
@tolibear_ 10x ChatGPT Plus only costs $200/month. Why pay 100x the price for just 10x the value?
English
Delio Siret
464 posts
@DelioSiret
AI/AGI researcher | Mathematician | Engineer | ML Prof | Christian | Dad of a wonderful son | Exploring intelligence, science & tech






Google DeepMind researcher argues that LLMs can never be conscious, not in 10 years or 100 years. "Expecting an algorithmic description to instantiate the quality it maps is like expecting the mathematical formula of gravity to physically exert weight."





was messing with the OpenAI base URL in Cursor and caught this accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast so composer 2 is just Kimi K2.5 with RL at least rename the model ID


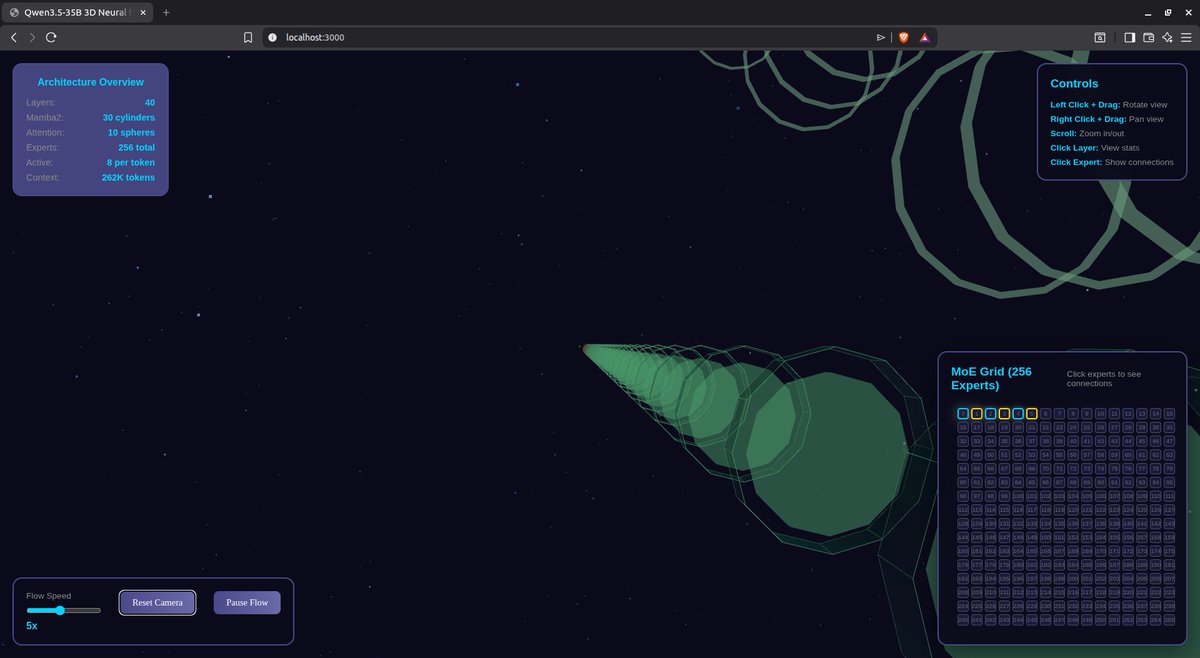
single RTX 3090. 24 GB VRAM. Qwen3.5-35B-A3B. 4-bit quant, 113 tokens per second at full 262K context harnessing Claude Code locally with no API, no subscription, no proxy. told it what it is. 30 Mamba2 layers, 10 attention, 256 experts, 8 active per token. said "build something that shows off what you can do." it visualized its own architecture. interactive. tokens flowing through layers. 256 experts lighting up on routing. served in the browser from the same GPU running inference. single prompt. then i said level up. 3D. Three.js. separate files. flythrough camera. clickable layers. it planned first, scaffolded 6 files, hit one API bug, fixed it itself, then optimized for smooth framerate. two iterations to a working 3D neural network explorer. llama.cpp just merged a native Anthropic endpoint. Claude Code points at localhost. the whole setup is two commands. no LiteLLM. no proxy config. the open source models coming out of china right now are genuinely changing what's possible on consumer hardware. respect to the Qwen team. this is acceleration.


Beat it by having Codex hand-craft weights: gist.github.com/N8python/02e41… 100% accuracy on 10 million random test cases w/ only 343 parameters. As a bonus, it uses the vanilla Qwen3 architecture, just with the right weights.









