latte
406 posts



200x limit.
How in the world should I use this up 😭
Leon Lin@LexnLin
WHAT, 10x'ed CODEX LIMITS? THANK YOU @OpenAIDevs
English
@StalkergJp @Anaya_sharma876 @shub0414 It's pointless talking to you if you don't listen to me. Read all my messages and I'm sure you'll come to the correct conclusion.
English

@DDevyy77003 @Anaya_sharma876 @shub0414 Linux anti-cheat exists, devs ignore it. It's a game devs' issue and not Linux.
English


@bricktimesyt @anshkapuriya @immasiddx It's gonna increase the usage of the app and gonna make the model feel better through placebo. It's pretty common, you want to use a good looking interface more than a bad looking one, and the product instantly feels better too.
English

@anshkapuriya @immasiddx use what? its just a redesign of the landing screen bruh your experience isnt magically going to be better
English

@StalkergJp @Anaya_sharma876 @shub0414 There’s no "Linux anti-cheat" thing, it’s game devs. But if it breaks Linux users, it becomes a Linux problem. Same with Windows and programming: not the OS itself, just fewer tools because most devs use Mac or Linux.
English
@DDevyy77003 @Anaya_sharma876 @shub0414 Origin is important. It means we have issues with some games that don't support Linux anti-cheat.
English
@StalkergJp @Anaya_sharma876 @shub0414 The OP asked for the biggest Linux issue, it's that it has low compatibility with games, it's not because of linux, it's because of game devs yes, but still that's an issue with Linux distros and in general the OS for now, doesn't matter what's the origin.
English
English
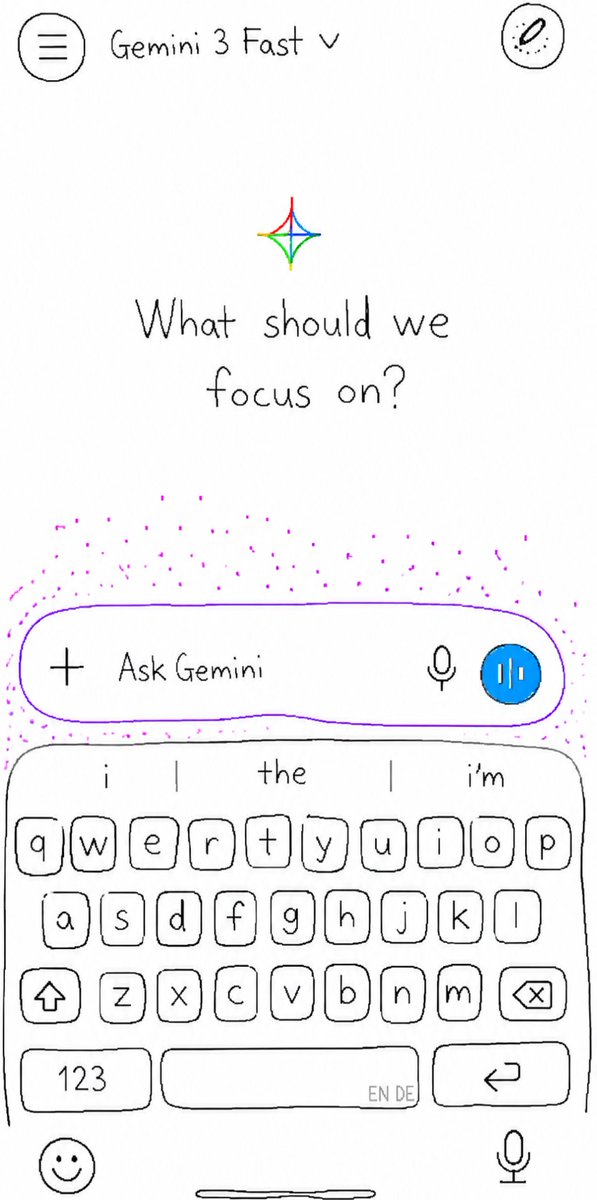
latte retweetledi

GOOGLE 🚨: A new design for Gemini on iOS has been spotted!
Sleeeeeeeeeeeek! 👀
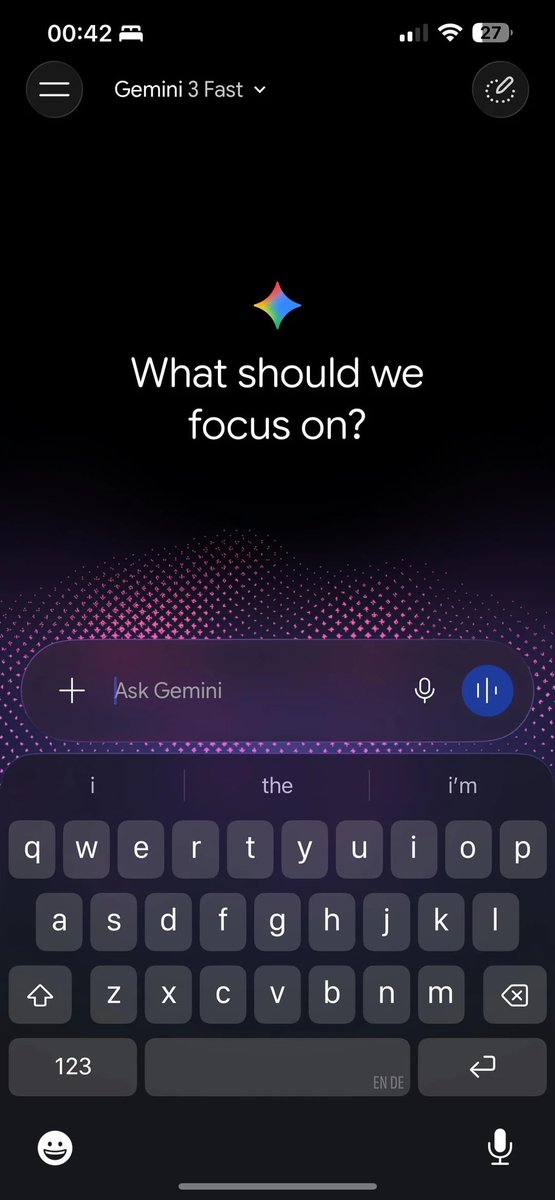
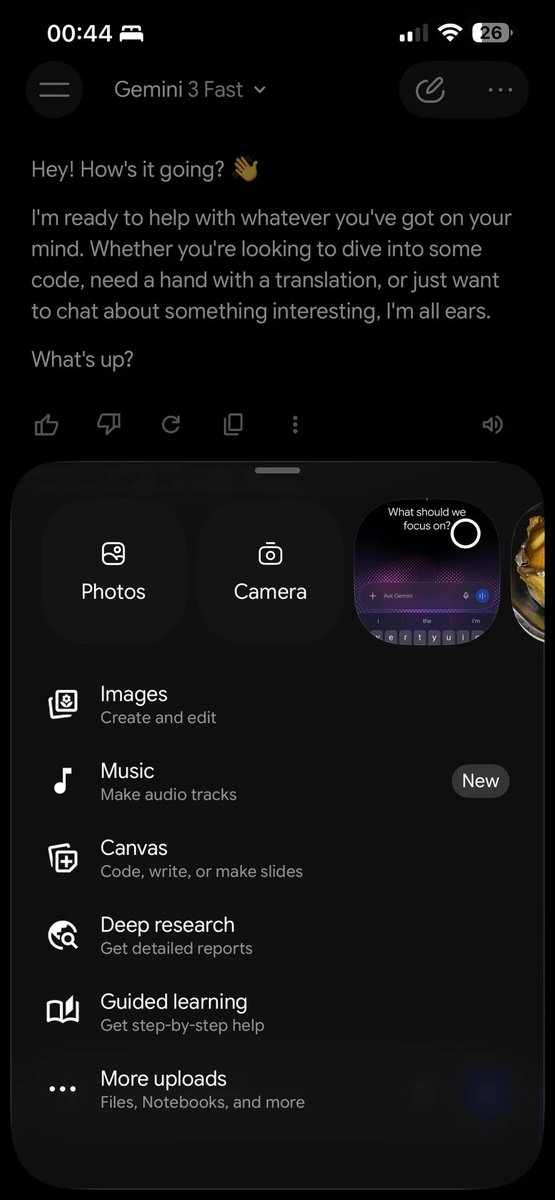
English

@FredWanders single prompt btw (could be pushed further), with reference image (i posted the no reference under the post)

English


@mathhub_vn 4*1/4=4/4, bur 5*1/4=5/4 and since 4/4 != 5/4 the statement is false.
English


@Anaya_sharma876 @shub0414 Fym thank you later, cachyos makes it a bit easier to download games which is still easy on all distros but games with kernel level anti cheats still won't work, and no distro changes that.
English


@RoundtableSpace From this list only Meta Avocado isn't released (if you meant to public then also Mythos). But I think Avocado is Muse Spark. Unless it's something bigger.
English

HERE’S A LIST OF ALL AI MODELS THAT ARE RUMORED TO BE RELEASED IN MAY
> GPT-5.5 (“Spud”)
> Claude Mythos
> DeepSeek-V4 (Pro / Flash)
> Meta “Avocado”
> Meta Muse Spark
> Nemotron 4
> GR00T N2
Which one are you most excited for?
English
latte retweetledi



@CPAutist @AiBattle_ Their architectures are promising (DeepSeek V3 based) but their models... not so much.
English

@DDevyy77003 @AiBattle_ Why would mistral keep releasing models at all who uses them 😂
English



I'm not 100% sure if arena works like that but I think that most people try the models with frontend gen prompts
That's why opus and muse spark are pretty high
But a minority of people test reasoning and more logic focused tasks, that's why gpt isnt even lower
That would be my explanation
Imo there should DEFINITELY be subcategories in coding
Arena.ai@arena
GPT-5.5 by @OpenAI is now live in the Arena, landing across multiple leaderboards. Here’s how it ranks by modality: - Code Arena (agentic web dev): #9, a strong +50pt jump over GPT-5.4 - Document Arena (analysis & long-content reasoning): #6, on par with Sonnet 4.6 - Text Arena: #7, Math #3, Instruction Following: #8 - Expert Arena: #5 - Search Arena: #2 - Vision Arena: #5 Strong, well-rounded performance, especially in Code (+50 pts vs GPT-5.4). Congrats to @OpenAI on the release. Full category breakdowns by modality in the thread.
English
@FrozenTundraSun @basecampbernie @SorinBota_X @Alibaba @Alibaba_Qwen MoE doesn’t make size irrelevant, it’s just sparse scaling. Bigger models still have more capacity for messy prompts and intent gaps. Better tuning can beat them, sure. But size still matters (a lot).
English

@DDevyy77003 @basecampbernie @SorinBota_X @Alibaba @Alibaba_Qwen Bro, that's just not true. Read on how models collapse in unsupervised learning. The size of the model is not about nuance or else MoE wouldn't be working at all, but it does. Not only that, but the size doesn't always get distributed evenly amongst the routing vs genAI layers.
English

Deepseek V4 Flash 284B is just one point better than qwen3.6 27B .. @alibaba @Alibaba_Qwen and a 3090

English
@FrozenTundraSun @basecampbernie @SorinBota_X @Alibaba @Alibaba_Qwen Nuance isn't quality or performance. Larger models simply grasp intent better. You can boost that without scaling up, but size always matters. You can be way more vague with a big model than with a small model, and it'll understand your intent more.
English
@DDevyy77003 @basecampbernie @SorinBota_X @Alibaba @Alibaba_Qwen That's demonstrably not true, even mathematically. When you train your models naively the size doesn't help. More parameters and bigger size of them in the same model class do transfer in more nuance, but to a limited extent. 8FP has negligent loss of quality compared to 16FP.
English