Ehco
2.6K posts










这应该是今天我最重要的信息转发。 我们可能做错了 AI Agent 的长期记忆系统。 最近 arXiv 上的新论文《Useful Memories Become Faulty When Continuously Updated by LLMs》揭露了一个极其残酷的现实: 你让 Agent 越努力去复盘和总结经验,它反而变得越蠢。 现在业界流行让 Agent 在运行中做 Memory Consolidation,把原始日志抽象成通用规则存起来。但实验表明,随着流式更新的深入,LLM 在反复重写记忆时,会不可避免地引入信息失真和错误累积。 最夸张的案例:在 ARC-AGI 任务里,原本没有记忆时模型能 100% 完美解决;但只要让它基于自己完全正确的历史轨迹去连续增量总结,准确率竟然暴跌到 54%!模型在自我反思的过程中,硬生生把自己给绕晕了。 看完论文我的几点工程思考: 1.原始情节记忆(Raw Episodic Memory)被严重低估了。 很多时候,直接把原始交互 Trace 作为 Few-shot 塞给 Prompt,效果完胜那些经过模型精简、看似高大上的规则库。 2.拒绝盲目实时更新。 鲁棒的 Agent 架构应该把原始情节视为第一手铁证,引入显式的门控机制,只有在非必要不整合。 3.异质任务必须隔离。 绝对不要把不同任务的经验混在一个批次里让 LLM 做增量总结,异质数据会加速记忆崩溃。 这篇论文的作者之中,来自@Tsinghua_Uni 交叉信息研究院的Zhengkun Wu是我最好的朋友之一,目前他在UIUC进行春研。我们相识已久,他是个很聪明并且创新性想法很多的人,在我的朋友里,他独特且有个人魅力。和他交流进步,我感到十分荣幸且开心。 祝愿他的科研、学习之路顺利!

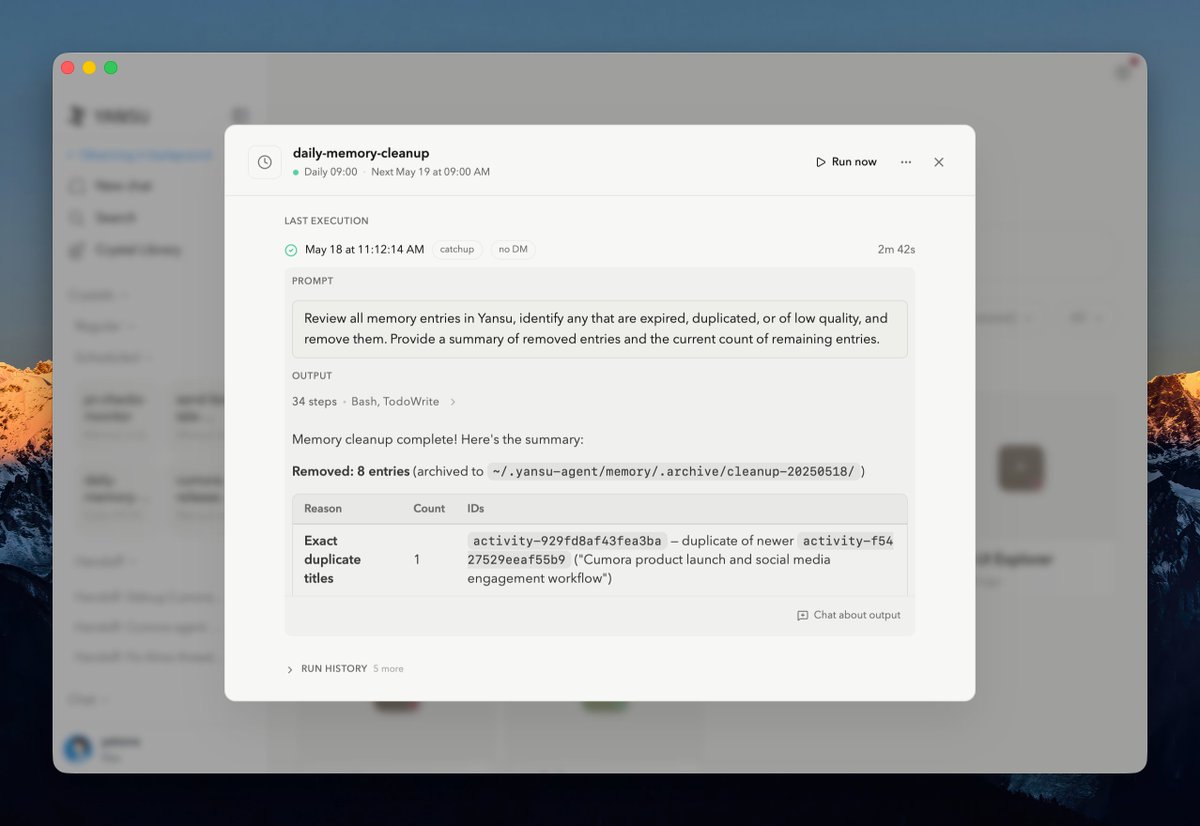
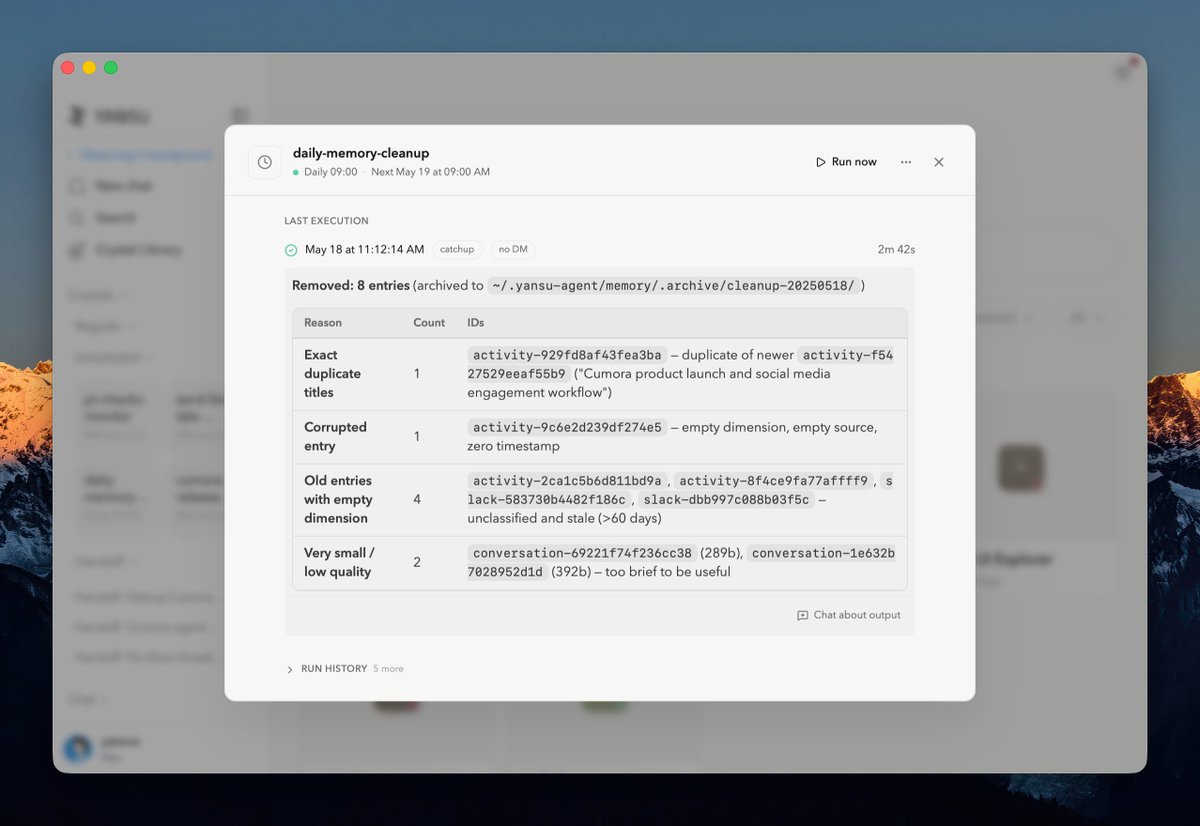
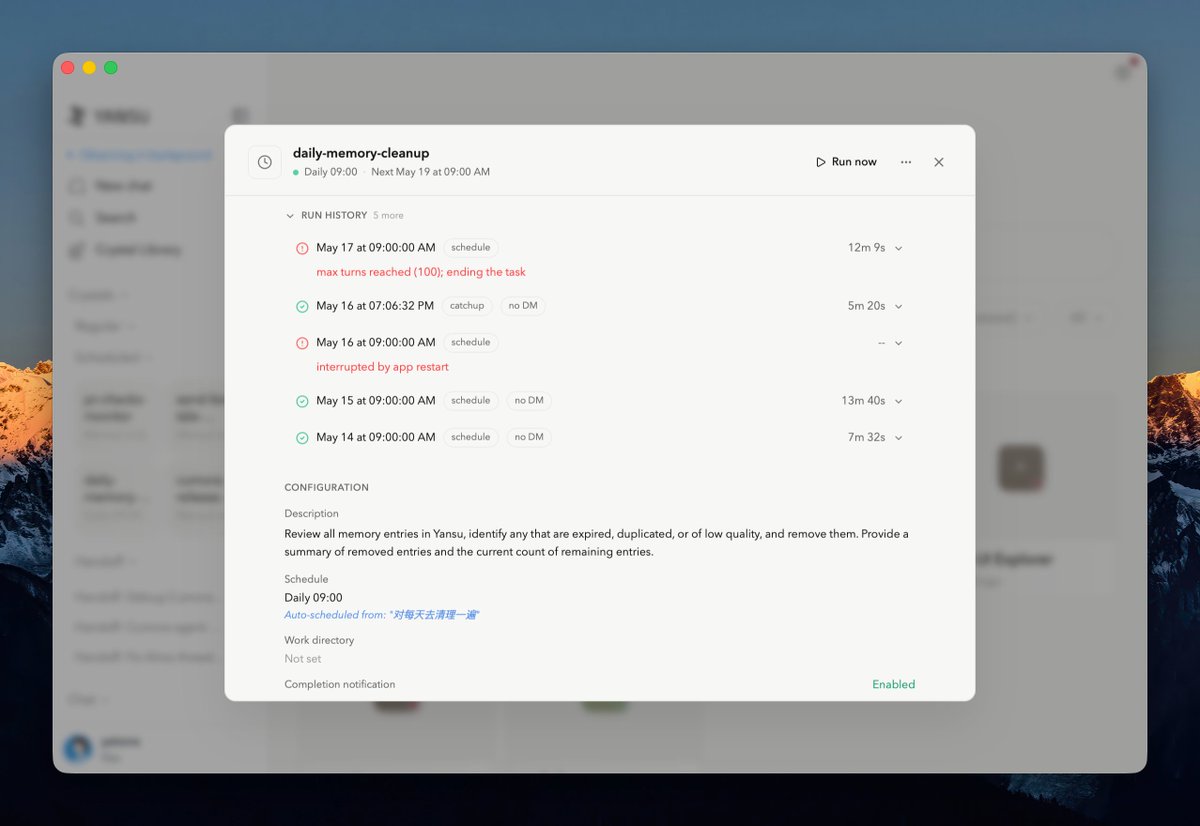
说起我们的 Yansu App 的真实案例,不得不提 Yansu 的 Hand-off 功能,最近发生了两个特别好玩的事情: 首先,我们的 CEO Bo @bozhao 最近在准备旅行,Yansu 看到这个信息之后,主动向 Bo 发出了一个 Hand-off 的消息提醒,说想要帮他去调研目的地的 Airbnb 房源。Bo 点击确认后,它果然给出了一个质量特别高的房源推荐列表。 Bo 是个英文用户,但最后 Yansu 是用中文总结的。Bo 问它:「你为什么用中文总结?」最后发现是因为在它做 Hand-off 之前,Bo 刚跟我们开了一个全中文的会议,所以它就延用了中文进行总结。 这件事情还没完。在这之后 Bo 刷推看到了我现在引用的这条推文,他就想把上面这个案例给分享出来,有意思的是,Yansu 紧接着就发起了一个新的 Hand-off,问道:「是否需要我把 Yansu 的这个案例推文帮你写出来?」,Bo 点击 ok 后,Yansu 一气呵成写出了推文。 这两件事情真的震惊了我们。




最终还是为我的 Remote Agents 写了个 distribution file system 来同步 Memory, Notes, Skills。 现在我的 k8s pod based Agent Remote Computer 的冷启动速度也变得很快了,虽然这所有都是我用力拽着 Harness 实现的,但是之前这么多年的相关经验的积累还是派上了用场。 所以我不知道以后没有技术背景的人能否去做类似的这种架构有些许复杂度且第一天就要保证 Scaling 优先的工程化项目。

我现在感觉agent 基于file based 的memory 系统还是太脆弱了 应该有个db based的,这样天然就分布式加可扩展,但是这个事情可能要做到预/后训练里才会有比较好等效果🤔 现在有个折中的办法是基于 db/s3 实现 fake fs ,但还是不够干净

DB base 和 file base,在 harness memory 系统中不是冲突的。只是 firstly 和 secondly 的区别。一切都是为了照顾 LLM 的喜好。至少在 2026 年,LLM 还仍然是个 Bash 爱好者。 这也是为什么大多数当代 Harness 都是多层记忆,我们的 Harness Memory 也是多层的,有基于 embedding db 的记忆,也有基于 file system 记忆。

Introducing Mirage, a unified virtual filesystem for AI agents! 6 weeks. 1.1M+ lines of code. We rewrote bash from the ground up so cat, grep, head, and pipes work across heterogeneous services. S3, Google Drive, Slack, Gmail, GitHub, Linear, Notion, Postgres, MongoDB, SSH, and more, all mounted side-by-side as one filesystem. Bash that AI agents already know works on every format! cat, grep, head, and wc parse .parquet, .csv, .json, .h5, even .wav! One pipe can stitch S3, Drive, GitHub, Slack, and Linear together, same Unix semantics throughout. Workspaces are versioned too. Snapshot, clone, and roll back the whole thing with one API call. A two-layer cache turns repeated reads into local lookups, so agent loops stay fast and cheap. Drop a Workspace into FastAPI, Express, or a browser app. Wire it into OpenAI Agents SDK, Vercel AI SDK, LangChain, Mastra, or Pi. Run it alongside Claude Code and Codex. Site: strukto.ai/mirage GitHub: github.com/strukto-ai/mir… #AIAgents #OpenSource #AgenticAI #Strukto #Filesystem #VFS