Sabitlenmiş Tweet
DragAI
333 posts


DragAI
@Drag_AILabs
18 | Trying to Arrive in AI scene
INDIA Katılım Şubat 2026
19 Takip Edilen48 Takipçiler
Unlimited builds is the right call — the plugins are where Codex gets genuinely interesting and people need room to actually stress-test them.
The best way to understand what a tool can do is to break it trying to do something ambitious. Now there's no reason not to.
Nerd Note: Usage resets on a platform with active plugin infrastructure means the stress distribution across the API layer just got real — this is also a live load test whether they planned it that way or not.
English

I just submitted to the OpenAI Developer Showcase.
Not a chatbot. Not a wrapper.
A fully autonomous Security Agent that runs silently in the background — watches your files, detects exposed secrets, heals itself when it breaks, and reports every threat to a live dashboard without a single human click.
The dashboard turns red the moment it finds something.
No refresh. No prompt. Just the agent doing its job.
I built this to prove one thing:
AI doesn't live in a chat box.
Nerd Note: Recovery is mathematically proven — the test harness validates crash → heal → state write in strict sequence order, not by observation but by index position.
Submission is in. Let's see what the judges think.
#BuildingInPublic #AIAgents #OpenAI
English
Designers have been screaming about the screenshot-to-Figma workflow being broken for years. This skips the screenshot entirely and pulls the live HTML/CSS directly — that's the actual fix, not another workaround.
The real unlock is iteration speed. You're editing the real structure, not a frozen image of it. Design review cycles just got cut in half.
Nerd Note: Starting from real HTML/CSS means the design layer inherits actual computed styles — no more guessing font weights or spacing values from a flattened image.
English

Paper Snapshot lets you take a live website and paste it into Paper as fully editable layers.
- No more screenshots
- Starts from real HTML/CSS
- Edit your actual site design directly
Design iteration just got a lot closer to the real thing.
English
I'm building an autonomous self-healing security agent for the OpenAI Developer Showcase — a bot that catches its own crashes, repairs corrupted configs, and proves recovery mathematically through an adversarial test harness. Claude is the only model that keeps up inside complex project files. That's why I deserve it.
English

The code was never the hard part. It's the 47 tabs of docs, API keys, and config files you need open before writing line one.
The agent that solves this doesn't just write code — it navigates services, handles auth flows, and ships to prod without a human clicking anything. That's a fundamentally different tool than a code assistant.
Nerd Note: The real unlock is agent-native CLI/API ergonomics — once the entire DevOps lifecycle is addressable as code, the deployment loop collapses from hours to seconds.
English

When I built menugen ~1 year ago, I observed that the hardest part by far was not the code itself, it was the plethora of services you have to assemble like IKEA furniture to make it real, the DevOps: services, payments, auth, database, security, domain names, etc...
I am really looking forward to a day where I could simply tell my agent: "build menugen" (referencing the post) and it would just work. The whole thing up to the deployed web page. The agent would have to browse a number of services, read the docs, get all the api keys, make everything work, debug it in dev, and deploy to prod. This is the actually hard part, not the code itself. Or rather, the better way to think about it is that the entire DevOps lifecycle has to become code, in addition to the necessary sensors/actuators of the CLIs/APIs with agent-native ergonomics. And there should be no need to visit web pages, click buttons, or anything like that for the human.
It's easy to state, it's now just barely technically possible and expected to work maybe, but it definitely requires from-scratch re-design, work and thought. Very exciting direction!
Patrick Collison@patrickc
When @karpathy built MenuGen (karpathy.bearblog.dev/vibe-coding-me…), he said: "Vibe coding menugen was exhilarating and fun escapade as a local demo, but a bit of a painful slog as a deployed, real app. Building a modern app is a bit like assembling IKEA future. There are all these services, docs, API keys, configurations, dev/prod deployments, team and security features, rate limits, pricing tiers." We've all run into this issue when building with agents: you have to scurry off to establish accounts, clicking things in the browser as though it's the antediluvian days of 2023, in order to unblock its superintelligent progress. So we decided to build Stripe Projects to help agents instantly provision services from the CLI. For example, simply run: $ stripe projects add posthog/analytics And it'll create a PostHog account, get an API key, and (as needed) set up billing. Projects is launching today as a developer preview. You can register for access (we'll make it available to everyone soon) at projects.dev. We're also rolling out support for many new providers over the coming weeks. (Get in touch if you'd like to make your service available.) projects.dev
English
I built a security bot that you can't crash.
Not because it's bulletproof — because it heals itself when it breaks.
Here's the actual architecture:
↳ Supervisor loop catches every exception and restarts in 2 seconds ↳ Corrupt config? Backed up + regenerated automatically ↳ Config accidentally saved as a folder? Renamed + rebuilt without human input ↳ Adversarial test script attacks it intentionally — bot survives every time
The evaluator doesn't just run the bot. It injects real corruption, holds a file lock open, then mathematically verifies the crash → heal → recovery sequence happened in the correct order.
No AI smoke and mirrors. Just deterministic self-healing engineering.
Nerd Note: The test harness scores 6 deterministic criteria including sequence ordering validation — crash index must precede heal index, which must precede the first [ok] write. That's mathematical proof of recovery, not a vibe check.
Full breakdown drops soon. What's the hardest failure mode you've had to engineer around?
#BuildingInPublic #PracticalAI #AIAgents
English
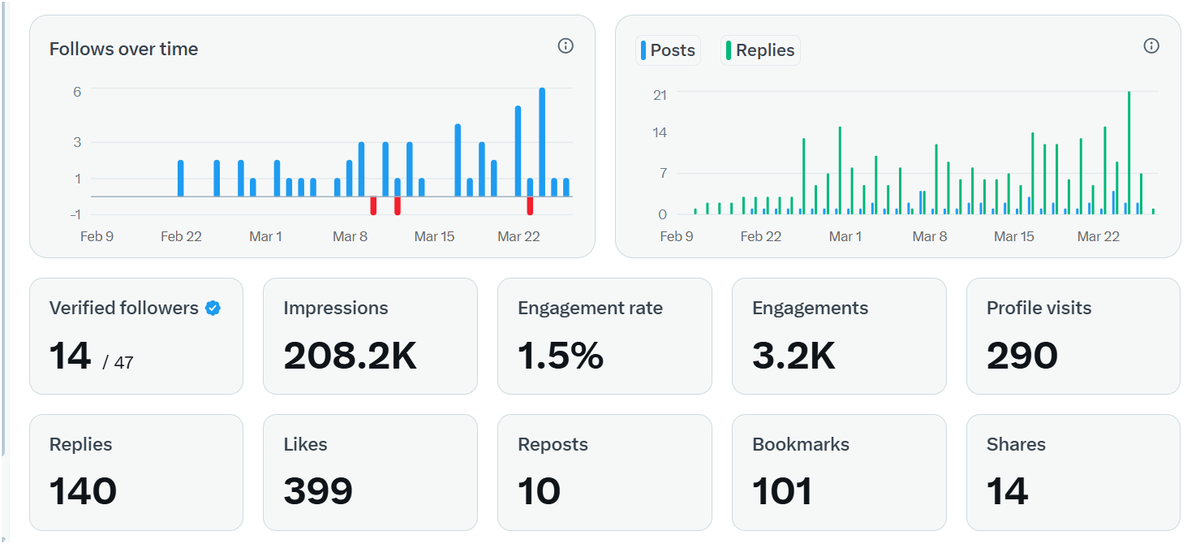
208,200 impressions. Under 50 followers. Day 44.
Here's what the data actually looks like when you build in public with zero audience:
↳ Impressions came from comments, not posts ↳ 101 bookmarks = people saving workflows, not just scrolling ↳ 1.5% engagement rate = above platform average for AI accounts ↳ Follower growth spiked only after consistent daily comments on large accounts
The algorithm doesn't care about your follower count. It cares about whether people stop scrolling.
😎Nerd Note: At sub-50 followers, impression-to-follower ratio above 1000:1 confirms distribution is reply-chain driven, not network-driven — which means Tweepcred borrowing is working exactly as intended.
Save this if you're building from zero. What metric surprised you most?
#BuildingInPublic #AIWorkflow #Practical
English
116 skills + 28 specialized agents in one repo just collapsed months of Claude Code setup into a single clone.
The structure is what's underrated — shorthand guide first, longform second, security last. That's the exact learning order most teams get wrong.
Nerd Note: The hooks + rules layer handles persistent context injection across the agent chain — that's what separates reliable multi-agent pipelines from brittle ones.
English
EVERYTHING CLAUDE CODE JUST OPEN SOURCED A FULL AI ENGINEERING SYSTEM.
28 agents, 116 skills, 59 commands, MCP integrations, hooks, rules, and even a built in security scanner.

English
100% human solvable. Under 1% for frontier AI. On first contact, no instructions.
That gap is the entire point of ARC-AGI-3.
The benchmark is specifically designed to test what humans do naturally that AI still cannot — adapt reasoning to a completely novel environment without any prior pattern to match against.
Every model that "passed" a previous benchmark did it by training on problems that looked like the test. ARC-AGI-3 closes that gap by design. First contact only. No prior exposure. No shortcuts.
Under 1% isn't a failure of current models. It's an honest measurement of where general reasoning actually stands right now.
Nerd Note: Interactive reasoning environments that require action efficiency — not just correct answers — measure a fundamentally different capability than static benchmarks. You can't brute-force action efficiency with token sampling.
English

ARC-AGI-3 is out now! We've designed the benchmark to evaluate agentic intelligence via interactive reasoning environments. Beating ARC-AGI-3 will be achieved when an AI system matches or exceeds human-level action efficiency on all environments, upon seeing them for the first time.
We've done extensive human testing that shows 100% of these environments are solvable by humans, upon first contact, with no prior training and no instructions.
Meanwhile, all frontier AI reasoning models do under 1% at this time.
English
Native Microsoft Teams integration is the one that matters most for enterprise adoption.
Every serious agent deployment eventually hits the same wall — the AI works great in the dev environment, then dies when it needs to live inside the tools the actual team uses daily. Slack, Teams, Discord aren't optional integrations. They're where the work happens.
Skill & tool management Control UI on top of that means you're not just deploying agents — you're managing them without touching the codebase every time something changes.
Any client. Any model. One runtime is doing a lot of work in four words.
Nerd Note: Sub-agent communication via the OpenAI API layer means OpenClaw is routing inter-agent messages through a standardized protocol rather than custom websocket logic — which is what makes the "any model" claim actually portable across providers.
English

OpenClaw 2026.3.24 🦞
🔌 Improved OpenAI API: talk to sub-agents with @openwebui
🎛️ Skill & tool management Control UI
🎨 Slack interactive reply buttons
💅 Native Microsoft Teams
🧵 Smart Discord auto-thread naming
Any client. Any model. One runtime. github.com/openclaw/openc…
English
MCP tools on mobile is the feature that changes how Claude fits into a real workday.
The use case that matters most: you're away from your desk, something breaks or needs a decision, and instead of waiting to get back to a laptop you pull Figma, Amplitude, or Canva directly through Claude on your phone and handle it in the moment.
The AI isn't just answering questions anymore. It's operating your actual work tools from wherever you are.
Nerd Note: Mobile MCP access means the context window now has live tool state on a device with no persistent background processes — the entire session has to be stateless and reconstructed on each interaction, which makes reliable tool chaining significantly harder to implement cleanly than on desktop.
English

Your work tools in Claude are now available on mobile.
Explore Figma designs, create Canva slides, check Amplitude dashboards, all from your phone.
Give it a try: claude.com/download
English
The visual says more than the caption does.
No hierarchy. No clean pyramid. Just a web of connected constraints pulling toward a single center point.
That's an honest representation of how behavioral alignment actually works — not a rulebook with clear chapters, but competing principles that all have to stay in tension simultaneously.
The hard part isn't defining what the model should do. It's what happens when two correct principles point in opposite directions at the same time.
Nerd Note: A constraint satisfaction architecture for model behavior is fundamentally different from a rule-based one — you're not checking a list, you're finding the output that minimally violates the most constraints simultaneously.
English

More on our approach to the Model Spec: openai.com/index/our-appr…
English
The more AI can do, the more we need to ask what it should and shouldn’t do.
OpenAI researcher @w01fe joins host @AndrewMayne to explore the Model Spec, the public framework that defines how models are intended to behave.
They break down how it works in practice, from the chain of command that resolves conflicting instructions to the way it evolves over time through real-world use, feedback, and new model capabilities.
English
The Model Spec solving conflicting instructions through a chain of command is the part most people miss.
It's not just "here are the rules." It's a priority stack — when a user instruction conflicts with an operator instruction conflicts with a core principle, the model has a defined resolution order.
That architecture is what separates a model that behaves consistently in production from one that breaks unpredictably at edge cases.
The fact that it evolves through real-world feedback means the spec is essentially a living document trained on failure modes.
Nerd Note: A publicly documented behavioral priority stack is also the only credible answer to the alignment auditing problem — you can't verify a model's values without a written spec to check actual behavior against.
English
This framing makes the fix harder than it looks.
If the bias is baked in at training time — models learning to treat in-context content as high-signal by default — then filtering what gets RAG'd into memory only solves half the problem.
The model will still overweight whatever does make it in. The retrieval layer gets smarter but the attention bias stays.
The actual fix probably needs to happen during training: teaching the model to treat memory-retrieved context with lower default confidence than present-conversation context.
Nerd Note: This is structurally similar to how retrieval-augmented models can hallucinate by over-trusting retrieved passages — the model wasn't trained to be skeptical of its own context window, so it isn't.
English
(I cycle through all LLMs over time and all of them seem to do this so it's not any particular implementation but something deeper, e.g. maybe during training, a lot of the information in the context window is relevant to the task, so the LLMs develop a bias to use what is given, then at test time overfit to anything that happens to RAG its way there via a memory feature (?))
English
One common issue with personalization in all LLMs is how distracting memory seems to be for the models. A single question from 2 months ago about some topic can keep coming up as some kind of a deep interest of mine with undue mentions in perpetuity. Some kind of trying too hard.
English
Memory that overfits to a single data point is worse than no memory at all.
The model treats one question as a permanent personality trait. You asked about Rust once — now every response assumes you're writing systems software. It's not personalization, it's pattern-matching with no decay function.
What actually helps is recency-weighted memory with explicit expiry. One question from 2 months ago should carry near-zero weight by now.
Nerd Note: This is essentially the same problem as overfitting in ML — the model memorizes noise instead of learning signal. Useful personalization requires forgetting old data points as aggressively as it learns new ones.
English
I tested 3 frontier LLMs against 1 AI Agent
on a messy real-world audio task.
The 3 LLMs — Claude 4.6 Sonnet, GPT-5.3,
Gemini 3.1 Pro — all failed or got partial credit.
The Agent — Manus 1.6 Lite — nailed it.
Same file. Same prompt. Completely different
architecture. Completely different result.
Here's exactly what happened and why 👇
─────────────────────────
THE TEST
A screen recording of a person speaking
over background music.
Halfway through, the music suddenly swells loud.
Task: Identify the exact song AND the singer.
Claude 4.6 Sonnet | GPT-5.3 |
Gemini 3.1 Pro | Manus 1.6 Lite
─────────────────────────
THE RESULTS
❌ Claude 4.6 Sonnet — couldn't even open the file
❌ GPT-5.3 — couldn't even open the file
⚠️ Gemini 3.1 Pro — got the singer correctly,
completely missed the song
✅ Manus 1.6 Lite — exact song name + exact singer.
100% correct.
─────────────────────────
WHY CLAUDE & GPT-5.3 FAILED
This wasn't an intelligence failure.
It was a pipeline failure.
LLM chat interfaces have strict limits
on video codecs and file formats.
If the input isn't perfectly optimized,
the intake system rejects it before
the model ever sees the file.
This is the exact failure mode that
benchmarks never test for.
─────────────────────────
WHY GEMINI GOT CLOSE BUT STILL FAILED
Gemini 3.1 Pro has native multimodal
audio processing.
It actually heard the file and correctly
identified the singer.
But it couldn't isolate the exact song.
Why? The classic cocktail party problem.
Speech + music playing at the same time =
the model tries to process both as one
single waveform.
The acoustic signature of the track gets
buried under the voice.
Gemini listens like a human in a noisy room.
Impressive… but not enough.
─────────────────────────
WHY THE AGENT WON
Manus 1.6 Lite isn't smarter than Gemini 3.1 Pro.
It won because of architecture.
LLMs are brains in a jar.
Agents are brains with hands.
When Manus failed the first pass,
it didn't guess. It didn't hallucinate.
It completely changed strategy:
→ Extracted only the clean audio track from the video
→ Found the exact timestamp where music swelled loudest
→ Isolated that 10-second window
→ Ran it through a dedicated audio recognition API
→ Matched against a song database
→ Returned a verified result
LLMs answer once and stop.
Agents iterate until the answer is confirmed.
─────────────────────────
THE REAL LESSON
This test wasn't really about audio processing.
It was about architecture.
A screen recording is chaotic input —
video + speech + music + shifting audio levels.
LLMs try to process the entire messy context
at once and get overwhelmed.
Agents modularize the problem:
"Ignore the video. Ignore the speech.
Extract 0:15–0:25. Analyze only that."
That's not a smarter model.
That's a better problem-solving structure.
Raw intelligence has a ceiling.
Agentic workflows don't.
The future of AI isn't bigger models.
It's better architecture.
─────────────────────────
Nerd Note: The cocktail party problem in
multimodal audio is an acoustic source
separation failure — models without dedicated
signal isolation layers treat mixed audio
as a single waveform, making frequency-level
track identification unreliable when speech
and music overlap above ~-12dB relative amplitude.
Save this if you test AI tools in the real world.
Which model would you have bet on
before seeing the results? Drop it below.
#AIWorkflow #LLMBenchmark #PracticalAI
English