
frzlt
886 posts







Go local. You only need a 16GB card to get started with decent models!
Julien Chaumond@julien_c
run local models TODAY
English
@Hunchoquavo153 God of lightning got tased by an electroshock, the worst scene
English

@LottoLabs How dumb is it ? It seems it is dumber even gemma 12b how it feel on practice ?
English
@LottoLabs What if there wil be no open weights anymore thats why they rebrand
English

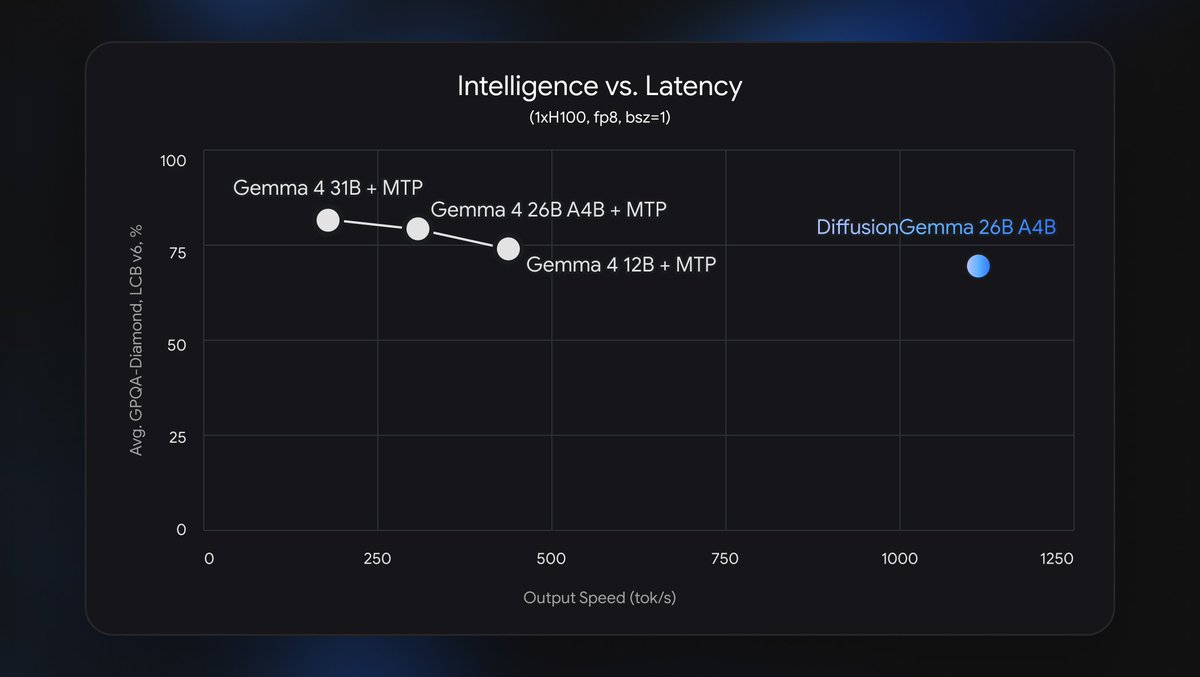
🚨 Oh 💩! HUGE!! Google just jumped on the text-diffusion train with DiffusionGemma (Gemma 4 family)!!
🔥 26B total → only ~3.8B active params
⚡ Up to 4x faster token output (1000+ tok/s on high-end GPUs)
🛠️ Block-parallel generation = built-in self-correction & better code/markdown editing
📦 Fully open source (Apache 2.0) — available NOW on HF
🏆 Localmaxxers win again!! No new hardware needed — runs great on your 24GB+ setups.
Who’s trying it first? 👇
Google AI Developers@googleaidevs
DiffusionGemma, our experimental open model released under an Apache 2.0 license, explores text diffusion, an exceptionally fast approach to text generation. Here’s how DiffusionGemma accelerates development: + Faster token output: By shifting the bottleneck from memory bandwidth to raw compute, the model generates up to 4x faster token output on dedicated GPUs + Accessible hardware footprint: Activates just 3.8B parameters during inference, fitting comfortably within 24GB-VRAM high-end consumer GPUs when quantized + Novel workflows: Parallel token generation enables self-correction, making it ideal for code infilling, in-line editing, and non-linear structures DiffusionGemma prioritizes speed over raw quality and accelerates best on compute-bound hardware (like @NVIDIAAI GPUs). Standard @GoogleGemma 4 remains recommended for production quality and memory-bound devices.
English

DiffusionGemma is our new experimental open model with up to 4x faster output on dedicated GPUs.
Instead of predicting word-by-word, it generates entire blocks of text simultaneously. This lets the model self-correct and format complex markdown in real time.

English

What is unsloth cooking up
Unsloth AI@UnslothAI
Google releases DiffusionGemma.✨ The new 26B-A4B diffusion text model runs locally on 18GB RAM. It supports high-speed text generation, thinking, image, video and 256K context. Run and train via Unsloth Studio. GGUF: huggingface.co/unsloth/diffus… Guide: unsloth.ai/docs/models/di…
English






The most underrated thing in AI right now is that “good enough” local intelligence has arrived.
Gemma 4 12B on a 16GB laptop covers everything everything normal users need.
Unlimited, free forever, and completely offline.
English
Google really seen this and said let’s launch 12b
Lotto@LottoLabs
It’s kinda sad we knowing we won’t get another Gemma model this year
English


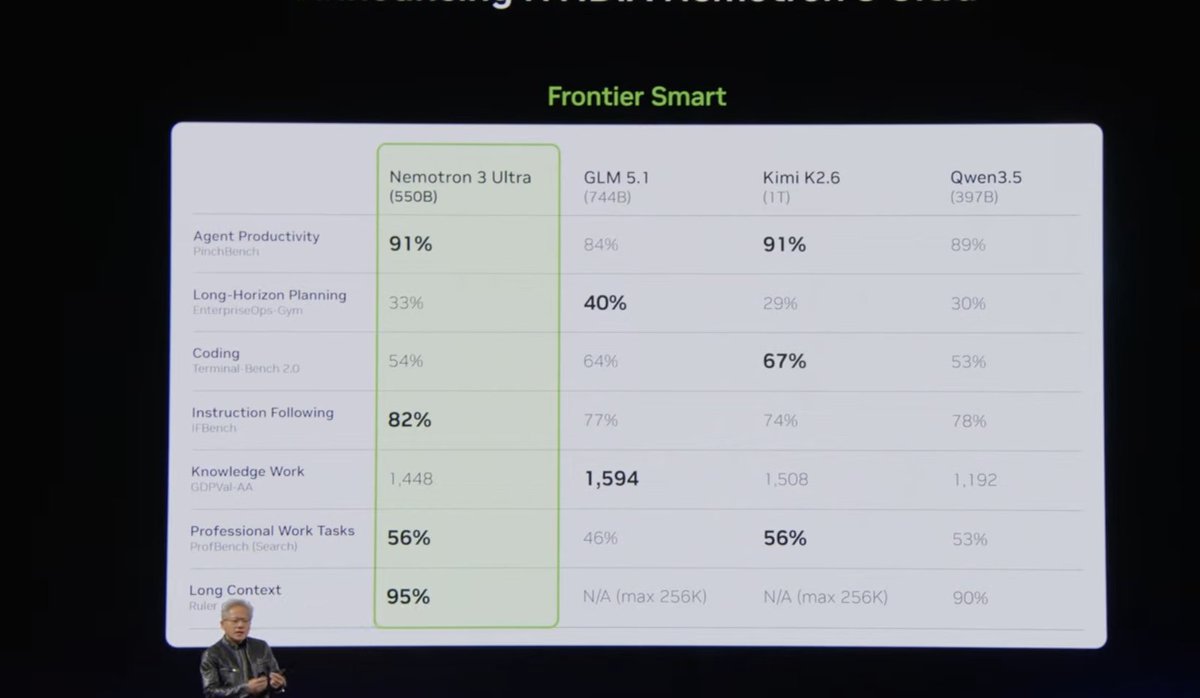
Nemotron 3 Ultra model!
550B parameter, near state of the art open weight (on par with GLM-5.1 and Kimi K2.6)
We shall see how it is in practice
English

DeepSeek just EMBARRASSED Claude Opus 4.7
Just switched to DeepSeek V4 Pro for a few days
Cost:
DeepSeek V4 Pro = $2.02
Claude Opus 4.7 = $265.21
Same quality for most of the medium tasks with no noticeable difference in output
I know it’s hosted in China with cheap electricity but at this point western labs are getting cooked on price

English

От шо яхтклуби вміють так це напхати секреток, вже годину шарюся по 4 екранах міста і все якусь хуйню знаходжу
Українська
