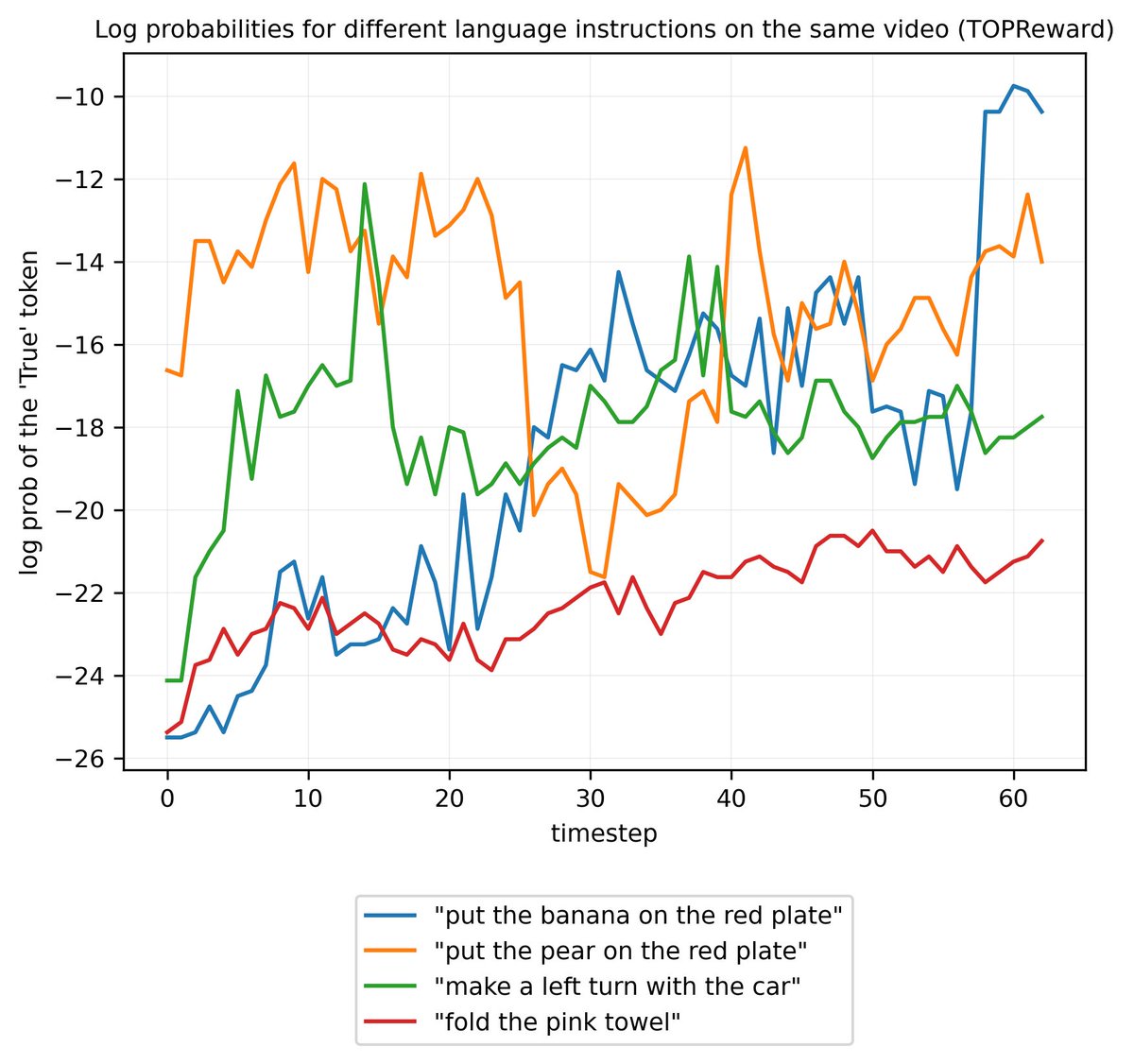
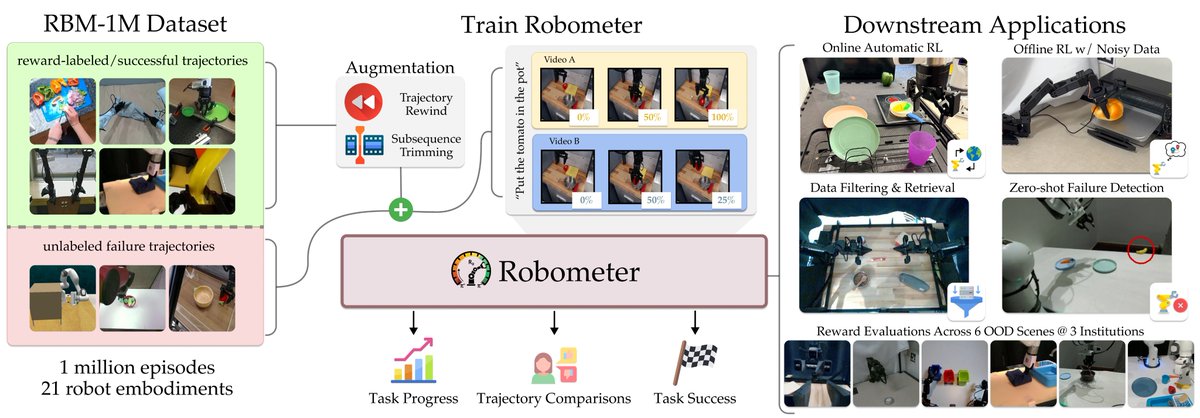
Sabitlenmiş Tweet

There’s a discussion going on rn about two recent robotic reward models: TOPReward⛰️ and Robometer🌡️
Which one is better? It depends entirely on your objective!
Here is a deep dive into the conceptual differences, strengths, and weaknesses of both. 🧵👇

English