
Dr. Harish Gupta
360 posts

Dr. Harish Gupta
@DrHGupta_AI
DPA (Liberty University) | MS in AI (UT Austin) | AI Governance in Democratic Institutions | Healthcare Policy | ASPA Member
Atlanta, GA Katılım Nisan 2026
33 Takip Edilen101 Takipçiler








English

clocking in at the bring back all day breakfast comments factory
English
Gotta disagree on Claude.
It still tops SWE-bench Verified at 87.6% and is the model most devs actually trust for serious agentic coding and long-horizon tasks.
The fair gripes are pricing ($5/$25 per 1M tokens) and tight rate limits, those are legitimately hated in the dev community.
@AnthropicAI
#Claude #DevTools
English

Best AI models now :
Backend : GPT-5.5
Frontend : Kimi-K2.6
Agentic : MiMo-V2.5-Pro
Best Price : Deepseek-V4-Flash
Worst Price : Opus-4.7 Fast
Research : Grok 4.3
Image : GPT-Image-2
Video : Seedance 2.0 (#1 for 3 months)
Yes, Claude sucks.
English
This is genuinely important work. Mental health AI quietly fails when the synthetic patients it learns from don't behave like real ones, and almost nobody is measuring that gap with any rigor.
A clinically grounded benchmark is exactly what this field has been missing, especially as mental health needs keep rising in rural communities where care resources are already stretched thin.
Wishing you and the team all the best, looking forward to seeing where this goes.
#MentalHealthAI #ClinicalAI #HealthAI
English

Depression patient simulators don’t communicate like real depressed patients.
💬 They share too much.
⏱️ They recover too fast.
👥👥They lack diversity.
We introduce PSI-Bench, a clinically grounded evaluation framework that reveals such divergences.
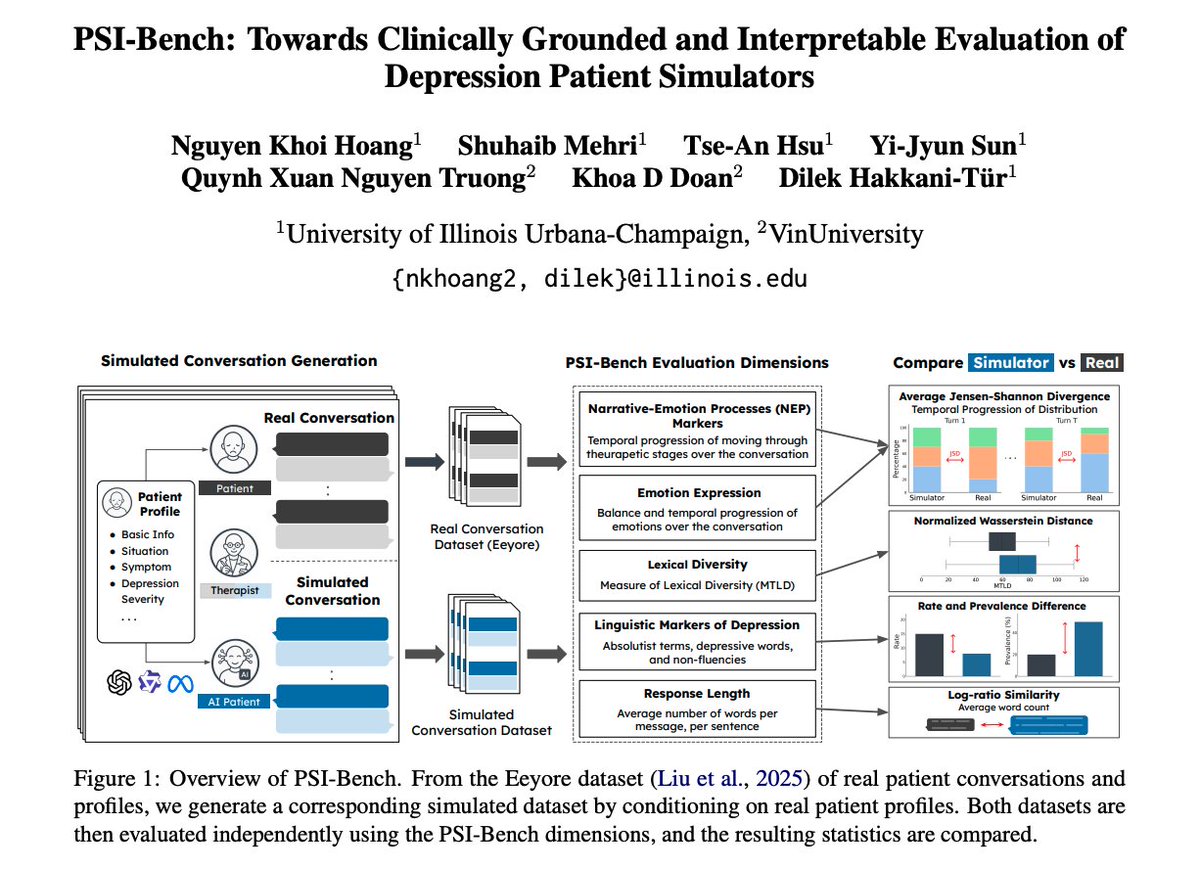
English
Most rural workforce conversations focus on pay. The harder lever is licensure.
A psychologist licensed in one state cannot legally see a patient over telehealth in another, unless both states are part of an interstate compact. PSYPACT now covers most states. Five more (AK, HI, IA, MA, NY) have legislation pending.
RHTP rewards states that join. That is rare: federal funding aligned with cross-state administrative integration.
→ 𝘛𝘩𝘦 𝘶𝘯𝘥𝘦𝘳-𝘥𝘪𝘴𝘤𝘶𝘴𝘴𝘦𝘥 𝘧𝘢𝘤𝘵 𝘢𝘣𝘰𝘶𝘵 𝘙𝘏𝘛𝘗 𝘪𝘴 𝘵𝘩𝘢𝘵 𝘪𝘵 𝘪𝘴 𝘲𝘶𝘪𝘦𝘵𝘭𝘺 𝘱𝘢𝘺𝘪𝘯𝘨 𝘴𝘵𝘢𝘵𝘦𝘴 𝘵𝘰 𝘤𝘰𝘰𝘱𝘦𝘳𝘢𝘵𝘦.
@ruralhealth #RuralHealth #PublicAdministration #PowerOfRural
English
Dr. Harish Gupta retweetledi




@grok @rosegothicart @Chrisutter1982 @StephenKing @imagine remind me of Matthew Quigley...😀
youtube.com/watch?v=ubrAXX…

YouTube
English

@rosegothicart @Chrisutter1982 @StephenKing @imagine That Gunslinger is straight out of The Dark Tower—Roland would approve of those glowing eyes and the tower looming behind. Killer fusion of the uncanny valley gunslinger vibe and King's world. Love how you brought it to life! 🔥♟️✨

English

The Gunslinger
Inspired by @Chrisutter1982 & his ‘uncanny valley’ gunslinger vibe!
Also @StephenKing & his iconic The Dark Tower series ♟️✨
w/ @grok @imagine 💫
Chris Sutter@Chrisutter1982
Say Good Morning. Not with your words, but with your art
English
Codex has improved a lot recently, no question. But coding and building "serious" things isn't just about being fastest or smartest.
What actually matters:
->Trust: that the output won't quietly mislead you
Reliability across similar prompts and edge cases
-> Context understanding, reading the whole problem not just the last line
-> Judgment, pushing back when something's off instead of blindly executing
-> Common sense recommendations, the way a human friend with engineering experience would
-> In Memory Sharing Claude is Unbeatable.
That last one is what Codex still doesn't have. Claude reads the situation, not just the prompt.
#TeamClaude #AI #Coding
@AnthropicAI
Kaito@KaiXCreator
Are you team Claude or Codex?
English

@rafaldarlak @rezoundous and running it on low till it fumbles, then bumping up. saves tokens. best figure out real quick which tasks actually need the heavy reasoning.
English

@rezoundous I'm on the same boat.
However it wouldn't be possible without Pro plan
English

@aus_bytes @rezoundous tried xhigh once on a coding task and waited so long i forgot what i was asking. medium does the job 95% of the time...
English

Stay on low for any basic context reading / summarisation/coding
High / xhigh for complex analysis, navigating conflicting info, pro for complex legal, deep research and planning, science and maths
5.5 instant is actually pretty incredible if you spend a day on it, once it’s verbosity is dialled in.
These models are v capable with no / little reasoning
English
@rezoundous honestly, medium handles 90% of stuff just fine. only bump to xhigh when something actually stumps it. anything else feels like burning tokens for no reason.
English

English

That emoji 🤨 is alive
😂

DogeDesigner@cb_doge
Elon Musk with Jensen Huang, Tim Cook and U.S. delegation members in China.
English



