Joseph DeCorte retweetledi

While he was writing ULYSSES, Joyce told his friend Frank Budgen that he’d spent eight hours working on a single sentence.
The sentence: “The heaventree of stars hung with humid, nightblue fruit.”
English
Joseph DeCorte
178 posts


@DecorteJoseph
Vandy MSTP | Interests: math, chemistry, immunology. Inferring based on the nonsense I was trained on


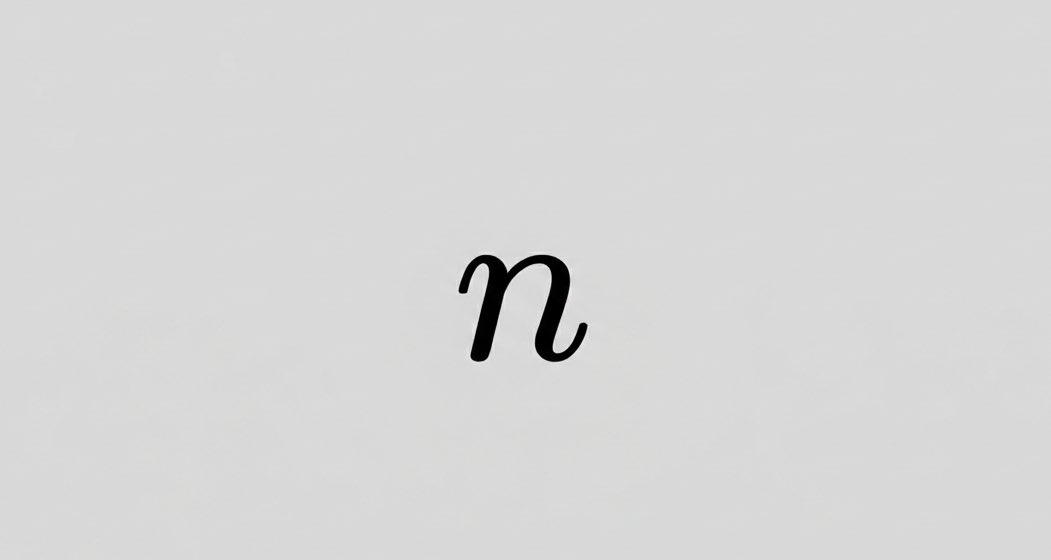
Every known prime number more than 3 is of the type 2n±1.








Big news from Boltz today: we’re launching Boltz Lab, a new platform with new small-molecule + protein design agents, announcing Boltz PBC and a $28M seed round, and sharing a multi-year partnership with Pfizer. More below! 🚀
Join us this Friday 1/9 at 11:00am in Light Hall 202 for @DecorteJoseph's Dissertation Defense! He will present "Ensemble-Based Methods for Predicting PROTAC Degradation Efficiency" completed in the @MeilerLab through the Chemical Biology Graduate Program!