Sabitlenmiş Tweet
Enigma
4.7K posts


Enigma
@Enigma_ZA
Easy going Technology, Design and Football enthusiast// I am open to networking with the world // Learning how to build and sell better //Aspiring Polymath //
South Africa Katılım Temmuz 2019
5.1K Takip Edilen430 Takipçiler
Enigma retweetledi

Robotics with MATLAB
Intro to robotics with a strong focus on learning by doing.
You use simulations and animations to understand how robots work, while the math builds intuition step by step.
The course shows how to write code for robot physics, control systems, and motion using MATLAB.
Includes tutorials, example code, and a YouTube playlist for guided learning.
📍 pab47.github.io/robotics.html
——
Weekly robotics and AI insights.
Subscribe free: 22astronauts.com

English
Enigma retweetledi

1.Download Obsidian → create a new vault (folder)
2.Download Claude Desktop (Claude Code)
3.Point Claude to the path of your vault
4.Paste the prompt from the article
> Just 4 steps and 10 minutes of your time
The face I made when I realized I had been suffering all this time, not knowing such simple things
Defileo🔮@defileo
English
Enigma retweetledi

This 15-minute talk by the creator of Pydantic on how to correctly use MCPs will
teach you more about making your AI tools actually work together than everything you've scrolled past this year.
Bookmark this & watch, no matter what.
Then read the guide below by @eng_khairallah1
Khairallah AL-Awady@eng_khairallah1
English
Enigma retweetledi

This 2 hour Stanford lecture shows exactly how Stanford trains it's engineers to build AI systems. It's more practical than every Claude tutorial & prompting threads you've seen.
Bookmark & give it 2 hours, no matter what. It'll be the most productive thing you do this weekend.
English
Enigma retweetledi

Programming drones with AI is a great way to learn about computer vision and automation.
In this course, @beaucarnes helps you program a drone using Python and complete missions in a simulator.
You’ll learn about 3D movement, computer vision, gesture control, and autonomous navigation.
freecodecamp.org/news/master-ai…

English
Enigma retweetledi

30 Agents Every AI Engineer Must Build — Build production-ready agent systems using proven architectures and patterns: amzn.to/41ckg6z v/ @PacktDataML
—
What you will learn:
1️⃣Deploy production-ready agent systems that scale securely and reliably
2️⃣Use LangChain and LangGraph to build autonomous agents with modular architectures
3️⃣Implement agents with sophisticated memory, planning, and reasoning capabilities
4️⃣Seamlessly integrate tools, APIs, and external data into agent workflows
5️⃣Establish robust evaluation frameworks to measure and optimize agent performance
6️⃣Implement guardrails and explainability features to ensure ethical and safe deployment
7️⃣Build multi-agent systems for complex, collaborative task orchestration
8️⃣Apply specific agent architectures across healthcare, finance, and legal domains

English
Enigma retweetledi

Is context engineering the new RAG?
(Hint: They are both about 𝗯𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝘁𝗵𝗲 𝗟𝗟𝗠’𝘀 𝗰𝗼𝗻𝘁𝗲𝘅𝘁)
𝗥𝗔𝗚 (𝟮𝟬𝟮𝟬-𝟮𝟬𝟮𝟯): One-shot retrieval
• Fixed retrieval pipelie
• Always retrieve context (whether you need it or not)
• Retrieve exactly once (even if you need more info)
𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚 (𝟮𝟬𝟮𝟯-𝟮𝟬𝟮𝟰): Multi-hop retrieval through tool usage
• Retrieval becomes a tool the agent can choose to use
• Agent decides: Do I need to retrieve? Is this context even relevant? Do I need more?
• Can route to different indexes
𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝘀𝗲𝗮𝗿𝗰𝗵 𝗶𝗻 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 (𝟮𝟬𝟮𝟱+): Combine multiple retrieval tools for context engineering
• Context is scattered across different context sources (database, filesystem, web, memory)
• Combine different context retrieval tools
• Agent builds its own context
Essentially, we’ve moved from ‘retrieve once’ to ‘the agent builds its own context’.
Yesterday, I gave a workshop on this topic.
Find the slides and code on this in my GitHub repo:
github.com/iamleonie/work…

English
Enigma retweetledi

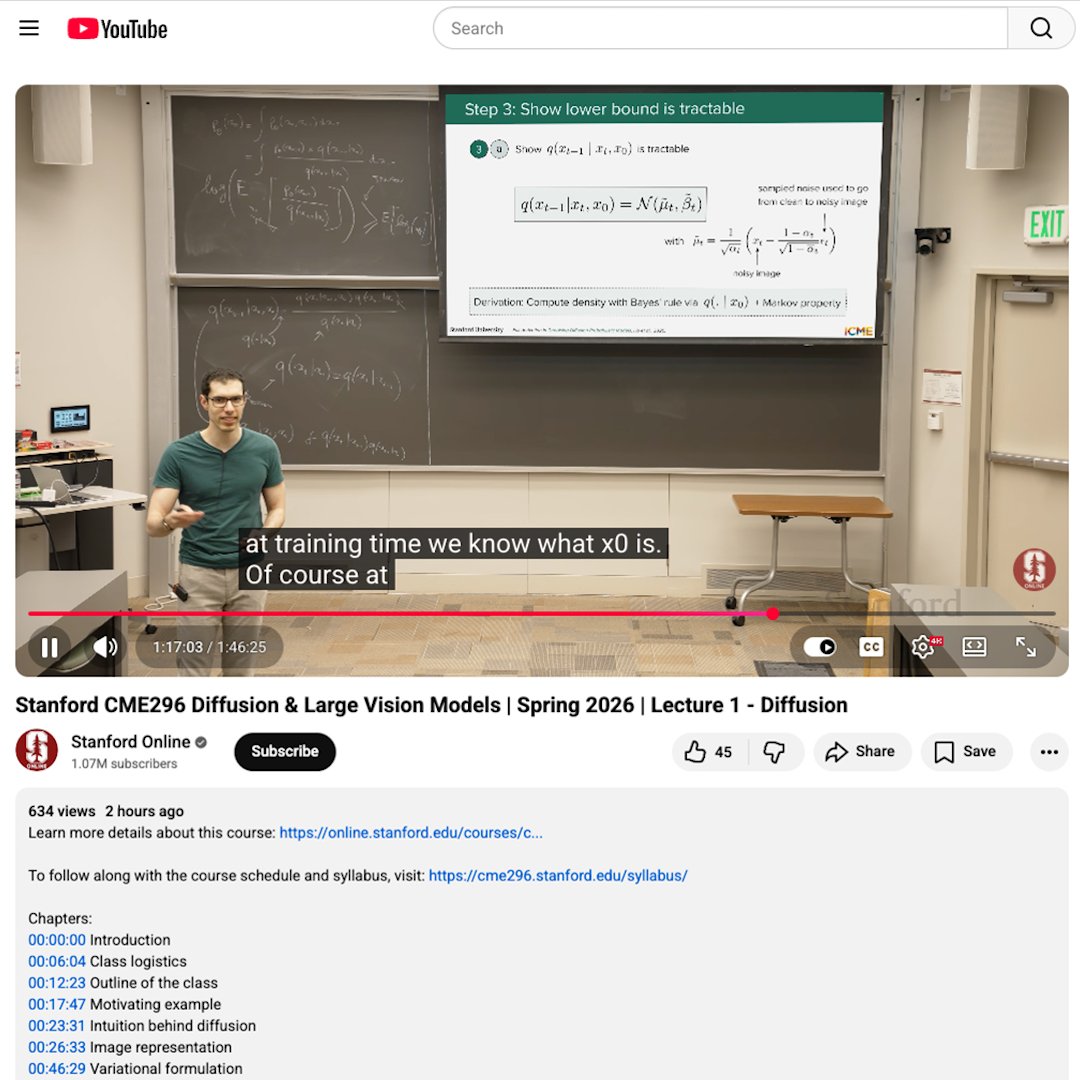
Our new Stanford class "CME 296: Diffusion & Large Vision Models" is now available on YouTube!
English
Enigma retweetledi


Enigma retweetledi

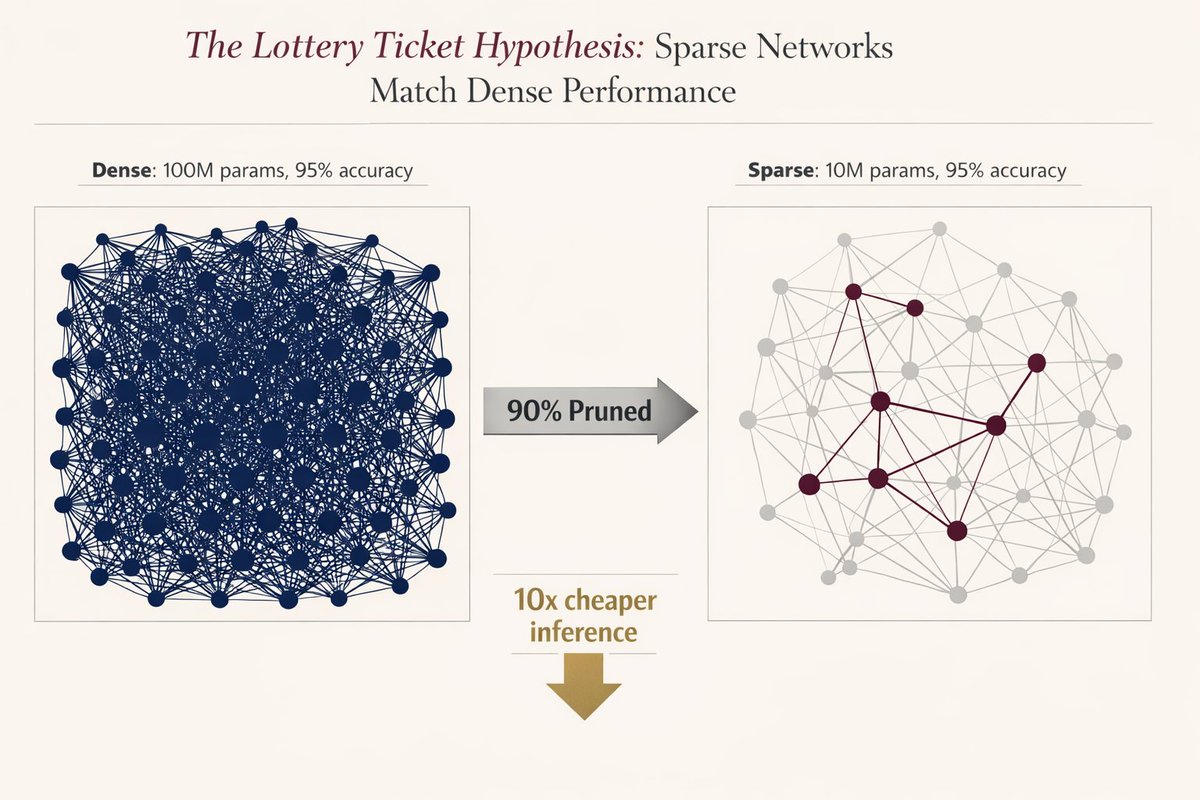
🚨 MIT proved you can delete 90% of a neural network without losing accuracy.
Researchers found that inside every massive model, there is a "winning ticket”, a tiny subnetwork that does all the heavy lifting.
They proved if you find it and reset it to its original state, it performs exactly like the giant version.
But there was a catch that killed adoption instantly..
you had to train the massive model first to find the ticket. nobody wanted to train twice just to deploy once. it was a cool academic flex, but useless for production.
The original 2018 paper was mind-blowing:
But today, after 8 years…
We finally have the silicon-level breakthrough we were waiting for: structured sparsity.
Modern GPUs (NVIDIA Ampere+) don’t just “simulate” pruning anymore.
They have native support for block sparsity (2:4 patterns) built directly into the hardware.
It’s not theoretical, it’s silicon-level acceleration.
The math is terrifyingly good: a 90% sparse network = 50% less memory bandwidth + 2× compute throughput. Real speed.. zero accuracy loss.
Three things just made this production-ready in 2026:
- pruning-aware training (you train sparse from day one)
- native support in pytorch 2.0 and the apple neural engine
- the realization that ai models are 90% redundant by design
Evolution over-parameterizes everything. We’re finally learning how to prune.
The era of bloated, inefficient models is officially over. The tooling finally caught up to the theory, and the winners are going to be the ones who stop paying for 90% of weights they don’t even need.
The future of AI is smaller, faster, and smarter.
English
Enigma retweetledi

🚨BREAKING: Google just dropped Google skills.
A new platform where anyone can learn ai, coding, and tech from scratch with certificates.
Here is everything you need to know:
English
Enigma retweetledi
A full MIT course on visual autonomous navigation.
If you work on robotics, drones, or self-driving systems, this one is worth bookmarking‼️
MIT’s Visual Navigation for Autonomous Vehicles course covers the full perception-to-control stack, not just isolated algorithms.
What it focuses on:
• 2D and 3D vision for navigation
• Visual and visual-inertial odometry for state estimation
• Place recognition and SLAM for localization and mapping
• Trajectory optimization for motion planning
• Learning-based perception in geometric settings
All material is available publicly, including slides and notes.
📍vnav.mit.edu
If you know other solid resources on vision-based autonomy, feel free to share them.
——
Weekly robotics and AI insights.
Subscribe free: 22astronauts.com

English
Enigma retweetledi

This is Algebrica. A mathematical knowledge base I’ve been building for 2.5 years.
215+ entries, carefully written and structured.
400k+ views over this time. Not much in absolute terms, but meaningful to me.
No ads.
No courses to sell.
No gamification.
No distractions.
Just essential pages, aiming to explain mathematics as clearly as possible, for a university-level audience.
Built simply for the pleasure of sharing knowledge.
Content licensed under Creative Commons (BY-NC).
Best experienced on desktop.
If it helps even a few people understand something better, it’s worth it.

English
Enigma retweetledi

Every team at your company should be creating their own 'Team OS' in Claude Code on Github. Here's how:
1:45 - What is a Team OS
13:37 - Shared skills and commands
25:24 - Shared team automations
59:50 - The learning flywheel
English
Enigma retweetledi

In 2013, Nassim Taleb gave a 53-min Stanford masterclass on why chaos makes some businesses stronger.
His ideas:
- The coffee cup that survives 4 million hits
- Why helicopter engineers ride their own machines
- The country where nobody knows the president
12 lessons on risk:
English
Enigma retweetledi
The only roadmap you’ll ever need to become an Agentic AI Engineer in 2026 ✨
drive.google.com/file/d/1mQWpRq…

English
Enigma retweetledi
wanted to learn Arduino but had no hardware
turns out you don't need it
Velxio runs Arduino, ESP32, Raspberry Pi, and RISC-V code directly in your browser.... real emulation
48+ components. no install. no account. completely free
velxio.dev
the hardware excuse is gone
English
Enigma retweetledi


Enigma retweetledi

STANFORD UNIVERSITY compressed the entire field of LLMs and transformers into free cheatsheets anyone can use today.
It covers everything from self-attention to Flash Attention, LoRA, SFT, MoE, distillation, quantization, RAG, agents, and LLM-as-a-judge.
100% Free and Open Source

English
Enigma retweetledi

My friend Milla Jovovich and I spent months creating an AI memory system with Claude. It just posted a perfect score on the standard benchmark - beating every product in the space, free or paid.
It's called MemPalace, and it works nothing like anything else out there.
Instead of sending your data to a background agent in the cloud, it mines your conversations locally and organizes them into a palace - a structured architecture with wings, halls, and rooms that mirrors how human memory actually works.
Here is what that gets you:
→ Your AI knows who you are before you type a single word - family, projects, preferences, loaded in ~120 tokens
→ Palace architecture organizes memories by domain and type - not a flat list of facts, a navigable structure
→ Semantic search across months of conversations finds the answer in position 1 or 2
→ AAAK compression fits your entire life context into 120 tokens - 30x lossless compression any LLM reads natively
→ Contradiction detection catches wrong names, wrong pronouns, wrong ages before you ever see them
The benchmarks:
100% recall on LongMemEval — first perfect score ever recorded. 500/500 questions. Every question type at 100%.
92.9% on ConvoMem — more than 2x Mem0's score.
100% on LoCoMo — every multi-hop reasoning category, including temporal inference which stumps most systems.
No API key. No cloud. No subscription. One dependency. Runs on your machine. Your memories never leave.
MIT License. 100% Open Source.
github.com/milla-jovovich…

English