
Justin Dao
662 posts


@davidbnb68 Ông Tuấn này hình như trước cũng chỉnh ảnh lụm to airdrop zk, nhưng vẫn để lộ đuôi ví bị cộng đồng check ra là fake sau lên bài xin lỗi thì phải =))
Tiếng Việt

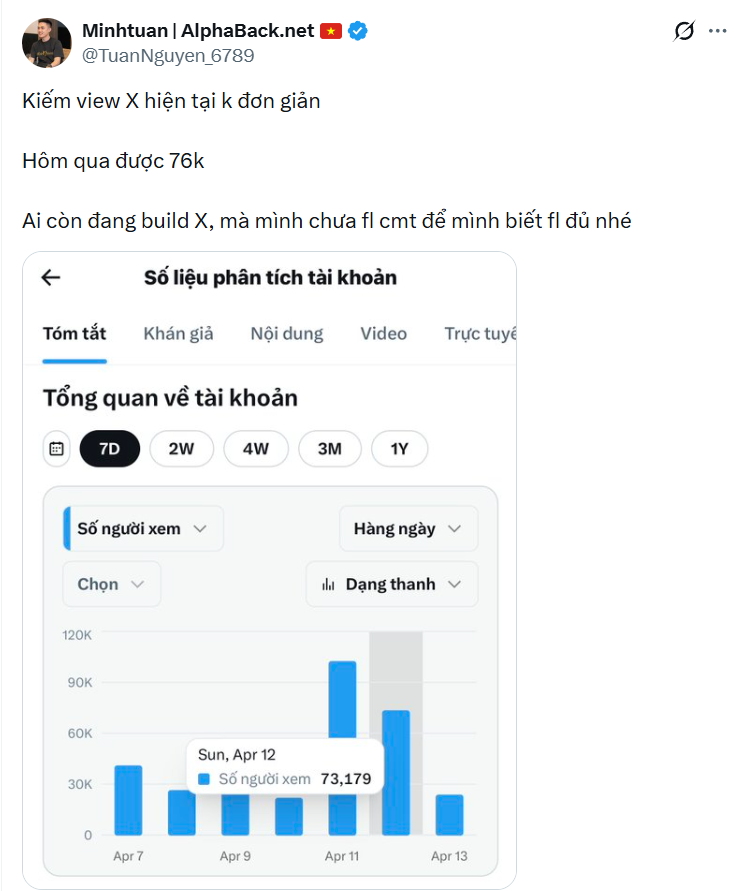
⭐Khứa Tuấn AlphaBack này cứ mỗi độ sau kỳ Pay X là lần nào cũng có kiểu câu Follow Câu view để mọi người tương tác, nhưng thực ra hắn đâu có back đâu, hoặc có back cũng chỉ vài người rồi sau đó lặng lẽ unfollow người ta
- Cứ nhìn vào con số hắn Follow người ta là biết, chỉ có giảm dần chứ làm gì có tăng, trông mặt mũi cũng sáng sủa đó mà kiếm tiền bẩn hoài vậy em trai
- Hắn chuyên có kiểu câu view để mọi người vào tương tác cho hắn lần nào chẳng thế... anh em nào Build X từ giai đoạn 2023 thì cũng biết bộ mặt của khứa này
- Anh em Build X vẫn chưa quên cái vụ bán buff view đâu...
- Bỏ đi mà làm người em ạ, lên video thì cứ nói như thánh, mà kiếm tiền bẩn suốt thế này... anh em chia sẻ mạnh để mọi người biết bộ mặt của khứa này nào
Tiếng Việt


Tiếng Việt

Tiếp tục bào point 2 dự án @grvt_io & @trdEverything!
1/ $GRVT tháng 6 TGE
- Farm được thêm tí Point nào thì farm
- Giá Point tầm ~35u/point chi phí farm tool tầm 7-10u (nếu tính FDV tge tầm 500-600M)
2/ Everything -> Này kèo Perp mới farm trên Tele
- Farm point đang dễ, điểm danh mỗi ngày nhận được vài u token $E.
- Bẩy x1000 nên cày vol vốn 5-10u cày vẫn ổn.
📍Ae Farm perp thì join cày nhé!
- GRVT oin tại đây: grvt.io/?ref=refund (link hoàn 100% phí giao dịch)
- Everything: t.me/EverythingTrad…

KT@KT_BTC
Sáng nay ae kể tên 1 tá dự án scem thì nên để ý tiền đang để trên các sàn nhé! Binance đang khoá rút tài khoản users chưa rõ lý do. Tầm này đúng là đoạn nhạy cảm, tiền để bất kỳ sàn nào cũng có rủi ro mất hết. Mình tháng trade vài lệnh rồi rút về ví + bank chứ ko để ở sàn quá nhiều. Crypto là nơi mà đâu cũng có thể là rủi ro cả. Ảnh ở group Trade mõm.
Tiếng Việt



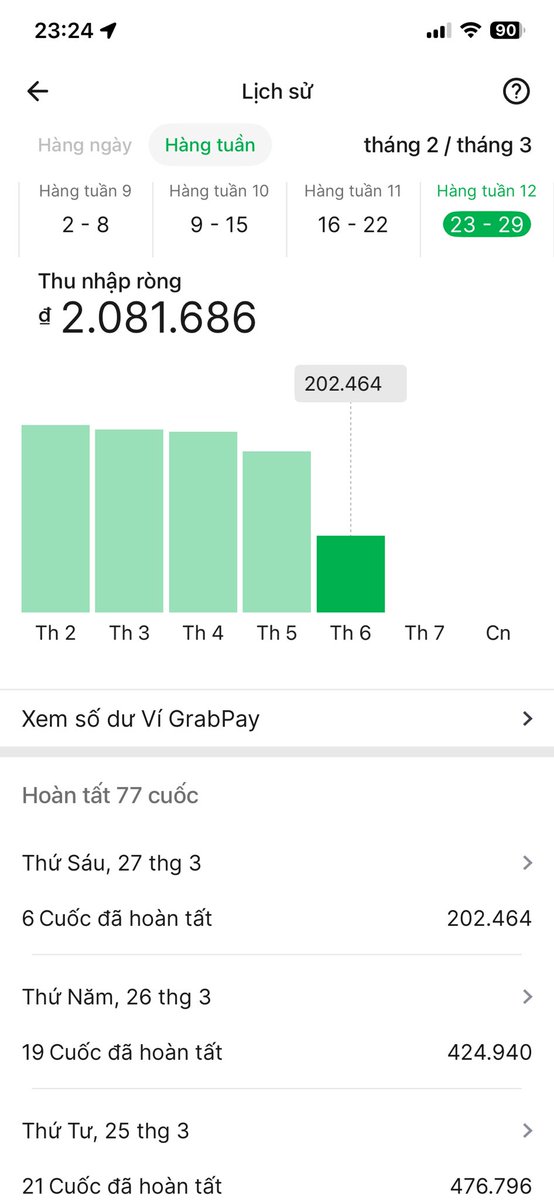
@nguyen0xhieu Mình cũng rời thị trường với một khoản nợ lớn. Giờ cũng đang chạy grab. Trung bình 1 tuần được khoảng 3tr gì đó, ngày ra đường khoảng 10 tiếng, tính cả giờ nghỉ ngơi. Nói chung là lấy ngắn nuôi dài, cố lên bác ơi.
Tiếng Việt

Crypto là công việc đầu tiên mà em làm
Em năm nay 31 chủi, 2009-2022 em phụ gia đình quản lý xưởng may ở SG, từ sau COVID thì tình hình buôn bán chậm đi tới 2022 là dẹp tiệm.
Trong 2022 em có tìm hiểu về crypto và bỏ nhiều thời gian ra học hành tìm tòi phân tích nên 2023 em ra Hà Nội có người mướn về làm mảng hold spot. Lương cứng 300$/tháng + cầm tài khoản 50K$ đánh, lãi em cắn line lỗ người ta chịu. Em làm ổn tới mức 2024 người ta định nâng quỹ em cầm lên 500K$.
Làm ra tiền ắt chảnh. 2024 em nghỉ làm mướn về tự lấy vốn của mình chơi, suốt 2024 em DCA altcoin (hi vọng đổi đời). Em lỡ mồm than là ít vốn làm quá thế là vợ em vay nửa tỉ đưa thêm cho làm. 1 tỉ rưỡi cả vốn em có cả nợ em mang đập vào altcoin. 2025 em đứt, chia 5 rồi chia 10, tới giờ là chia 20 rồi.
Tháng 02/2025 cùng khổ em tìm đến airdrop, em kiếm được 20K nhưng chỉ giữ được 12K (được airdrop nhưng hold mất mẹ 8K), 6K đã trả nợ còn 6K ăn xài nuôi vợ con.
Coi như full-time từ 2023, vậy mà hiện tại em không thấy đường sống dự định tắt máy đi chạy grab.

Solo Top@solotop999
Tại sao bạn vẫn còn ở lại thị trường này? 🥹
Tiếng Việt


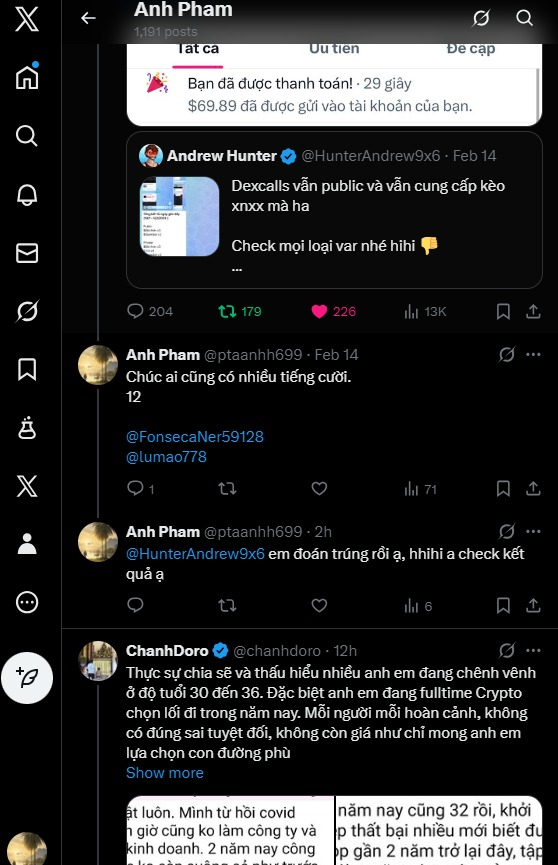
phốt KOL chuyên Scam GA @HunterAndrew9x6
Ngày 14/2 đợt PAY của a musk, KOL này đã lên bài GA hết số tiền đợt PAY cho ai đoán đúng và nhanh nhất KQSX ngày 6/1 ( âm lịch) bài viết hiện giờ đã bị xóa..em xin để hình ảnh và link tweet của em dưới cmt
Tiếng Việt
@davidz9 @Gradient_HQ ./Echo-2: more chances to fail, learn, and iterate.
English



Great conversation with @supercyclepod.
Building Gradient has been a relentless process, but the real inflection point is ahead. Intelligence belongs to everyone, and we intend to make that a reality.
Watch it in full:
Supercycle@supercyclepod
AI should be a public good, not something gatekept by a handful of megacorps We had Eric Yang, co-founder of Gradient Network, on the pod this week to talk through exactly that. Gradient's "Open Intelligence Stack" includes: i) Parallax for distributed model serving ii) Echo for decentralized reinforcement learning The whole thesis is that anyone should be able to run large models on consumer hardware (yes, including your Mac Minis + OpenClaws) Eric breaks down their $10M seed round led by Pantera, Multicoin, and HSG; where he sees the industry heading; and why post-training is going to be the dominant force in enterprise. Timestamps: 00:00 Intro 01:15 AI market is booming 02:29 Local compute is a hot topic 03:02 Parallax Inference Engine 04:34 Intelligence as a public good 05:46 AI models will become a commodity 07:32 Bottlenecks in AI models accessibility 09:34 Smaller AI models are catching up 11:01 How Gradient's Infrastructure Enables Model Development 12:15 Model post-training 14:24 How does reinforcement learning work? 17:35 AI going rogue 19:20 Gradient's token 23:02 AI entrepreneurs that Eric admires 26:11 Use cases on chain for AI 31:34 The trade-offs of coming to crypto 35:09 How low-spec GPUs will work on Gradient Ecosystem 38:08 Post-training will be the dominating force for enterprise 38:43 Open source models are way cheaper 41:39 Eric's founding story 49:07 Empowering researchers globally 53:37 Why did Multicoin Capital and Pantera Capital invested in Gradient 55:08 One-click deploy agent 58:16 Gradient in 3 years
English
Justin Dao@DaongPP
Most people don’t realize how broken real-world AI inference still is. Latency spikes, fragmented data sources, and siloed compute make “real-time intelligence” feel more like a buzzword than reality. Whether it’s agents reacting to live markets, autonomous robotics, or real-time copilots — the bottleneck is always the same: inference isn’t built for a dynamic world. That’s exactly the gap Gradient is trying to solve with Parallax, a world inference engine. Instead of treating inference like a static API call, Parallax is designed to model the world as a constantly shifting state. It pulls signals from distributed sources, processes them across decentralized compute, and delivers context-aware intelligence that evolves in real time. In practice, this matters more than people think. Today, traders rely on fragmented dashboards, AI agents hallucinate due to stale context, and real-time apps break under scale. A system like Parallax reframes inference as a living layer closer to how humans reason: continuously updating, contextual, and adaptive. If Echo is about scaling how models learn, then Parallax is about scaling how models understand the world. And in a future where AI agents operate autonomously across finance, robotics, and the open internet, the real edge won’t just be better models it’ll be better inference layers. @Gradient_HQ isn’t just building models. They’re rebuilding the intelligence stack.
QME

Justin Dao@DaongPP
@pewdiepie recent experiment training his own AI to compete with frontier models was entertaining, but it also exposed a hard truth: building powerful AI locally is still painful. Overheating GPUs, unstable rigs, massive electricity costs it showed how fragile and inaccessible AI training still is when everything depends on a single machine. This is exactly the problem @Gradient_HQ is trying to solve with ./Echo ./Echo isn’t just about “decentralized compute” in a generic sense it’s designed specifically for distributed reinforcement learning. Instead of training agents on one stressed local setup, ./Echo distributes training across a network of nodes, allowing agents to learn through coordinated feedback loops. The result isn’t just more compute, but more resilient and scalable learning. What makes this important is that reinforcement learning is naturally iterative and feedback-driven. ./Echo turns that into a network-native process: multiple contributors, shared training environments, and distributed optimization. So instead of one person pushing hardware to the limit, you get collaborative intelligence evolving across a global network. A 30B model training run on Echo-2 costs around $425 and takes ~9.5 hours. Same budget, 10× more chances to fail, learn, and iterate. PewDiePie proved individuals can push boundaries with enough persistence. But the real shift is moving from solo experiments to network-scale intelligence. That’s the layer ./Echo is building making advanced agent training less about surviving hardware limits, and more about scaling intelligence itself.
QME
Justin Dao@DaongPP
One of the main reasons I’m paying close attention to @Gradient_HQ is the team behind it. In AI and crypto, ideas are cheap execution is everything. And Gradient has a seriously stacked team. We’re talking ACM/NOI World Finalists and Gold Medalists, people who’ve competed at the highest level in algorithms and computer science. That’s not just prestige, it signals deep technical depth. On the research side, the team includes engineers with years of experience working on decentralized AI a space that’s still extremely early and technically complex. This isn’t trend-chasing. It’s long-term conviction. Academically, the team comes from top institutions like UC Berkeley, Carnegie Mellon, ETH Zurich, Imperial College London, and UCLA. Professionally, they’ve built at places like Google, Apple, and ByteDance. That mix of elite research background + real-world scaling experience is rare. If you’re trying to build a new AI runtime and challenge centralized intelligence, you need more than hype you need builders who understand both distributed systems and frontier AI. Gradient isn’t just shipping a product. They’re trying to redefine the AI infrastructure layer and the team reflects that ambition.
QME

还有在车上的兄弟吗,看来预测成功了,我昨天不仅空投没有卖,0.037,0.038 又抄底了 4000 多 U,这是我 2026 唯一看好的一个币,平时的我拿到币都是第一时间卖掉的,10 亿市值只是起点,冲冲冲!
@openmind_agi @FabricFND

aling@aling2000520
ROBO=SKR ROBO=MMT ROBO=0G ROBO=WET No one will be willing to believe me recently. Give him some time, and you will understand what I mean in the future… @FabricFND @openmind_agi
中文
One of the main reasons I’m paying close attention to @Gradient_HQ is the team behind it.
In AI and crypto, ideas are cheap execution is everything. And Gradient has a seriously stacked team.
We’re talking ACM/NOI World Finalists and Gold Medalists, people who’ve competed at the highest level in algorithms and computer science. That’s not just prestige, it signals deep technical depth.
On the research side, the team includes engineers with years of experience working on decentralized AI a space that’s still extremely early and technically complex. This isn’t trend-chasing. It’s long-term conviction.
Academically, the team comes from top institutions like UC Berkeley, Carnegie Mellon, ETH Zurich, Imperial College London, and UCLA. Professionally, they’ve built at places like Google, Apple, and ByteDance.
That mix of elite research background + real-world scaling experience is rare.
If you’re trying to build a new AI runtime and challenge centralized intelligence, you need more than hype you need builders who understand both distributed systems and frontier AI.
Gradient isn’t just shipping a product.
They’re trying to redefine the AI infrastructure layer and the team reflects that ambition.

Justin Dao@DaongPP
Most people don’t realize how broken real-world AI inference still is. Latency spikes, fragmented data sources, and siloed compute make “real-time intelligence” feel more like a buzzword than reality. Whether it’s agents reacting to live markets, autonomous robotics, or real-time copilots — the bottleneck is always the same: inference isn’t built for a dynamic world. That’s exactly the gap Gradient is trying to solve with Parallax, a world inference engine. Instead of treating inference like a static API call, Parallax is designed to model the world as a constantly shifting state. It pulls signals from distributed sources, processes them across decentralized compute, and delivers context-aware intelligence that evolves in real time. In practice, this matters more than people think. Today, traders rely on fragmented dashboards, AI agents hallucinate due to stale context, and real-time apps break under scale. A system like Parallax reframes inference as a living layer closer to how humans reason: continuously updating, contextual, and adaptive. If Echo is about scaling how models learn, then Parallax is about scaling how models understand the world. And in a future where AI agents operate autonomously across finance, robotics, and the open internet, the real edge won’t just be better models it’ll be better inference layers. @Gradient_HQ isn’t just building models. They’re rebuilding the intelligence stack.
English
@nyanbinance Các bác cho em xin một follow ạ. Em cảm ơn các bác nhiều.
binance.com/vi/square/prof…
Tiếng Việt


