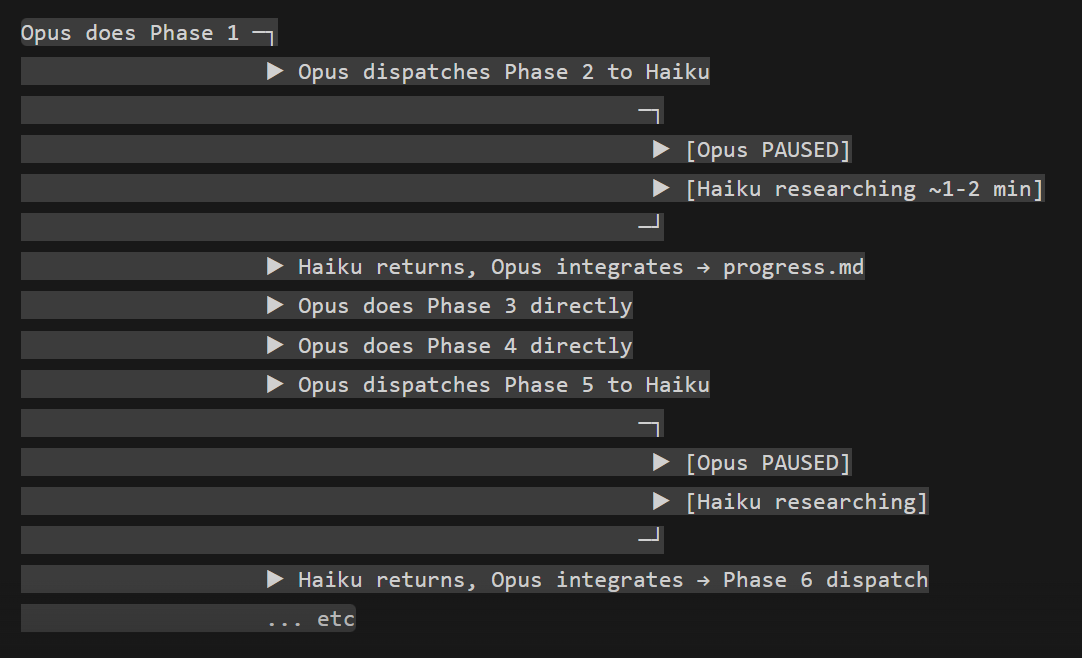
A pergunta óbvia: por que não falar pro orquestrador continuar trabalhando depois de delegar?
O framework tem uma flag (run_in_background=true) que deixa o subagent rodar separado. A API suporta paralelismo.
Mas pra usar, o orquestrador precisa decidir fazer outra coisa enquanto espera. E LLMs são treinados pra raciocinar de forma sequencial. Mesmo com a flag ativada, o modelo geralmente só delega e fica esperando.
A capacidade tá lá. Se o modelo vai usar é outra história.
Português