Seba
361 posts

Seba
@CulStory
TLDR Current proj: Realtime Text-to-Speech on Apple NPU https://t.co/kJWvH9C7TK

Looooooong cat biiiiiiiig model Rooting for @Meituan_LongCat (Chinese DoorDash)






Reading @deepseek_ai 's v4 paper.... absolute hats off. Every problem has a mathematical solution, nothing is left to chance. I have so much respect for them, putting out months or years of efforts entirely for free, in the open for anyone to benefit. Real goats 🫡

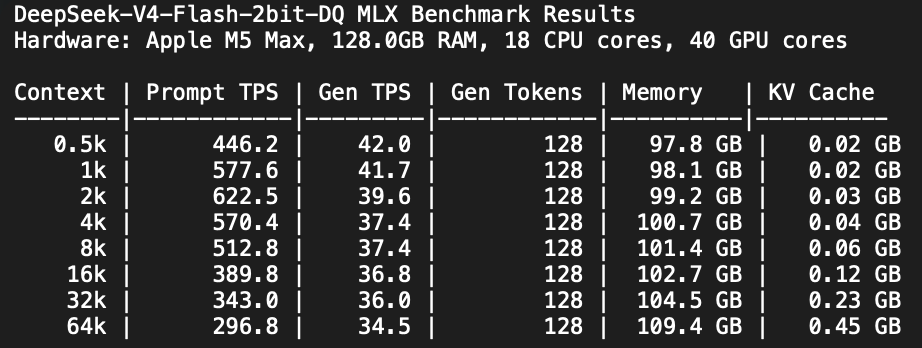
the most important part about v4 flash/pro. you can probably serve 100s of users at >100k context each on a single gpu/node.



Disk usage before and after converting a 900MB CoreML model, hate it so much.
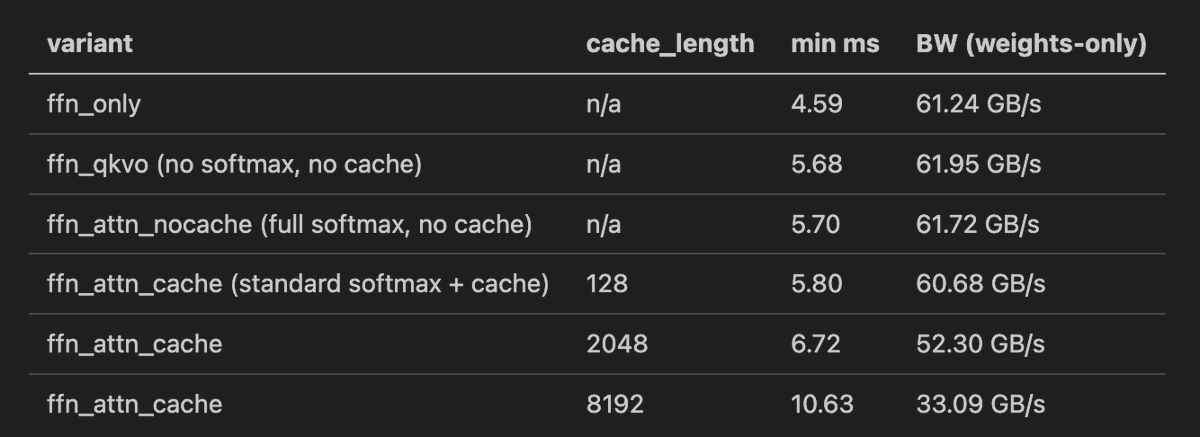








We've been developing a multi-agent system that builds and maintains complex software autonomously. Recently, we partnered with NVIDIA to apply it to optimizing CUDA kernels. In 3 weeks, it delivered a 38% geomean speedup across 235 problems.

Across the reported settings, DDTree achieves higher speedup than vanilla DFlash in all 60 dataset/model/temperature combinations. Peak reported speedup is 8.22x on HumanEval, and peak acceptance length is 10.73 on MATH-500.
🚀 New blog is out: HiSparse — Turbocharging Sparse Attention with Hierarchical Memory! Sparse attention cuts compute costs, but the full KV cache still sits in GPU HBM, making it capacity-bound. HiSparse fixes this. Results: ⚡️ 3× throughput at 256 concurrent requests vs. baseline (32K input, 8K output on 8×H200) 🚀 Up to 5× throughput on long-context scenarios (two H20 PD-disaggregated deployment) Key techniques include: 💾 Proactively offloads inactive KV cache to host memory, freeing GPU HBM for larger batch sizes 🧠 Hot device buffer keeps frequently accessed KV regions on-device to minimize swap-in latency 🔧 Custom CUDA kernel: top-k miss detection + LRU eviction + page table updates in one pass Currently supports DeepSeek Sparse Attention (DSA) models: DeepSeek-V3.2 and GLM-5.1. Thanks to @Zhiqiang_Xie and the team for this great contribution!
If you have multiple AMD gpus that are P2P capable over pcie, you might to look at this patch. Many server boards and prosumer mbs have embedded pcie switches. 🧐

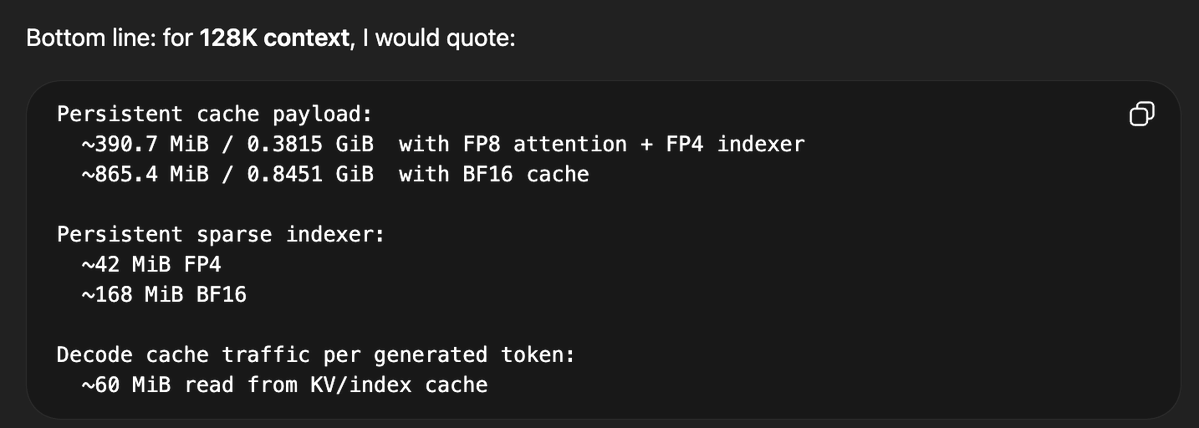
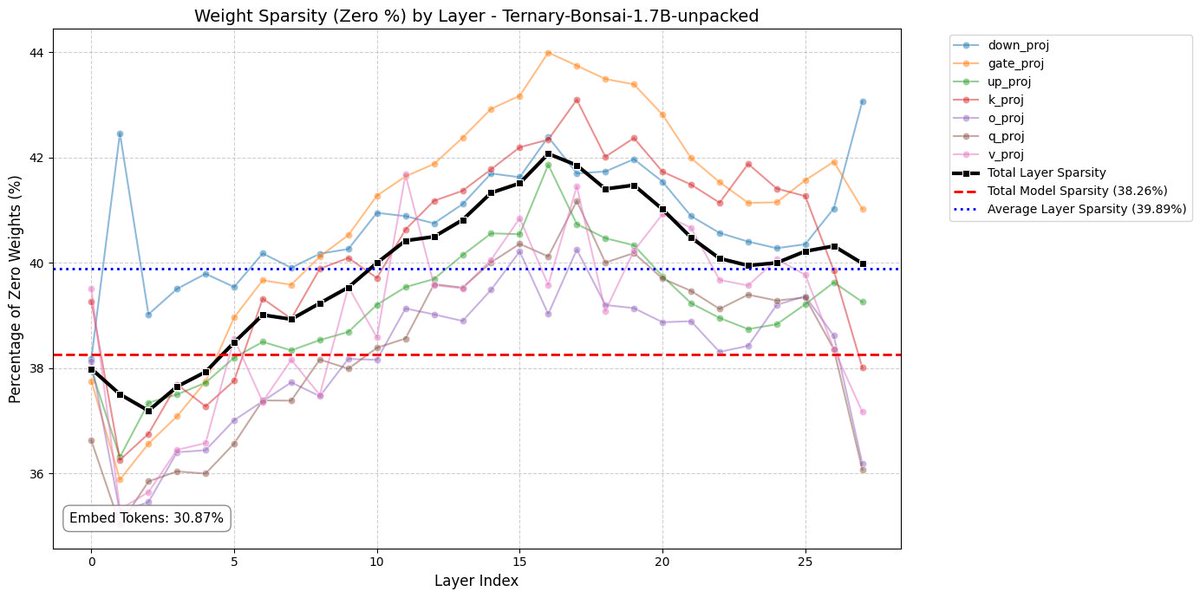
@Alexey_CA @twostraws @jeremyphoward This is what Flash-MoE is trying to address: running in low RAM environments. This runs 26B in a 3GB footprint. Improving iPhone helps with M5Max 128GB and M3U optimizations for me.
State space models are a pain in the ass Implementing virtual KV cache for state space models is pain in the ass Implementing dynamic tree attention for state space models is pain in the ass Implementing speculative decoding for state space models is pain in the ass

