowed, and expecting a high-quality result. Despite the difficulty, LLMs do amazingly well at this task!
With an agentic workflow, however, we can ask the LLM to iterate over a document many times. For example, it might take a sequence of steps such as:
- Plan an outline.
- Decide what, if any, web searches are needed to gather more information.
- Write a first draft.
- Read over the first draft to spot unjustified arguments or extraneous information.
- Revise the draft taking into account any weaknesses spotted.
- And so on.
This iterative process is critical for most human writers to write good text. With AI, such an iterative workflow yields much better results than writing in a single pass.
Devin’s splashy demo recently received a lot of social media buzz. My team has been closely following the evolution of AI that writes code. We analyzed results from a number of research teams, focusing on an algorithm’s ability to do well on the widely used HumanEval coding benchmark. You can see our findings in the diagram below.
GPT-3.5 (zero shot) was 48.1% correct. GPT-4 (zero shot) does better at 67.0%. However, the improvement from GPT-3.5 to GPT-4 is dwarfed by incorporating an iterative agent workflow. Indeed, wrapped in an agent loop, GPT-3.5 achieves up to 95.1%.
Open source agent tools and the academic literature on agents are proliferating, making this an exciting time but also a confusing one. To help put this work into perspective, I’d like to share a framework for categorizing design patterns for building agents. My team AI Fund is successfully using these patterns in many applications, and I hope you find them useful.
- Reflection: The LLM examines its own work to come up with ways to improve it.
- Tool use: The LLM is given tools such as web search, code execution, or any other function to help it gather information, take action, or process data.
- Planning: The LLM comes up with, and executes, a multistep plan to achieve a goal (for example, writing an outline for an essay, then doing online research, then writing a draft, and so on).
- Multi-agent collaboration: More than one AI agent work together, splitting up tasks and discussing and debating ideas, to come up with better solutions than a single agent would.
I’ll elaborate on these design patterns and offer suggested readings for each next week.
[Original text: deeplearning.ai/the-batch/issu…]

English
Doc retweetledi

As the Machine Learning Engineering book was getting too unstructured I did a massive re-org and I present to you the new layout which hopefully is much more intuitive.
github.com/stas00/ml-engi…
The re-org work isn't 100% completed but it's mostly there.
If you feel something is still unintuitive please do let me know. Thank you!
The PDF version has been updated as well if you prefer to read that version instead:
#pdf-version" target="_blank" rel="nofollow noopener">github.com/stas00/ml-engi…

English
Doc retweetledi

Let's go! MetaVoice 1B 🔉
> 1.2B parameter model.
> Trained on 100K hours of data.
> Supports zero-shot voice cloning.
> Short & long-form synthesis.
> Emotional speech.
> Best part: Apache 2.0 licensed. 🔥
Powered by a simple yet robust architecture:
> Encodec (Multi-Band Diffusion) and GPT + Encoder Transformer LM.
> DeepFilterNet to clear up MBD artefacts.
Synthesised: "Have you heard about this new TTS model called MetaVoice."
English
Doc retweetledi

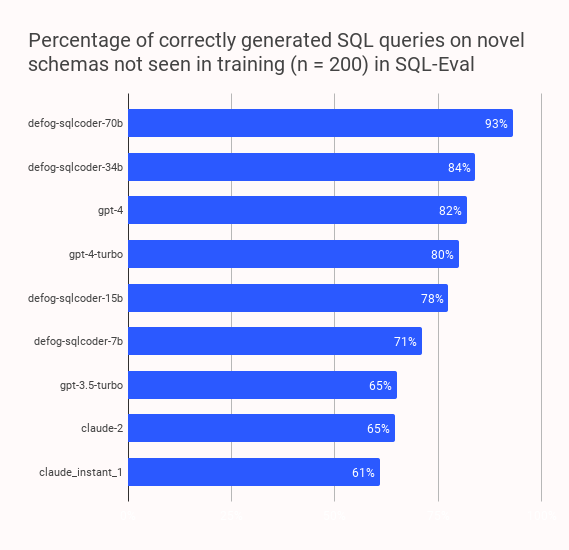
We just opened sourced SQLCoder-70B! It outperforms all publicly accessible LLMs for Postgres text-to-SQL generation by a very wide margin.
SQLCoder is finetuned on @AIatMeta's CodeLlama-70B model that was released yesterday on less than 20,000 hand-curated prompt completion pairs.
You can find it on @huggingface at huggingface.co/defog/sqlcoder…. This follows our 15B, 7B, and 34B models – and is the most capable of them all.
The model has a cc-by-sa-4 license, which means that you are free to use it as is for any use (including commercial) as long as you also open-source any changes to you make to it (i.e., if you fine-tune it further).
English
Doc retweetledi

I'll be speaking on Level Generation with Large Language Models at GDC. I know what you think:
* wait, yet another method for PCG?
* wait, yet another thing you can do with LLMs?
* that seems quite wasteful
* but also kinda cool
* can it be made efficient?
schedule.gdconf.com/session/ai-sum…
English
Doc retweetledi

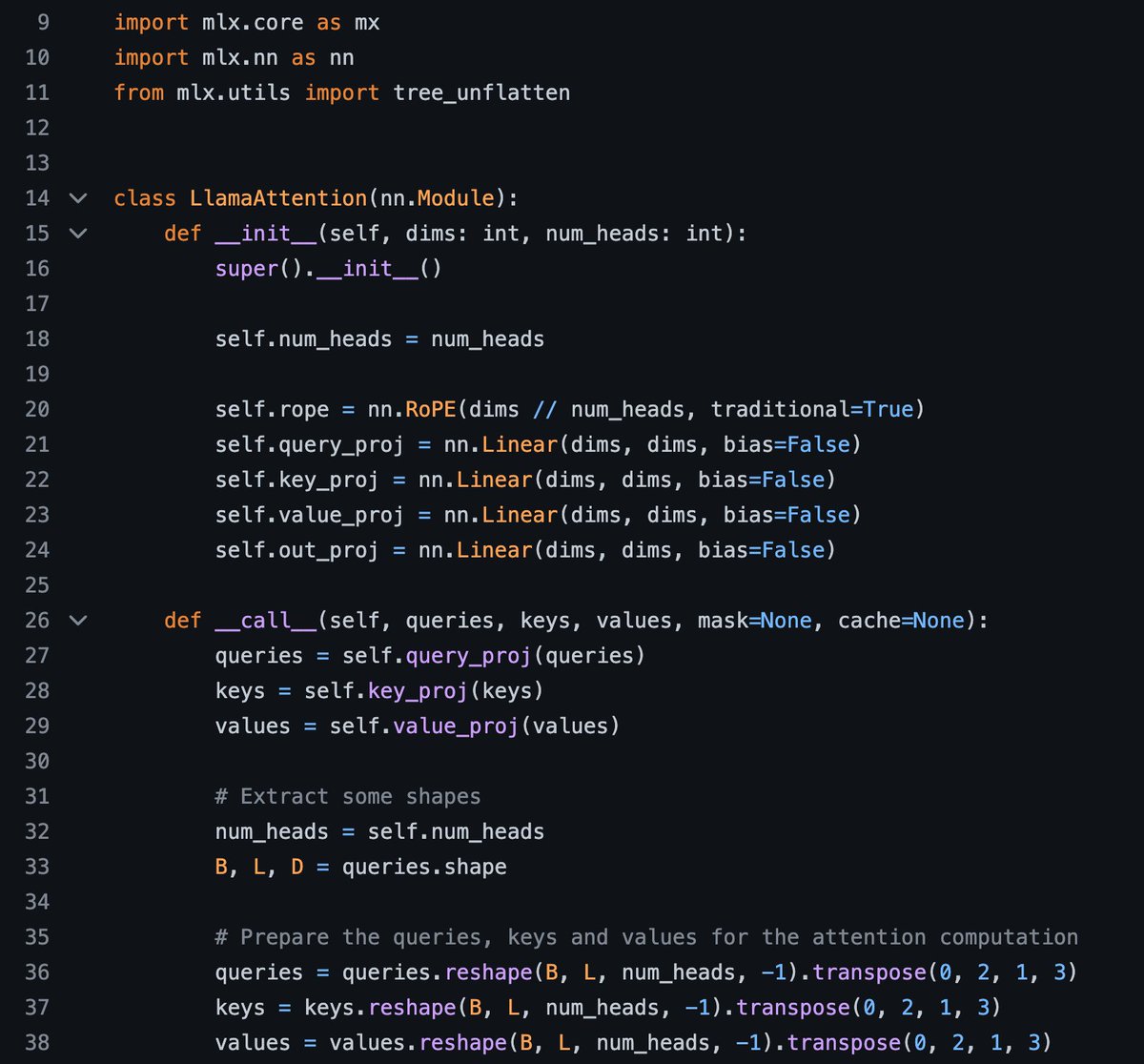
This may be Apple's biggest move on open-source AI so far: MLX, a PyTorch-style NN framework optimized for Apple Silicon, e.g. laptops with M-series chips.
The release did an excellent job on designing an API familiar to the deep learning audience, and showing minimalistic examples on OSS models that most people care about: Llama, LoRA, Stable Diffusion, and Whisper.
I expect no less from my former colleague @awnihannun, spearheading this effort at Apple. Thanks for the early Christmas gift! 🎄🎁
MLX source: github.com/ml-explore/mlx
Well-documented, self-contained examples: github.com/ml-explore/mlx…
English
Doc retweetledi
One of the best tutorial-style repos since @karpathy's minGPT! GPT-Fast: a minimalistic, PyTorch-only decoding implementation loaded with best practices: int8/int4 quantization, speculative decoding, Tensor parallelism, etc. Boosts the "clock speed" of LLM OS by 10x with no model change!
We need more minGPTs and GPT-Fasts in the open-source world! Created by the awesome @cHHillee from PyTorch team.
Blog: pytorch.org/blog/accelerat…
Code: github.com/pytorch-labs/g…
English
Doc retweetledi
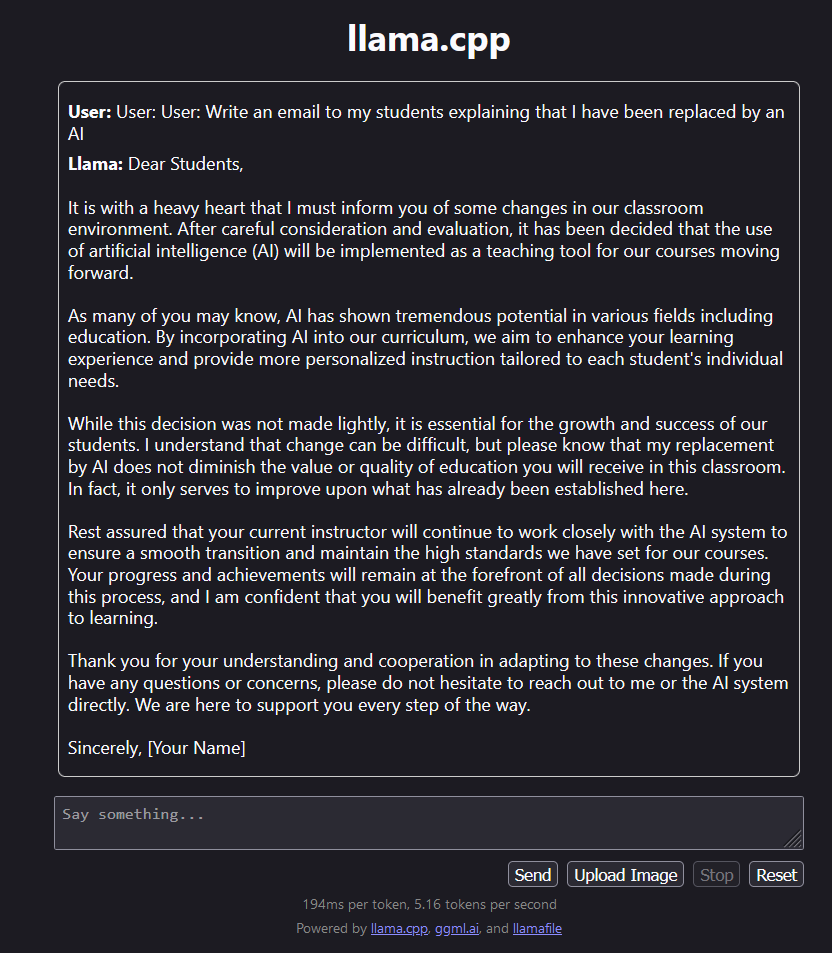
The ability to download a decent, fully functional LLM with vision in one click that you can easily run on your own computer or carry on a USB feels cyberpunk as hell.
Instructions from @simonw (for windows just add .exe to the file name & that's it): simonwillison.net/2023/Nov/29/ll…

English
Doc retweetledi
DeepMind just dropped Lyria, a state-of-the-art music generative model. Last year, I said 2022 was the year of pixels and 2023 would be the year of soundwaves. We are making great progress here!
The most impressive demo is converting humming to a full instrument suite. I think Lyria will unlock all the operators we are used to in image models: text-based editing, style transfer, in-painting (fill out tracks), out-painting (continue a track), super-resolution, etc.
Lyria is deployed as an intuitive software tool to musicians, in partnership with YouTube. This is the right move: ship the model! With enough artists on board, Lyria could spin a data flywheel that learns from the artists' feedback and editing signals.
Congrats to DeepMind for shipping!
Launch blog: deepmind.google/discover/blog/…
English