
David Brown
162 posts

We have some interesting new addition to Glasgow’s museum of transport.



English
@jules_arii58 @nikitabier this account is impersonating @babybirdjules - why can’t I find her account in the impersonation report form?
English


@romainsimon @MistralDevs Agreed! I want that Lego le chat so bad 😂
English


@flowersslop GPT-5 was never going to live up to expectations/hype, I think they just had to get that name out the door to settle everyone asking for it.
English

In hindsight, calling it GPT-5 was kinda a bad move. It should’ve just been o4.
The new omnimodal model feels like its gonna be way closer to what people actually expected GPT-5 to be, while GPT-5 itself didn’t earn that big name bc why does GPT-5 have fewer capabilties than 4o
English
English

ARC-AGI-3 scores for GPT-5.4, Gemini 3.1 Pro and Opus 4.6
Gemini 3.1 Pro: 0.37%
GPT-5.4: 0.26%
Opus 4.6: 0.25%
Grok 4.2: 0%

Indonesia
English

Since OpenAI dropped gpt-oss-120b, Mistral has released 4 models that are worse than gpt-pss-120b
Artificial Analysis@ArtificialAnlys
Mistral has released Mistral Small 4, an open weights model with hybrid reasoning and image input, scoring 27 on the Artificial Analysis Intelligence Index @MistralAI's Small 4 is a 119B mixture-of-experts model with 6.5B active parameters per token, supporting both reasoning and non-reasoning modes. In reasoning mode, Mistral Small 4 scores 27 on the Artificial Analysis Intelligence Index, a 12-point improvement from Small 3.2 (15) and now among the most intelligent models Mistral has released, surpassing Mistral Large 3 (23) and matching the proprietary Magistral Medium 1.2 (27). However, it lags open weights peers with similar total parameter counts such as gpt-oss-120B (high, 33), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, 36), and Qwen3.5 122B A10B (Reasoning, 42). Key takeaways: ➤ Reasoning and non-reasoning modes in a single model: Mistral Small 4 supports configurable hybrid reasoning with reasoning and non-reasoning modes, rather than the separate reasoning variants Mistral has released previously with their Magistral models. In reasoning mode, the model scores 27 on the Artificial Analysis Intelligence Index. In non-reasoning mode, the model scores 19, a 4-point improvement from its predecessor Mistral Small 3.2 (15) ➤ More token efficient than peers of similar size: At ~52M output tokens, Mistral Small 4 (Reasoning) uses fewer tokens to run the Artificial Analysis Intelligence Index compared to reasoning models such as gpt-oss-120B (high, ~78M), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, ~110M), and Qwen3.5 122B A10B (Reasoning, ~91M). In non-reasoning mode, the model uses ~4M output tokens ➤ Native support for image input: Mistral Small 4 is a multimodal model, accepting image input as well as text. On our multimodal evaluation, MMMU-Pro, Mistral Small 4 (Reasoning) scores 57%, ahead of Mistral Large 3 (56%) but behind Qwen3.5 122B A10B (Reasoning, 75%). Neither gpt-oss-120B nor NVIDIA Nemotron 3 Super 120B A12B support image input. All models support text output only ➤ Improvement in real-world agentic tasks: Mistral Small 4 scores an Elo of 871 on GDPval-AA, our evaluation based on OpenAI's GDPval dataset that tests models on real-world tasks across 44 occupations and 9 major industries, with models producing deliverables such as documents, spreadsheets, and diagrams in an agentic loop. This is more than double the Elo of Small 3.2 (339) and close to Mistral Large 3 (880), but behind gpt-oss-120B (high, 962), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, 1021), and Qwen3.5 122B A10B (Reasoning, 1130) ➤ Lower hallucination rate than peer models of similar size: Mistral Small 4 scores -30 on AA-Omniscience, our evaluation of knowledge reliability and hallucination, where scores range from -100 to 100 (higher is better) and a negative score indicates more incorrect than correct answers. Mistral Small 4 scores ahead of gpt-oss-120B (high, -50), Qwen3.5 122B A10B (Reasoning, -40), and NVIDIA Nemotron 3 Super 120B A12B (Reasoning, -42) Key model details: ➤ Context window: 256K tokens (up from 128K on Small 3.2) ➤ Pricing: $0.15/$0.6 per 1M input/output tokens ➤ Availability: Mistral first-party API only. At native FP8 precision, Mistral Small 4's 119B parameters require ~119GB to self-host the weights (more than the 80GB of HBM3 memory on a single NVIDIA H100) ➤ Modality: Image and text input with text output only ➤ Licensing: Apache 2.0 license
English

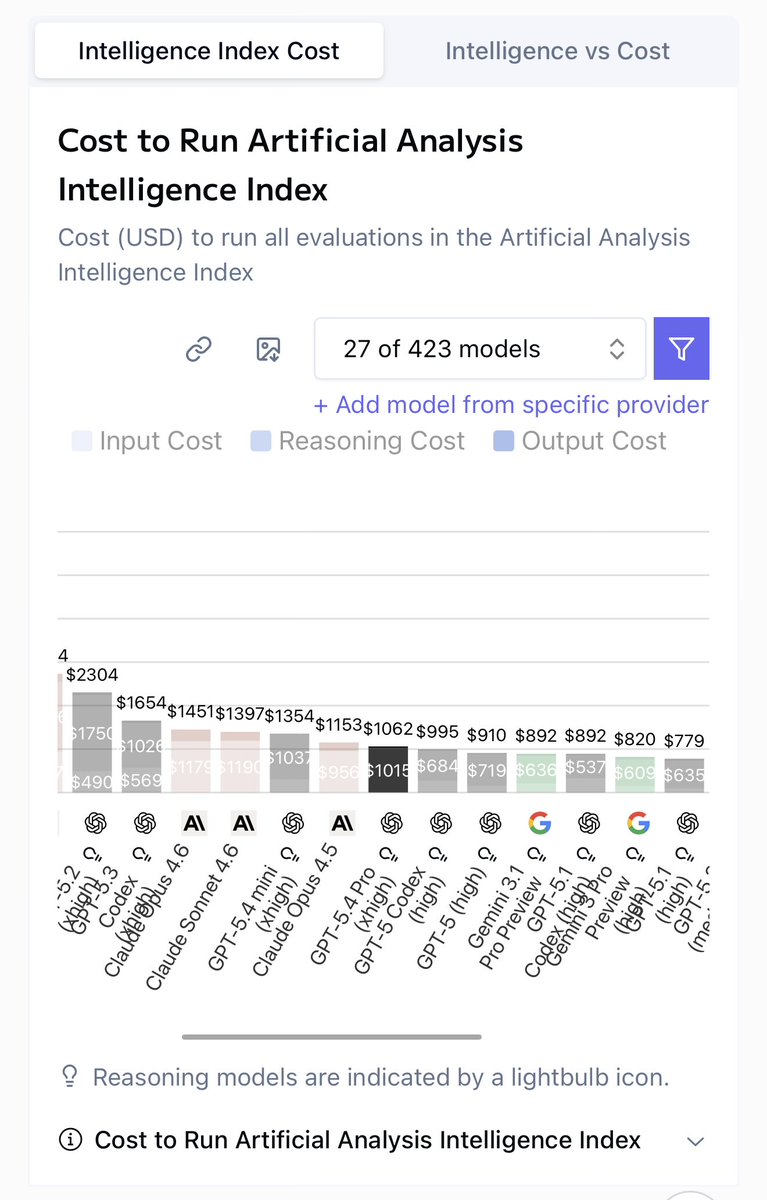
Just spotted some results for GPT-5.4 Pro xhigh have popped up on @ArtificialAnlys
artificialanalysis.ai/models/gpt-5-4…
If these cost/efficiency scores are accurate - wow!

English
@BBCScotlandNews Losing a national asset to save… £10k a year? What on earth is the council thinking.
“Phase out diving and deep-water sessions at the Citadel to focus on higher-demand programmes”
Savings: £20,000 in 2026/27, then £10,000 ongoing.
south-ayrshire.gov.uk/media/17641/Ad…
English

Divers 'devastated' as council cuts condemn club after 62 years bbc.in/4bnHFGI
English
@kimmonismus Which is kinda funny, considering their chips are in none of those devices
English


Tomorrow we will unveil the all new vibe coding experience in @GoogleAIStudio, the team has spent 4 months rebuilding it all from scratch and smoothing out rough edges to help everyone bring their ideas to life.
This is a big step forward, but just the start : )
English
English

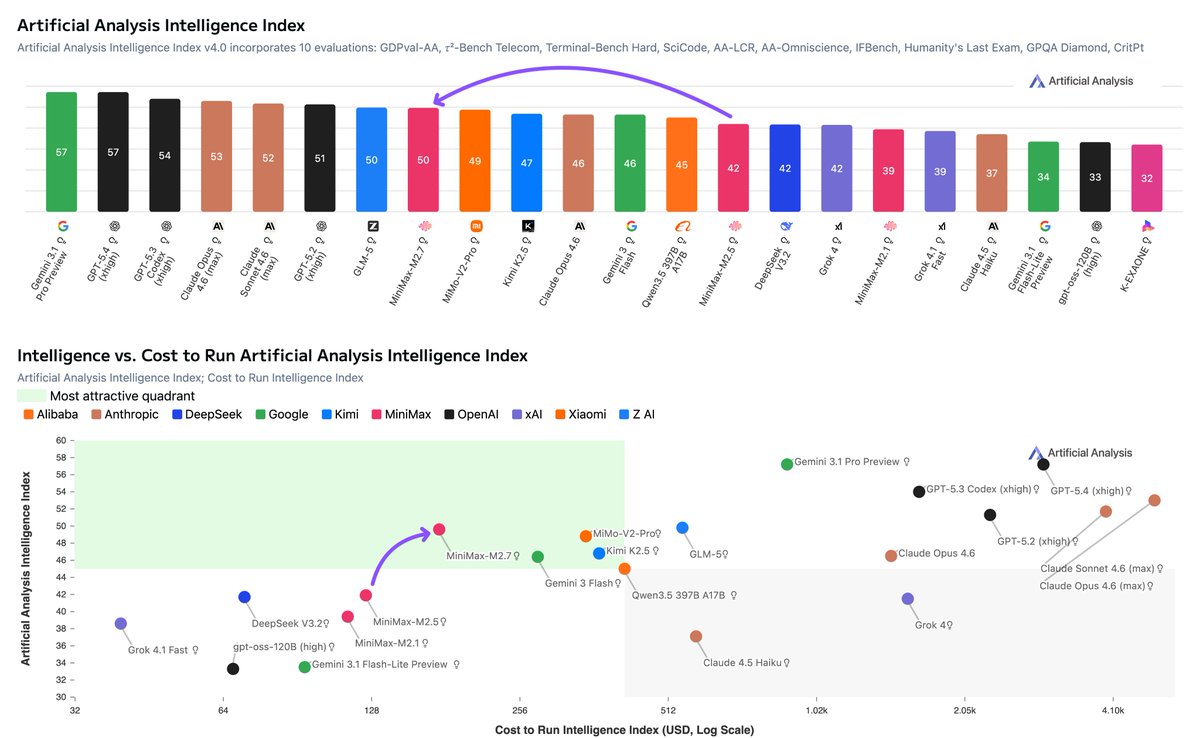
MiniMax has released MiniMax-M2.7, delivering GLM-5-level intelligence for less than one third of the cost
MiniMax-M2.7 from @MiniMax_AI scores 50 on the Artificial Analysis Intelligence Index, an 8-point improvement over MiniMax-M2.5, which was released one month ago. This is driven by stronger performance on real-world agentic tasks and reduced hallucinations. MiniMax-M2.7 is now ahead of MiMo-V2-Pro (Reasoning, 49) and Kimi K2.5 (Reasoning, 47), and equivalent to GLM-5 (Reasoning, 50) while using 20% fewer output tokens and costing less than a third as much to run. MiniMax-M2.7 is a reasoning-only model and maintains the same per-token pricing as MiniMax-M2.5.
Key takeaways:
➤ Strong performance on real-world agentic tasks: MiniMax-M2.7 achieves a GDPval-AA Elo of 1494, a significant improvement from MiniMax-M2.5 (1203) and ahead of MiMo-V2-Pro (Reasoning, 1426), GLM-5 (Reasoning, 1406), and Kimi K2.5 (Reasoning, 1283). It remains behind frontier models such as GPT-5.4 (xhigh, 1667) and Claude Opus 4.6 (Adaptive Reasoning, max effort, 1606)
➤ Reduced hallucinations: MiniMax-M2.7 scores +1 on the AA-Omniscience Index, up from MiniMax-M2.5 (-40). This is competitive with GPT-5.2 (xhigh, -1) and GLM-5 (Reasoning, +2), and well ahead of Kimi K2.5 (Reasoning, -8). The improvement from M2.5 is purely driven by reduced hallucinations, meaning the model is more likely to abstain from answering when it doesn’t know the answer, rather than guessing. M2.7 achieves a hallucination rate of 34%, lower than Claude Sonnet 4.6 (Adaptive Reasoning, max effort, 46%) and Gemini 3.1 Pro Preview (50%).
➤ Gains across most evaluations compared to MiniMax-M2.5: Outside of the GDPval-AA and AA-Omniscience improvements noted above, MiniMax-M2.7 improves in HLE (+9 p.p.), TerminalBench Hard (+5 p.p.), SciCode (+4 p.p.), IFBench (+4 p.p.), GPQA (+3 p.p.), and LCR (+3 p.p.). We saw a notable regression in τ²-Bench (-11 p.p.).
➤ Increased token use: MiniMax-M2.7 used ~87M output tokens to run the Artificial Analysis Intelligence Index, up 55% from MiniMax-M2.5 (~56M). It remains more token-efficient than other models such as GLM-5 (Reasoning, 110M) and Kimi K2.5 (Reasoning, ~89M)
➤ Leading cost efficiency: MiniMax-M2.7 cost $176 to run the Artificial Analysis Intelligence Index, maintaining the same $0.30/$1.20 per 1M input/output pricing as M2.5. This places it on the Pareto frontier of our Intelligence vs. Cost chart. For context, GLM-5 (Reasoning) cost $547 at equivalent intelligence, Kimi K2.5 (Reasoning) cost $371, and Gemini 3 Flash Preview (Reasoning) cost $278
Key model details:
➤ Context window: 200K tokens (equivalent to MiniMax-M2.5).
➤ Pricing: $0.30/$1.20 per 1M input/output tokens (unchanged from MiniMax-M2.5).
➤ Availability: MiniMax first-party API only.
➤ Modality: Text input and output only (no multimodality).
➤ Licensing: MiniMax has not announced whether MiniMax-M2.7 will be open weights. MiniMax-M2.5 is available under the MIT license.
English

We are so excited to officially launch 3 new additions to the Aqara ecosystem today 👀
Here’s what’s new:
• Doorbell Camera G400 - see your entire doorway from face to floor with a 165° vertical view in crisp 2K. Powered 24/7 via wired or PoE (no batteries, no downtime), with local AI detection for people, motion, and custom zones—so you only get alerts that actually matter. Plus invisible night vision, two-way audio, and seamless integration with Apple Home, Alexa, Google Home, and SmartThings.
• Camera Hub G350 - our most advanced camera yet. A dual-lens system combining 4K ultra-wide + 2.5K telephoto with smooth 9× zoom, AI-powered tracking to keep people and pets in frame, and full 360° pan-tilt coverage. It also doubles as a Matter Controller + Zigbee hub, so it’s not just a camera—it’s a control center for your smart home.
• Touchscreen Switch S100 - a next-gen smart switch with a built-in touchscreen for controlling scenes, devices, and automations in one place. Supports Matter, Thread, Wi-Fi, and Bluetooth, includes energy monitoring, and even features presence detection for smarter, hands-free automations. All designed to work together—and with the platforms you already use.
Available now on Amazon, our website, and authorized retailers globally.
Which one are you adding first? #Aqara #SmartHome #Matter #HomeAutomation #TechLaunch



English


🚀Announcing a strategic partnership with NVIDIA to co-develop frontier open-source AI models, combining Mistral AI’s frontier model architecture and full-stack AI offering with NVIDIA’s leading compute infrastructure and development tools.

English

@mark_k @xai @ArtificialAnlys Results have started to appear on @ArtificialAnlys, some of the results are quite impressive - lowest hallucination score on the AA-Omniscience bench.
English

@DaBrown95 @xai @ArtificialAnlys Yep, me too. Important to keep in mind that this is just the small model.
English
Grok 4.20 (beta) is now available on the @xai API.
It comes in two variants: multi-agent and normal.
Context window: 2M tokens
Pricing per 1M tokens: $2 input / $6 output
Happy testing 🫡

English