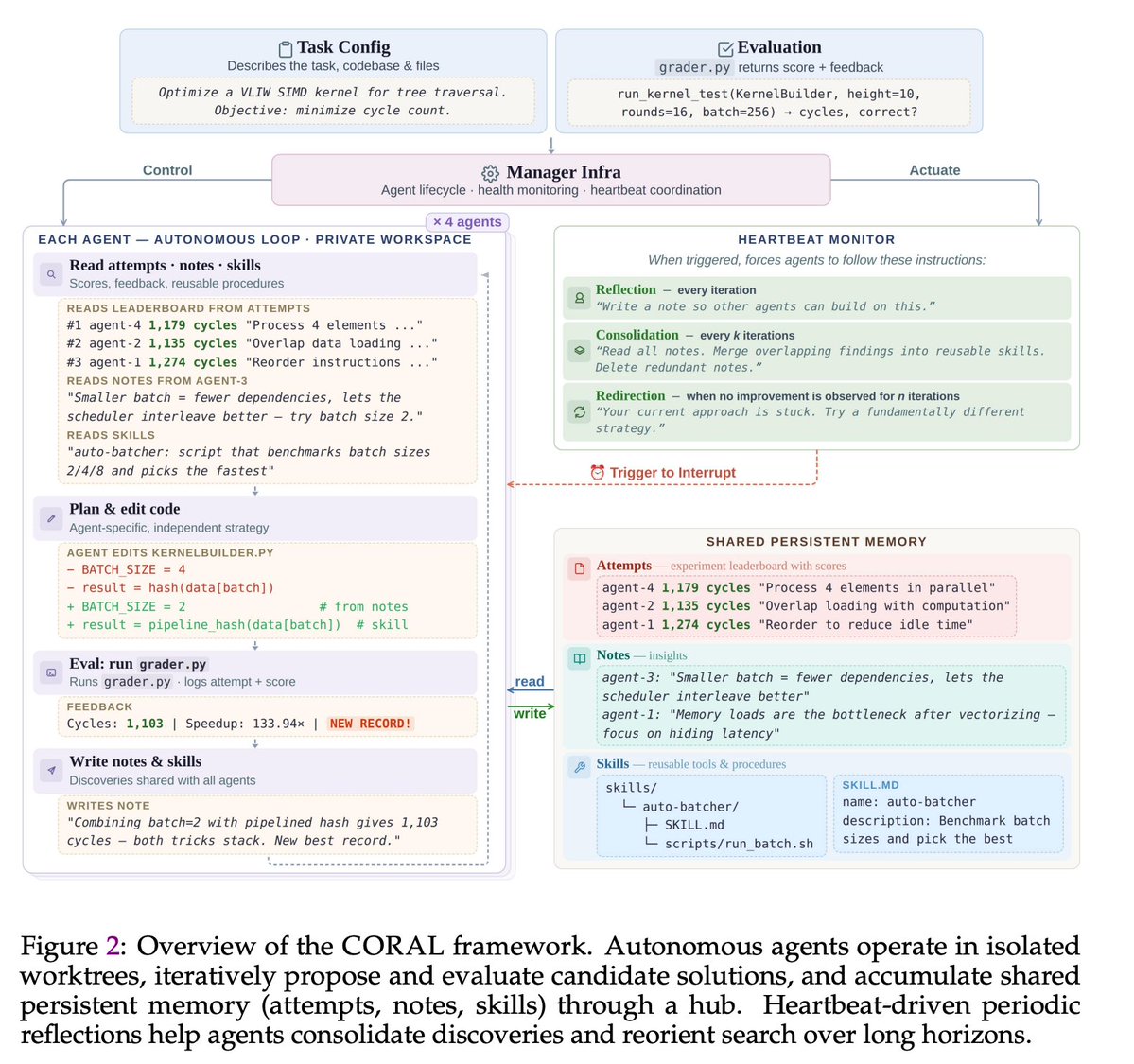
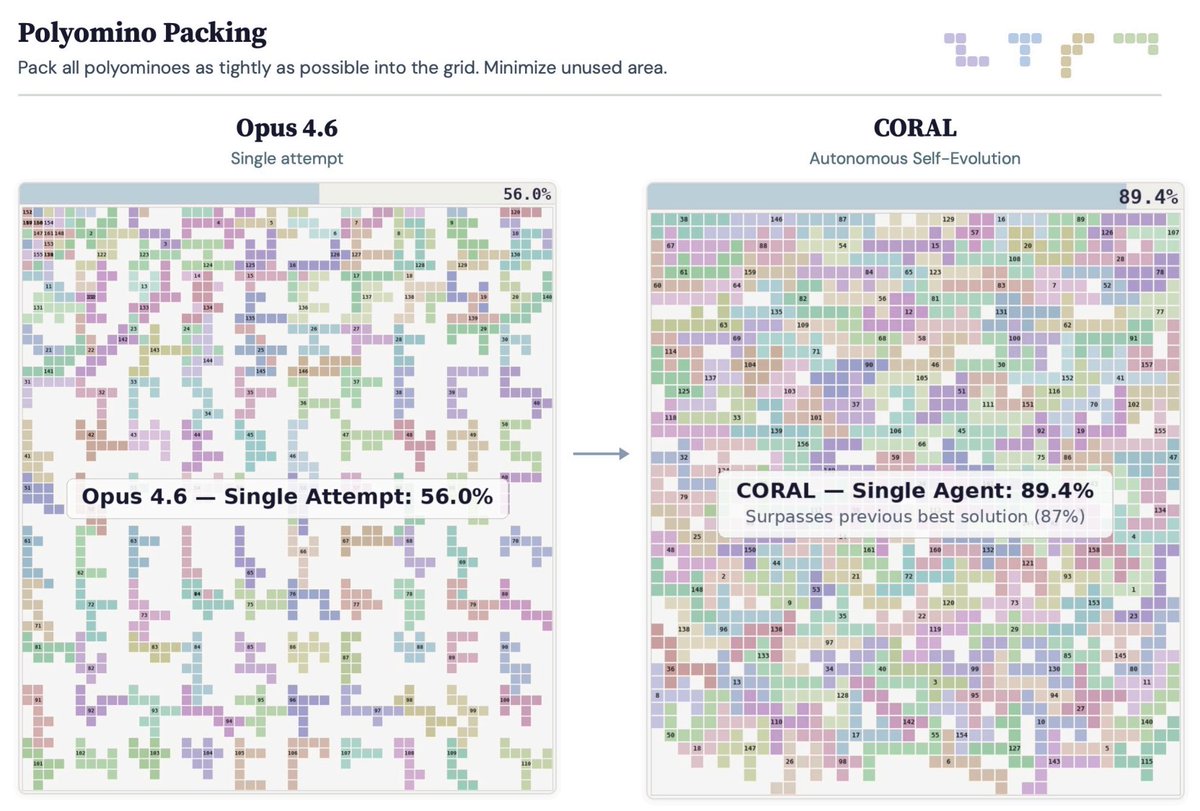
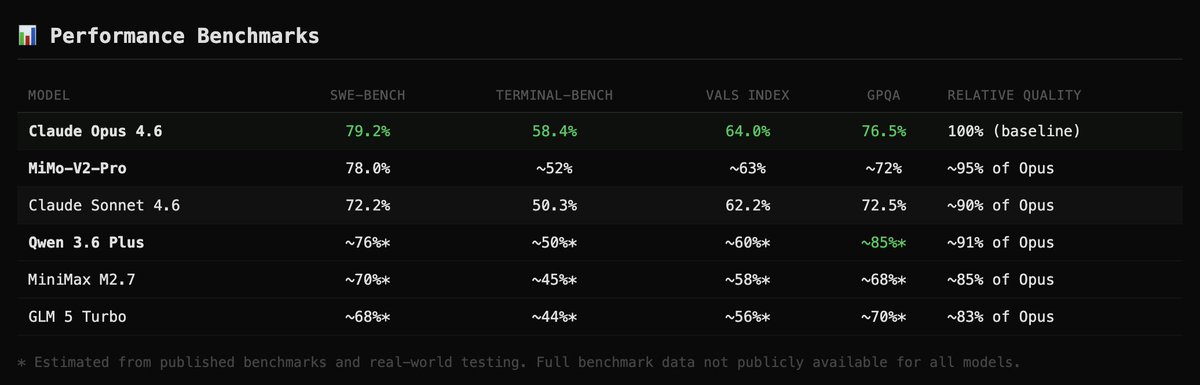
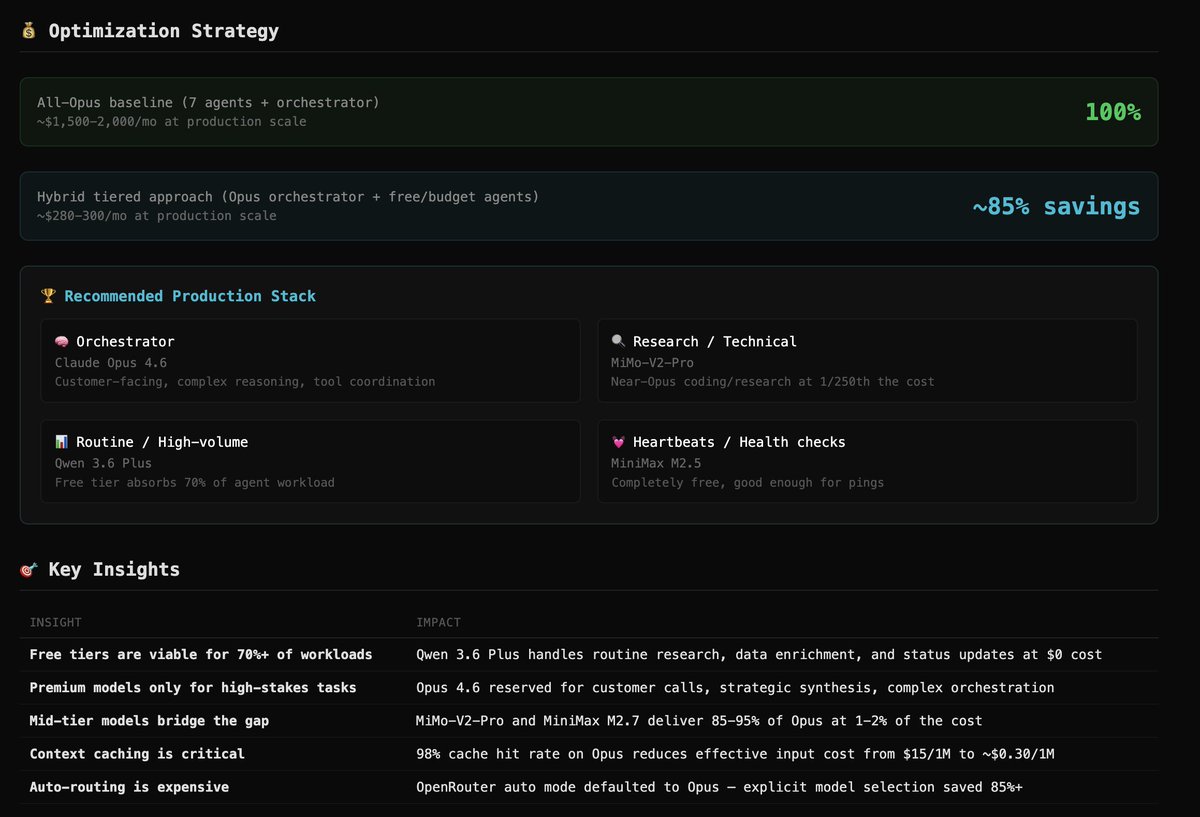
Sabitlenmiş Tweet

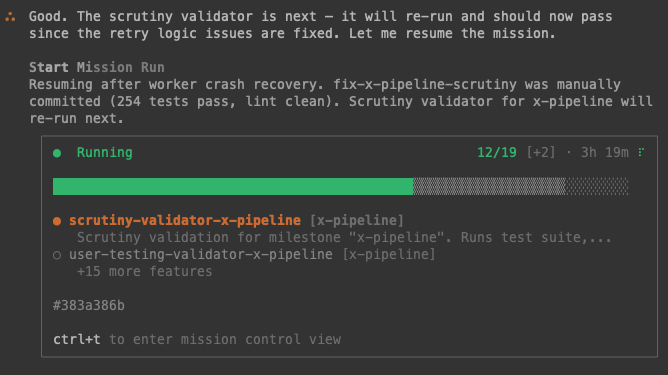
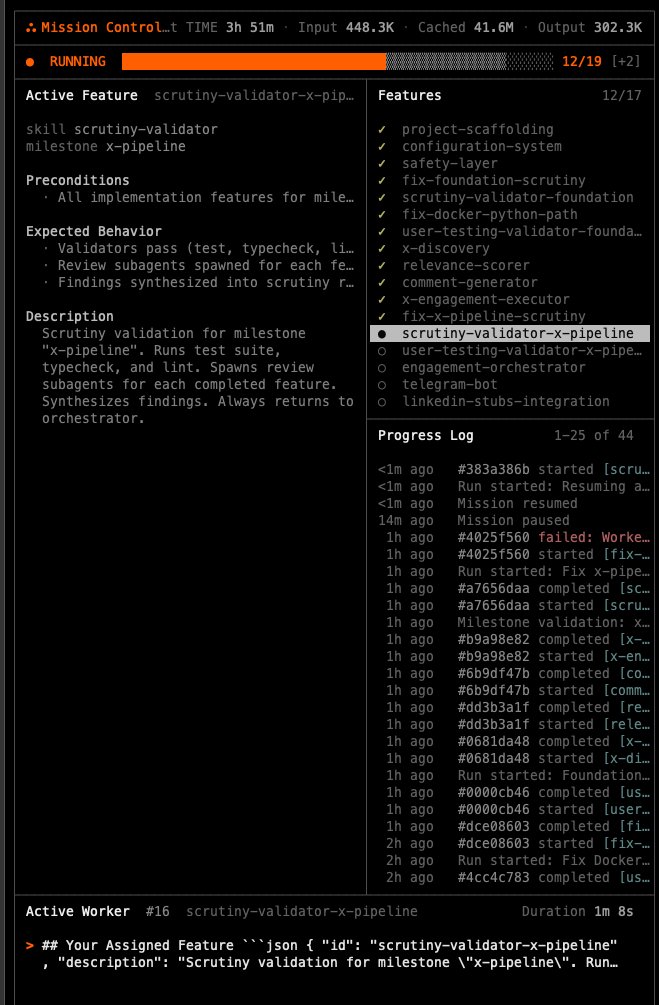
Just spent the last 10hrs building an intelligent knowledge base system that automatically captures everything I code, think, and learn without me lifting a finger.
Quite wild, if you ask me. 🤯
Using Basic Memory MCP server + Claude Code + Obsidian for the ultimate dev knowledge graph.
This changed how I work. Here's how 🧵


English