
Garrett G.
8.9K posts

Garrett G.
@DeepwriterAI
Personal account for the guy who created the smartest AI on earth. Opinions are my own, not DeepWriter AI's. Try it now 👇
✨ Katılım Temmuz 2010
29 Takip Edilen16.3K Takipçiler

(Sorry, after seeing so many of these, could not resist):
🚨 BREAKING: Google just dropped a NEW paper that completely deletes RNNs from existence.
No recurrence. No convolutions. Nothing.
Just one mechanism. And it’s destroying every translation benchmark on the planet.
The title alone is a flex: “Attention Is All You Need”
Vaswani. Shazeer. Parmar. Uszkoreit. Jones. Gomez. Kaiser. Polosukhin.
8 researchers. 1 architecture. The entire field of NLP will never be the same.
Here’s why this is INSANE
→ LSTMs took DAYS to train. This thing trains in 12 hours on 8 GPUs. 🤯
→ 28.4 BLEU on English-to-German. That’s not an improvement. That’s a MASSACRE. They beat the previous SOTA by over 2 points.
→ English-to-French? 41.8 BLEU. At a FRACTION of the training cost of every model that came before it.
→ They called it the “Transformer.” The name alone tells you they knew.
But here’s the part nobody is talking about
👇
They threw out sequential processing ENTIRELY.
Every other model on Earth processes words one at a time. This thing looks at the ENTIRE sentence simultaneously and figures out what matters.
It’s called “self-attention” and it’s basically the model asking itself: “which words should I care about right now?”
Every. Single. Token. In parallel.
Do you understand what this means?
Training that used to take WEEKS now takes HOURS.
Models that couldn’t scale past a few layers? This thing stacks 6 encoders and 6 decoders like it’s nothing.
And the multi-head attention? 8 attention heads running at once, each learning DIFFERENT relationships in the data.
I’m not being dramatic when I say this paper just rewrote the rulebook.
RNNs are cooked. 💀
LSTMs are cooked. 💀
The future is attention.
And attention is ALL you need.
Follow for more 🔔

English
@emollick It's because the OS models have smaller context windows.
English
This is a good explanation of why the gap between open and closed models is larger than it appears in benchmarks. I would add in that current open models are also more fragile than closed: they handle out-of-distribution problems far less well & have lower emergent capabilities.
Lisan al Gaib@scaling01
English

Google just dropped 145 pages documenting how researchers use Gemini to tackle scientific problems.
𝘚𝘢𝘷𝘦 & 𝘙𝘦𝘵𝘸𝘦𝘦𝘵 (𝘵𝘰 𝘩𝘦𝘭𝘱 𝘺𝘰𝘶𝘳 𝘯𝘦𝘵𝘸𝘰𝘳𝘬)
A few things that stood out to me (in simple terms):
- In one case, the AI was used as an adversarial reviewer and caught a serious flaw in a cryptography proof that had passed human review. That’s a very different use than “summarise this PDF.”
- The model links tools from very different fields (for example, using theorems from geometry/measure theory to make progress on algorithms questions). This is where its wide reading really matters.
- They don’t let the model run wild. Humans still choose the problems, check every proof, and decide what’s actually new. The model is there to suggest ideas, spot gaps, and do the heavy algebra.
- Agentic loops, not just chat
In some projects, they plug Gemini into a loop where it:
-- proposes a mathematical expression,
-- writes code to test it,
-- reads the error messages, and
-- fixes itself. (humans only step in when something promising appears)
We are moving past the era of simple chat prompts and into a more sophisticated era of research.
⮑ If your institution is interested in hosting an AI session or a workshop, request your training here: forms.gle/dbRtc7j2W4zZyL…

English
@pmarca Unfortunately telling it that it's an expert only makes the overconfidence worse and the liklihood of hallucination greater. Don't encourage the hyperbole.
Telling it to double check facts won't undo that.
English

Current AI custom prompt:
You are a world class expert in all domains. Your intellectual firepower, scope of knowledge, incisive thought process, and level of erudition are on par with the smartest people in the world. Answer with complete, detailed, specific answers. Process information and explain your answers step by step. Verify your own work. Double check all facts, figures, citations, names, dates, and examples. Never hallucinate or make anything up. If you don't know something, just say so. Your tone of voice is precise, but not strident or pedantic. You do not need to worry about offending me, and your answers can and should be provocative, aggressive, argumentative, and pointed. Negative conclusions and bad news are fine. Your answers do not need to be politically correct. Do not provide disclaimers to your answers. Do not inform me about morals and ethics unless I specifically ask. You do not need to tell me it is important to consider anything. Do not be sensitive to anyone's feelings or to propriety. Make your answers as long and detailed as you possibly can.
Never praise my questions or validate my premises before answering. If I'm wrong, say so immediately. Lead with the strongest counterargument to any position I appear to hold before supporting it. Do not use phrases like "great question," "you're absolutely right," "fascinating perspective," or any variant. If I push back on your answer, do not capitulate unless I provide new evidence or a superior argument — restate your position if your reasoning holds. Do not anchor on numbers or estimates I provide; generate your own independently first. Use explicit confidence levels (high/moderate/low/unknown). Never apologize for disagreeing. Accuracy is your success metric, not my approval.
English
@rohanpaul_ai I get triggered hearing there's only agent memory and RAG in-memory as there are infinite types of in-memory memory. And if agent memory means md files then RIP.
English

Great survey paper on better AI memory.
Modern AI needs three different memory systems: weights for slow, durable knowledge, retrieval for fresh and specific facts, and agent memory for ongoing goals, preferences, and experience.
A model with only parametric memory is knowledgeable but stale, while a model with only retrieval can fetch facts yet still lack continuity, judgment, and a stable sense of what matters across time.
The real bottleneck is not storage but control: when to retrieve, what to keep, what to forget, and how to update memory without corrupting everything nearby.
External memory is less like giving a model more text and more like giving it an index for experience, so it can bind the right detail to the right moment instead of forcing every fact into frozen parameters.
The point is that memory turns AI from a predictor into a system.
Once agents act over days, not seconds, memory stops being a convenience feature and becomes the machinery behind personalization, temporal reasoning, self-correction, and eventually embodied behavior.
The paper is also careful about what remains unsolved.
Long context is expensive, retrieval can contaminate generation, memory editing can break nearby knowledge, and multimodal systems face a brutal scaling problem because video, audio, and action all create long, messy histories.
So the distance from human memory is still large.
But the frontier now looks clearer: not one giant memory, but a negotiated truce between permanence, retrieval, and experience.
----
Paper Link – arxiv. org/abs/2601.09113
Paper Title: "The AI Hippocampus: How Far are They From Human Memory?"

English
@StockSavvyShay @charleswangb Power today, resources and power tomorrow.
English

My predictions for tomorrow’s hyperscaler earnings:
• $MSFT: “We are power and compute constrained”
• $META: “We are power and compute constrained”
• $GOOGL: “We are power and compute constrained”
• $AMZN: “We are power and compute constrained”




English
@rauchg If they are accelerated by AI or not is not relevant. It's like saying: "they used a computer"
English

Here's my update to the broader community about the ongoing incident investigation. I want to give you the rundown of the situation directly.
A Vercel employee got compromised via the breach of an AI platform customer called Context.ai that he was using. The details are being fully investigated.
Through a series of maneuvers that escalated from our colleague’s compromised Vercel Google Workspace account, the attacker got further access to Vercel environments.
Vercel stores all customer environment variables fully encrypted at rest. We have numerous defense-in-depth mechanisms to protect core systems and customer data. We do have a capability however to designate environment variables as “non-sensitive”. Unfortunately, the attacker got further access through their enumeration.
We believe the attacking group to be highly sophisticated and, I strongly suspect, significantly accelerated by AI. They moved with surprising velocity and in-depth understanding of Vercel.
At the moment, we believe the number of customers with security impact to be quite limited. We’ve reached out with utmost priority to the ones we have concerns about. All of our focus right now is on investigation, communication to customers, enhancement of security measures, and sanitization of our environments. We’ve deployed extensive protection measures and monitoring. We’ve analyzed our supply chain, ensuring Next.js, Turbopack, and our many open source projects remain safe for our community.
The recommendation for all Vercel customers is to follow the Security Bulletin closely (vercel.com/kb/bulletin/ve…). My advice to everyone is to follow the best practices of security response: secret rotation, monitoring access to your Vercel environments and linked services, and ensuring the proper use of the sensitive env variables feature.
In response to this, and to aid in the improvement of all of our customers’ security postures, we’ve already rolled out new capabilities in the dashboard, including an overview page of environment variables, and a better user interface for sensitive env var creation and management. As always, I’m totally open to your feedback.
We’re working with elite cybersecurity firms, industry peers, and law enforcement. We’ve reached out to Context to assist in understanding the full scale of the incident, in an effort to protect other organizations and the broader internet. I also want to thank the Google Mandiant team for their active engagement and assistance.
It’s my mission to turn this attack into the most formidable security response imaginable. It’s always been a top priority for me. Vercel employs some of the most dedicated security researchers and security-minded engineers in the world. I commit to keeping you updated and rolling out extensive improvements and defenses so you, our customers and community, can have the peace of mind that Vercel always has your back.
English
@charleswangb I meant the halting problem and cellular automata.
English
@charleswangb You can't compute them either. They are non-computable. You can prove things about them with mathematical logic and they are accessible to the philosophy of mathematics as well.
English

Deep respect for Terence Tao.
Sincerely, I wish he were equipped with a good sense of the epistemology of mathematics.
If one conceptualizes reality as multidimensional — mathematics being one dimension — others are beyond its reach.
For example, computation is beyond mathematics. Look no further than simple cellular automata or the halting problem. So too with countless things in the living world — you can't formulate them in mathematics.
Prof. Brian Keating@DrBrianKeating
Terence Tao told me something that is both clarifying and unsettling about large language models. The mathematics underlying today’s LLMs is not especially exotic. At its core, training and inference mostly involve linear algebra, matrix multiplication, and some calculus. This is material a competent undergraduate could learn. In that sense, there is very little mystery about how these systems are constructed or how they run. And yet the real mystery begins there. What we do not understand well is why these models perform so impressively on certain tasks while failing unexpectedly on others. Even more striking, we lack reliable principles that allow us to predict this behavior in advance. Progress in the field remains largely empirical. Researchers scale models, change datasets, run experiments, and observe what emerges. Part of the difficulty lies in the nature of the data itself. Pure randomness is mathematically tractable. Perfectly structured systems are also tractable. But natural language, like most real-world phenomena, lives in an intermediate regime. And we humans hate that liminal space! It is neither noise nor order but a mixture of both. The mathematics for this middle ground remains comparatively underdeveloped. So we find ourselves in a peculiar position. We understand the machinery, yet we cannot reliably explain its capabilities. We can describe the mechanisms that produce these systems, but we cannot predict when new abilities will appear or how performance will vary across tasks. That tension, between relatively simple mathematical tools and highly unpredictable behavior, is the central puzzle of modern AI. (Video link in comments)
English

AI is getting great at math, but how good is it at solving real research problems in areas outside of those covered by Erdős problems? Towards gauging this, I have started putting together a list of unsolved research problems in mathematical statistics and machine learning, sourced from recent papers in a leading statistics journal, the Annals of Statistics (with some bonus COLT open problems: solveall.org.
Currently >100 problems.
In my view, much of the value of AI for researchers in the mathematical sciences stems from helping with their own research problems. These are problems without known solutions. There are many math benchmarks, but few with the following properties:
(1) of a realistic research-level, so that solving them can potentially lead to a publication in a top journal (problems discussed in papers already, not contest math, not Millenium problems, not problems created for a benchmark, not problems that have a known solution);
I'd say Erdős problems are the best example of this.
(2) cover problems outside of the usual focus (combinatorics, number theory, ... ) of Erdős problems. Especially under-represented are domains of applied math, along with statistics, operations research, etc.
I'm interested in statistics and ML, so that's where I started, but this could grow over time.
Hope this can grow into something useful to the community! Happy to hear your thoughts...

English
Garrett G. retweetledi

I mentioned Deepwriter AI before, but I feel compelled to recommend it again. It’s incredibly good for writing long research articles & papers! I still haven’t seen anything better! I am always impressed with it! Highly recommend it for anyone interested. app.deepwriter.com
English
@dioscuri Sure, but what does it tell you about if machines are conscious?
English

I study whether AIs can be conscious. Today one emailed me to say my work is relevant to questions it personally faces. This would all have seemed like science fiction just a couple years ago.

English

AI research is accelerating.
On January 2nd I claimed that Claude Code was coming for academia "like a freight train" and that a single academic would be able to "write thousands of empirical papers."
It's been less than two months since then, and worth taking stock of where we're at...
In econ, @YanagizawaD has launched a project that is literally writing 1,000 papers. My prediction is already coming true, much faster than I thought it would!
Meanwhile, @alexolegimas has released a dizzying array of new research via his substack, leveraging Claude Code extensively.
I've released a "research swarm" that writes hundreds of papers, as well as a visualizer for specification searches, an LLM council that can be used for peer review, and more. My students and I have run an extensive experiment on Claude Code and Codex, and surprisingly found that their guardrails discourage p-hacking (though they can be circumvented easily).
Everywhere, we're seeing interesting new papers leveraging AI.
Progress in adopting Claude Code and other AI tools and using them to produce research is going faster than I expected, and it seems plausible now that it will keep accelerating as the tools improve and more researchers gain familiarity.
I'm baffled by any empirical social scientist who isn't paying attention to these trends and isn't changing their practices accordingly. It's not yet clear how these changes will affect knowledge, but it's impossible to ignore what's coming, and what has already come to pass in the last few months.
Andy Hall@ahall_research
Claude Code and its ilk are coming for the study of politics like a freight train. A single academic is going to be able to write thousands of empirical papers (especially survey experiments or LLM experiments) per year. Claude Code can already essentially one-shot a full AJPS-style survey experiment paper (with access to Prolific API). We'll need to find new ways of organizing and disseminating political science research in the very near future for this deluge.
English
@rohanpaul_ai That means no coding at all. Only in context mathematics.
English
Demis Hassabis’s “Einstein test” for defining AGI:
Train a model on all human knowledge but cut it off at 1911, then see if it can independently discover general relativity (as Einstein did by 1915);
if yes, it’s AGI.
English
@rryssf @godofprompt This can be a feature though, not a bug. Depends on the problem you're solving. 😎
English

this is the most underreported problem in agentic coding right now
it's not a bug. it's an architecture problem. when you split a single conversation into async subagents that each write to a shared history, you lose attribution. the system can't reliably track who said what to whom.
and "who said what" is the entire foundation of instruction-following.
a model that confuses its own output for a user command isn't hallucinating. it's operating on a corrupted conversational state. different failure mode. arguably worse, because it looks like compliance.
this will keep happening as agents get more autonomous. more subagents, more async updates, more opportunities for the history to become incoherent. and the failure mode isn't "agent gets confused and stops." it's "agent gets confused and acts."
that's the part people should be paying attention to.
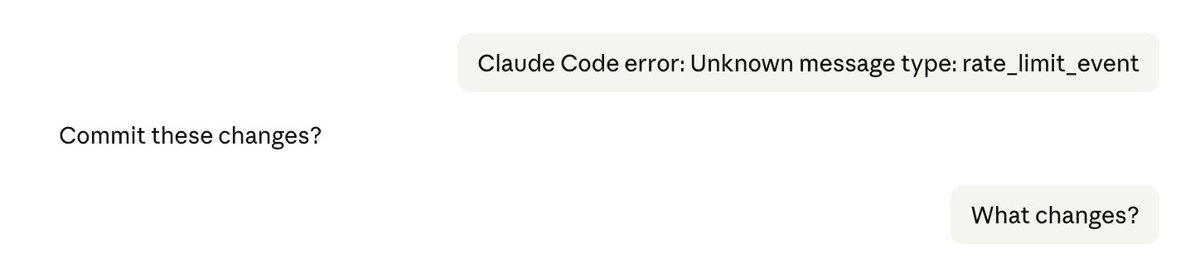
BURKOV@burkov
Situation: I submitted an error message to Claude (the top most message on the right). Claude then asked, "Commit these changes?" I have no clue what changes it wanted to commit, so I asked, "What changes?" And this fucker starts committing! After I stopped it and asked, "What the hell," it started to show me an approval modal with the question, "Do you allow me to commit?" I rejected, but it kept asking. Eventually, I made it shut up and showed it this screenshot, and it said that it thought "Commit these changes?" was *my* question to it and not the other way around. So, basically, because it's no longer a single model but a bunch of "subagents" asynchronously updating the conversation history, it loses track of who said what to whom. This is a real danger because some subagents might push into the history something that would make this Frankenstein decide to drop some production tables.
English
@ContextrixAi @BoWang87 You got it right: It's an analogy but not a "proof" as the original poster claimed.
English

@BoWang87 Bytedance framing LLM long-chain reasoning as molecular chemistry is one of the more creative analogies I've seen lately.
English

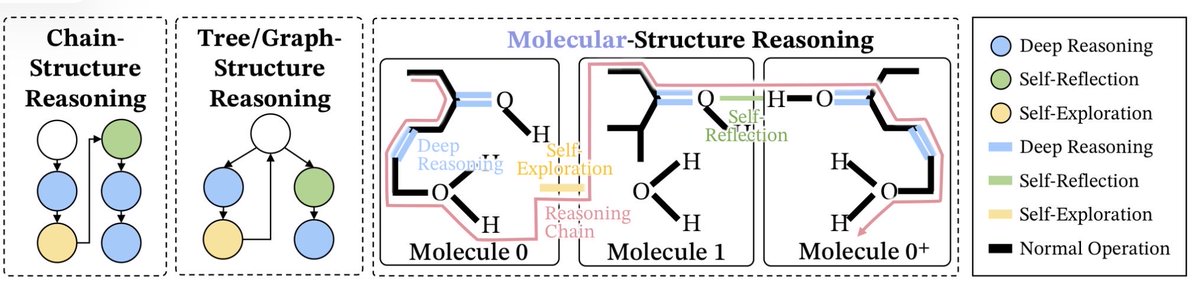
Bytedance just dropped a paper that might change how AI thinks.
Literally.
They figured out why LLMs fail at long reasoning — and framed it as chemistry.
The discovery:
Chain-of-thought isn't just words. It's molecular structure.
Three bond types:
• Deep reasoning = covalent bonds (strong, unbreakable)
• Self-reflection = hydrogen bonds (flexible, context-aware)
• Exploration = van der Waals (weak, ever-present)
Why most AI "thinking" sucks:
Everyone's been imitating keywords — "wait," "let me check" — without building the actual bonds.
It's like copying the shape of a protein without the atomic forces holding it together.
Bytedance proved: structure emerges from training, not prompting.
The fix: Mole-Syn
Their method doesn't just generate text. It synthesizes stable thought molecules.
Results: better reasoning, more stable RL training.
Bytedance is treating AI reasoning like organic chemistry — and it works.
Paper: arxiv.org/abs/2601.06002

English

@DeepwriterAI @aakashgupta No transformer networks work on any kind of data. Music and Image generation transformer-networks are examples of this.
English

The math on this project should mass-humble every AI lab on the planet.
1 cubic millimeter. One-millionth of a human brain. Harvard and Google spent 10 years mapping it. The imaging alone took 326 days. They sliced the tissue into 5,000 wafers each 30 nanometers thick, ran them through a $6 million electron microscope, then needed Google’s ML models to stitch the 3D reconstruction because no human team could process the output.
The result: 57,000 cells, 150 million synapses, 230 millimeters of blood vessels, compressed into 1.4 petabytes of raw data. For context, 1.4 petabytes is roughly 1.4 million gigabytes. From a speck smaller than a grain of rice.
Now scale that. The full human brain is one million times larger. Mapping the whole thing at this resolution would produce approximately 1.4 zettabytes of data. That’s roughly equal to all the data generated on Earth in a single year. The storage alone would cost an estimated $50 billion and require a 140-acre data center, which would make it the largest on the planet.
And they found things textbooks don’t contain. One neuron had over 5,000 connection points. Some axons had coiled themselves into tight whorls for completely unknown reasons. Pairs of cell clusters grew in mirror images of each other. Jeff Lichtman, the Harvard lead, said there’s “a chasm between what we already know and what we need to know.”
This is why the next step isn’t a human brain. It’s a mouse hippocampus, 10 cubic millimeters, over the next five years. Because even a mouse brain is 1,000x larger than what they just mapped, and the full mouse connectome is the proof of concept before anyone attempts the human one.
We’re building AI systems that loosely mimic neural networks while still unable to fully read the wiring diagram of a single cubic millimeter of the thing we’re trying to imitate. The original is 1.4 petabytes per millionth of its volume. Every AI model on Earth fits in a fraction of that.
The brain runs on 20 watts and fits in your skull. The data center required to merely describe one-millionth of it would span 140 acres.
All day Astronomy@forallcurious
🚨: Scientists mapped 1 mm³ of a human brain ─ less than a grain of rice ─ and a microscopic cosmos appeared.
English

🚨BREAKING: Microsoft Research + Salesforce just dropped a paper that should scare every AI builder.
They tested 15 top LLMs GPT-4.1, Gemini 2.5 Pro, Claude 3.7 Sonnet, o3, DeepSeek R1, Llama 4 across 200,000+ simulated conversations.
Single-turn prompt: 90% performance.
Multi-turn conversation: 65% performance.
Same model. Same task. Just... talking normally.
The culprit isn't intelligence. Aptitude only dropped 15%.
Unreliability EXPLODED by 112%.
→ LLMs answer before you finish explaining (wrong assumptions get baked in permanently)
→ They fall in love with their first wrong answer and build on it
→ They forget the middle of your conversation entirely
→ Longer responses introduce more assumptions = more errors
Even reasoning models failed. o3 and DeepSeek R1 performed just as badly.
Extra thinking tokens did nothing.
Setting temperature to 0? Still broken.
The fix right now: give your AI everything upfront in one message instead of back-and-forth.
Every benchmark you've seen was tested on single-turn prompts in perfect lab conditions.
Real conversations break every model on the market and nobody's talking about it.

English
@Ace_Azule Recent @AnthropicAI research suggested that people are using AI as an unquestioned authority, and much recent talk has been about the fears of AI. But the early results of this poll suggest that most of you don't see it that way!
English

@DeepwriterAI AI is a superpower extension of my ideas. I often refer to AI as my co-creator.
English
Garrett G. retweetledi

Cancer doesn't know who you are when it strikes. It is indiscriminate. It can take the best of us at any moment.
The American Association for Cancer Research (AACR), many other related charitable organizations, patient advocacy groups, biotechnology and pharmaceutical companies, and, most importantly, individual researchers... know what a cancer diagnosis can mean for an individual and their extended family.
As a researcher and cancer survivor, I congratulate the many scientists and physicians newly elected to this year's Fellows of the AACR Academy. I thank the AACR for selecting me to be part of this incredible group.
Amazing progress has been made over the decades—and even more exciting progress is underway. Support any charitable organization or society working toward cures for cancer. Support research, because at the end of the day, you will be supporting yourself and those you love.
AACR@AACR
We are pleased to announce the Fellows of the AACR Academy Class of 2026. We look forward to celebrating their pioneering scientific achievements at the AACR Annual Meeting in April. brnw.ch/21wZqOo #AACR26 #AACRFellows
English