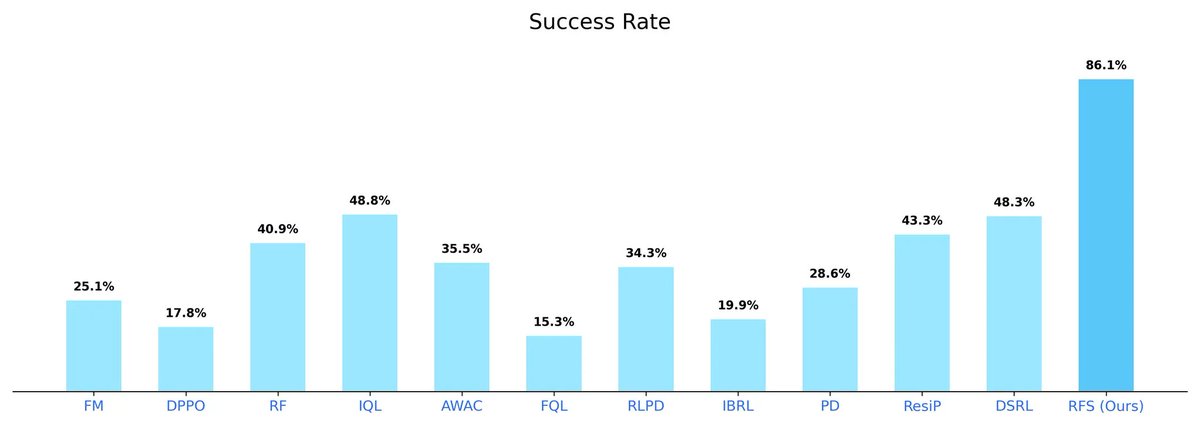
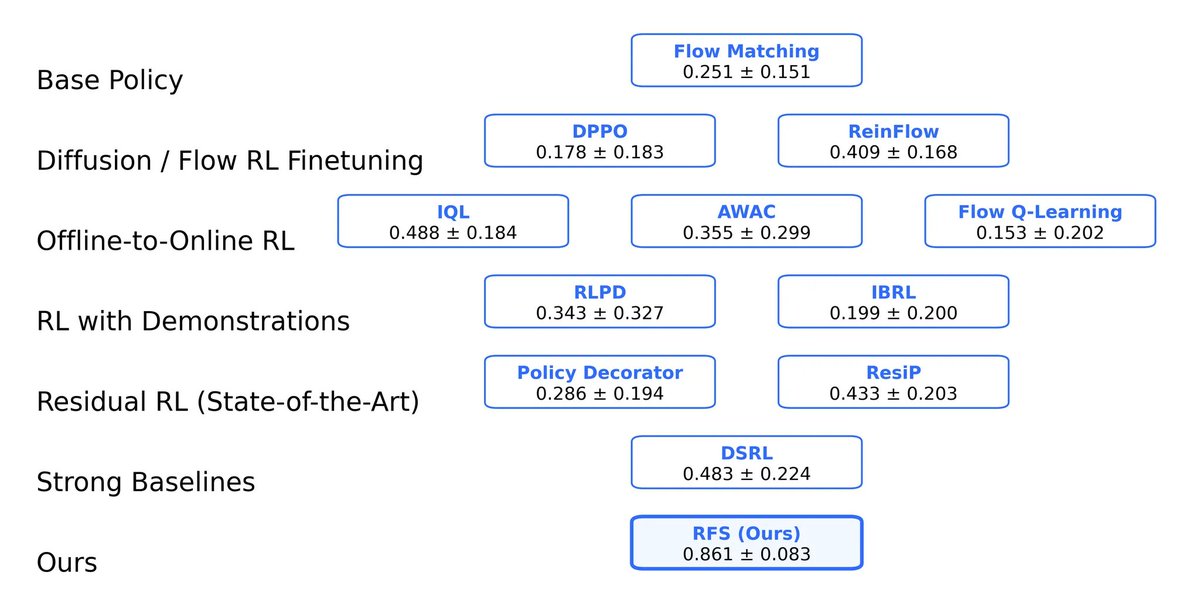
Sabitlenmiş Tweet

Pretrained diffusion/flow policies are powerful — but brittle at deployment.
We introduce RFS, a data-efficient RL framework that:
• steers latent noise for global adaptation
• applies residual actions for precise local correction
Works in sim and real-world dexterous manipulation 🖐️🤖
👉📄 Paper + videos: entongsu.github.io/rfs/
English