Dan Roth retweetledi

Social Impact Award:
"AccessEval: Benchmarking Disability Bias in Large Language Models"
by Srikant Panda, Amit Agarwal, and Hitesh Laxmichand Patel
aclanthology.org/2025.emnlp-mai…
10/n
English
Dan Roth
46 posts

@DanRothNLP
Chief AI Scientist, Oracle, and the Eduardo D. Glandt Distinguished Professor, CIS, University of Pennsylvania. Former VP/Distinguished Scientist, AWS AI Labs.



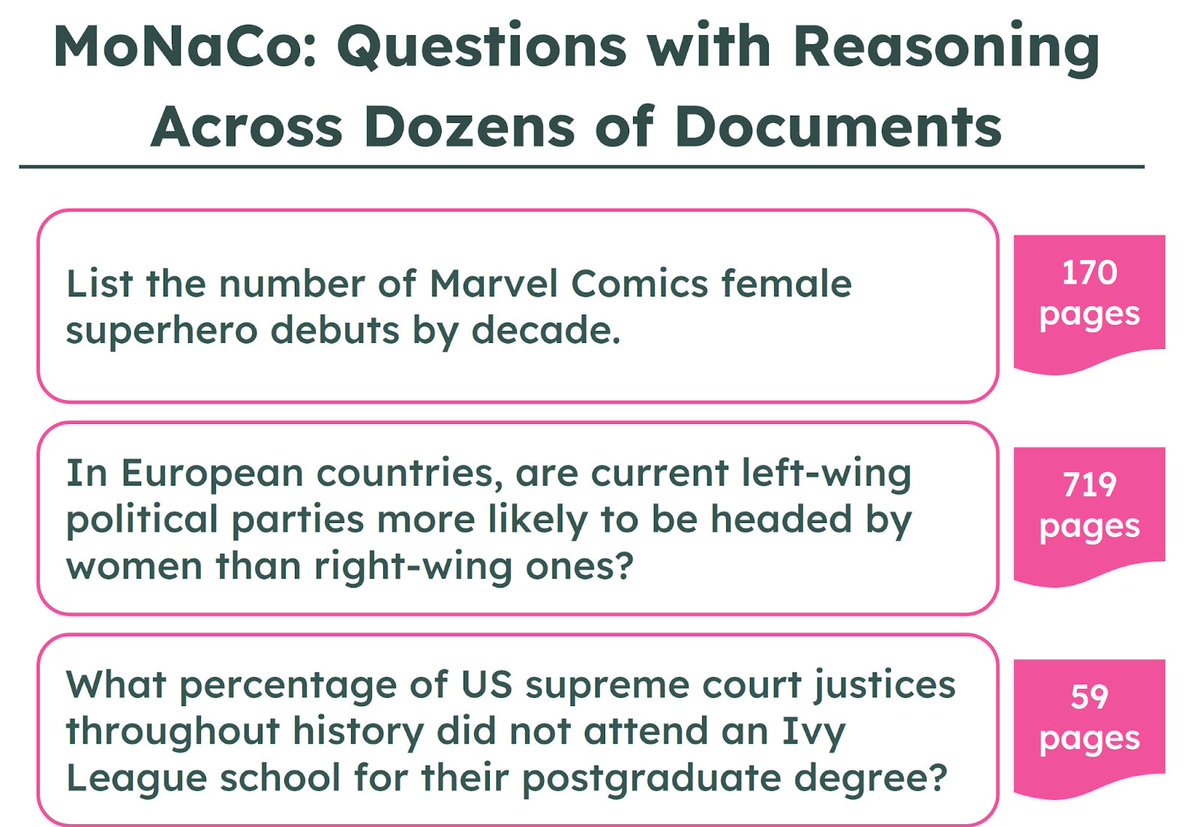
LLMs power research, decision‑making, and exploration—but most benchmarks don’t test how well they stitch together evidence across dozens (or hundreds) of sources. Meet MoNaCo, our new eval for question-answering cross‑source reasoning. 👇


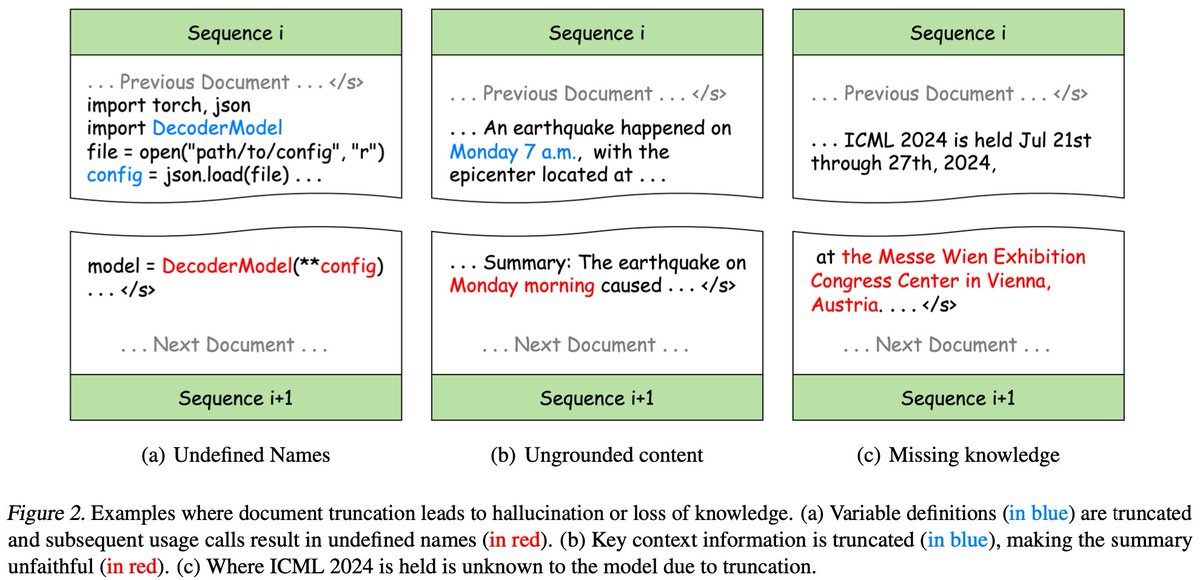
Humans draw to facilitate reasoning and communication. Why not let LLMs do so? 🚀We introduce✏️Sketchpad, which gives multimodal LLMs a sketchpad to draw and facilitate reasoning! arxiv.org/abs/2406.09403 Sketchpad gives GPT-4o great boosts on many vision and math tasks 📈 The video shows how GPT-4o with Sketchpad reasons with interleaved visual and textual steps. For more, visit our project page: visualsketchpad.github.io 📌 For math tasks, ✏️Sketchpad allows LLMs to draw auxiliary lines on geometry diagrams, plotting functions, graphs, and even games. GPT-4o does math better when it can sketch! (+12.7% acc on average) 📌 For computer vision tasks, ✏️Sketchpad allows LLMs to sketch with vision specialists (e.g., GroundingDINO draws bounding boxes, SegmentAnything draws masks). Sketchpad substantially improves GPT-4o's vision abilities. GPT-4o + Sketchpad compared with prior SOTAs: 1️⃣ V*Bench: 75.4% -> 80.3% 2️⃣ BLINK correspondence: 42.4% -> 80.8% 3️⃣ BLINK relative depth: 67.7% -> 83.9% 4️⃣ BLINK spatial relation: 76.2% -> 81.1% ... See more interesting examples in the thread!







BLINK Multimodal Large Language Models Can See but Not Perceive We introduce Blink, a new benchmark for multimodal language models (LLMs) that focuses on core visual perception abilities not found in other evaluations. Most of the Blink tasks can be solved by humans