Daniel Shao retweetledi

AbRank: A Benchmark Dataset and Metric-Learning Framework for Antibody–Antigen Affinity Ranking
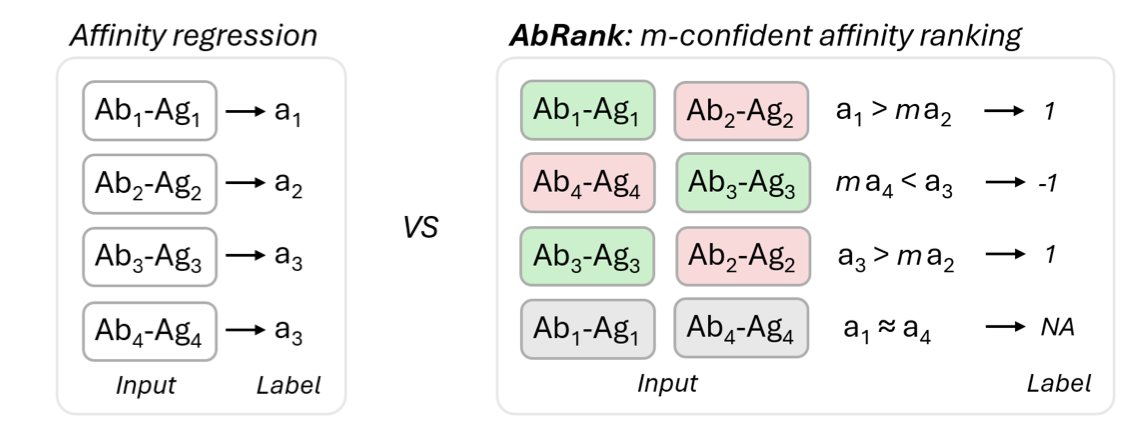
1.AbRank introduces a large-scale benchmark for antibody–antigen (Ab–Ag) affinity prediction, reframing the task as pairwise ranking rather than regression. This design improves generalization and robustness by focusing on relative binding preferences instead of noisy absolute values.
2.The dataset comprises over 380,000 Ab–Ag binding measurements aggregated from nine public sources. It includes highly diverse antibodies and antigens across multiple experimental conditions and affinity metrics (Kd, IC50, escape fractions).
3.AbRank introduces "m-confident ranking" by training only on pairs with at least an m-fold difference in affinity. This filters out ambiguous comparisons and emphasizes biologically meaningful distinctions.
4.Three standard train-test splits are provided to assess generalization: (i) Balanced, (ii) Hard Ab (novel antibodies), and (iii) Hard Ag (novel antigens). These splits test performance under increasing distribution shifts.
5.Two benchmarking scenarios are supported: the Unrelated Complex Benchmark (diverse Ab–Ag pairs) and the Local Perturbation Benchmark (closely related variants). This dual setup evaluates both broad generalization and fine-grained affinity shifts (e.g., from mutations).
6.Structures for all antibodies and antigens were predicted using efficient models (IgFold, Boltz-1), enabling scalable structure-aware learning without requiring known complex structures.
7.The authors propose WALLE-Affinity, a graph-based method combining pretrained embeddings (AntiBERTy for Abs, ESM-2 for Ags) with structural graphs to predict pairwise affinity rankings.
8.WALLE-Affinity trained with ranking loss consistently outperforms regression-based variants and other baselines (ANTIPASTI, GearBind, PBEE, FoldX), especially under hard generalization settings.
9.The model performs inference using only individual Ab and Ag structures, avoiding complex structure prediction while remaining fast (~10 sec/complex) and accurate.
10.Ranking-based supervision consistently yields better generalization than regression, particularly for unseen antigen scenarios. This supports the hypothesis that pairwise comparison is more robust to noise and label uncertainty.
11.Despite its scalability and robustness, the model’s performance declines on local perturbation tasks, reflecting the challenge of predicting subtle changes from minor sequence edits.
12.AbRank offers a unified platform for evaluating Ab–Ag affinity models under realistic and challenging scenarios. It is designed to catalyze progress in therapeutic antibody design, affinity maturation, and immune escape prediction.
💻Code: github.com/biochunan/AbRa…
📜Paper: arxiv.org/abs/2506.17857…
#AntibodyDesign #ProteinInteraction #MachineLearning #Bioinformatics #GraphNeuralNetworks #Ranking #Benchmark #ComputationalBiology
English