WILLIAM DARAN(daranwilliam.bsky.social) retweetledi

LMAO. High IQ genes are basically just "willing to study more" genes
nature.com/articles/s4146…

English
WILLIAM DARAN(daranwilliam.bsky.social)
4.8K posts


@DaranWilliam
An Aspiring GENETICIST l PhD student ( 2023-2027) in Human genetics. Genetics (evolutionary,psychiatry, behavior,complex traits)+ MS (GWAS&GxE).NEFELIBATA I AM.

Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/

"Mathematics in the age of AI"—a one-hour conversation I had earlier this year, for an audience of machine-learning graduate students at Université Paris-Saclay. [In French] youtube.com/watch?v=_dTbfL…


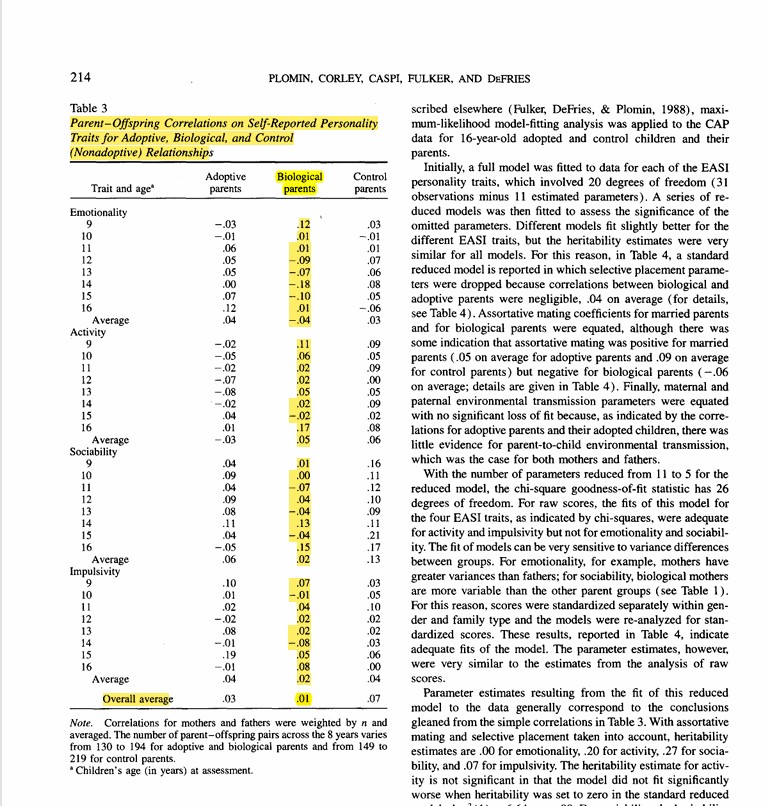
When you blame your personality on your parents, it's more from their genes than their actions. 62 studies, 100k+ people: extraversion, reactivity, agreeableness, conscientiousness & openness are ~40% heritable. You don't choose your traits. You do choose how you express them.



I'm a former Harvard PhD student. Based on my experience, current social science students probably make a bit over $250k + healthcare over 5 years, with just 784 hours of required TA work. That's almost $320/hour for the "work" and the rest is classes and your own research.




Quantifying direct genetic signal captured by principal component adjustment | PNAS pnas.org/doi/abs/10.107…



Dear Bengal, This rare pic of Netaji Subhas in 13 Feb 1933 when he was being exiled in Europe. As the ship left the shores of India, Netaji wrote a MESSAGE for Bengalis. Plz read it before cast your vote today.🙏🏾 "One of the dreams that have inspired me and given a purpose to my life, is that of a great and undivided Bengal devoted to the service of India and of humanity - a Bengal that is above all sects and groups and is the home alike of the Muslim, the Hindu, the Christian and the Buddhist. It is this Bengal - the Bengal of my dreams - the Bengal of the future still in embryo - that I worship and strive to serve in my daily life." All his life Netaji carried this dream along. Our forefathers failed Netaji. Please don't fail him this time. 🙏🏾🙏🏾🙏🏾




